Bias-Variance Tradeoff(权衡偏差与方差)
2018-03-05 20:45
369 查看
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;噪声则表达了学习问题本省的难度。偏差-方差分解说明,泛化能力是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的,给定学习任务,为了取得好的泛化性能,需使偏差较小,即能够充分拟合数据,并使方差较小,使数据扰动产生的影响最小。
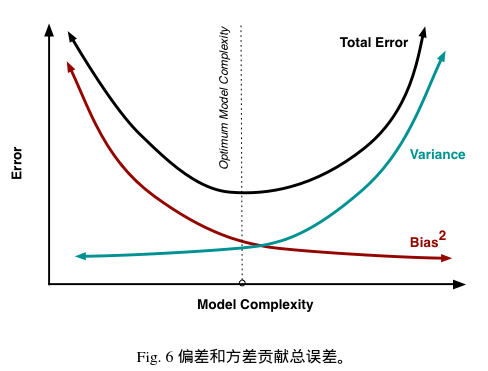
在一个实际系统中,Bias与Variance往往是不能兼得的。如果要降低模型的Bias,就一定程度上会提高模型的Variance,反之亦然。造成这种现象的根本原因是,我们总是希望试图用有限训练样本去估计无限的真实数据。当我们更加相信这些数据的真实性,而忽视对模型的先验知识,就会尽量保证模型在训练样本上的准确度,这样可以减少模型的Bias。但是,这样学习到的模型,很可能会失去一定的泛化能力,从而造成过拟合,降低模型在真实数据上的表现,增加模型的不确定性。相反,如果更加相信我们对于模型的先验知识,在学习模型的过程中对模型增加更多的限制,就可以降低模型的variance,提高模型的稳定性,但也会使模型的Bias增大。Bias与Variance两者之间的trade-off是机器学习的基本主题之一,机会可以在各种机器模型中发现它的影子。
这个方法将帮助我们获得模型关于泛化误差(generalization error)的可信的估计,所谓的泛化误差也即模型在新数据集上的表现。在训练数据上面,我们可以进行交叉验证(Cross-Validation)。
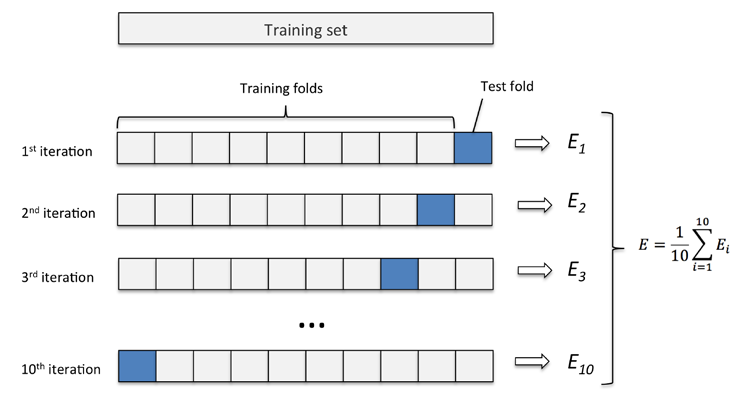
K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,、我们便可获得 k 个模型及其性能评价。平均K次的结果或者使用其它结合方式,最终得到一个单一估测。当K值大的时候, 我们会有更少的Bias(偏差), 更多的Variance。
当K值小的时候, 我们会有更多的Bias(偏差), 更少的Variance。下图展示了 k=10 时的 k-fold 方法的工作流程。
在一个实际系统中,Bias与Variance往往是不能兼得的。如果要降低模型的Bias,就一定程度上会提高模型的Variance,反之亦然。造成这种现象的根本原因是,我们总是希望试图用有限训练样本去估计无限的真实数据。当我们更加相信这些数据的真实性,而忽视对模型的先验知识,就会尽量保证模型在训练样本上的准确度,这样可以减少模型的Bias。但是,这样学习到的模型,很可能会失去一定的泛化能力,从而造成过拟合,降低模型在真实数据上的表现,增加模型的不确定性。相反,如果更加相信我们对于模型的先验知识,在学习模型的过程中对模型增加更多的限制,就可以降低模型的variance,提高模型的稳定性,但也会使模型的Bias增大。Bias与Variance两者之间的trade-off是机器学习的基本主题之一,机会可以在各种机器模型中发现它的影子。
权衡偏差与方差:
模型过于简单时,容易发生欠拟合(high bias);模型过于复杂时,又容易发生过拟合(high variance)。为了达到一个合理的 bias-variance 的平衡,此时需要对模型进行认真地评估。这里简单介绍一个有用的cross-validation技术K-fold Cross Validation (K折交叉验证),这个方法将帮助我们获得模型关于泛化误差(generalization error)的可信的估计,所谓的泛化误差也即模型在新数据集上的表现。在训练数据上面,我们可以进行交叉验证(Cross-Validation)。
K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,、我们便可获得 k 个模型及其性能评价。平均K次的结果或者使用其它结合方式,最终得到一个单一估测。当K值大的时候, 我们会有更少的Bias(偏差), 更多的Variance。
当K值小的时候, 我们会有更多的Bias(偏差), 更少的Variance。下图展示了 k=10 时的 k-fold 方法的工作流程。

相关文章推荐
- 机器学习算法中的偏差-方差权衡(Bias-Variance Tradeoff)
- Bias-Variance Tradeoff(权衡偏差与方差)
- 机器学习算法中的偏差-方差权衡(Bias-Variance Tradeoff)
- 偏差-方差权衡(Bias-Variance Tradeoff)
- 机器学习方差和偏差权衡(Understanding the Bias-Variance Tradeoff)
- 偏见方差的权衡(Bias Variance Tradeoff)
- 方差和偏差(Understanding the Bias-Variance Tradeoff)
- 机器学习理论知识部分--偏差方差平衡(bias-variance tradeoff)
- 偏差(Bias)-方差(Variance)权衡(tradeoff)
- 偏差、方差的权衡(trade-off)
- 方差与偏差的权衡(trade-off)
- Bias Variance Tradeoff
- 机器学习中的偏差(Bias)与方差(Variance)
- CalTech machine learning video 8 note(Bias-Variance Tradeoff)
- 机器学习中的偏差(bias)和方差(variance)
- 总结:Bias(偏差),Error(误差),Variance(方差)及CV(交叉验证)
- 机器学习——偏差(bias),方差(variance),噪声(noise)
- 机器学习中的误差(Error)、偏差(Bias)与方差(Variance)
- 模型的偏差bias以及方差variance
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?