论文Recurrent Convolutional Neural Networks for Text Classification的实验部分
2018-03-05 11:43
169 查看
使用的基本模型结构:
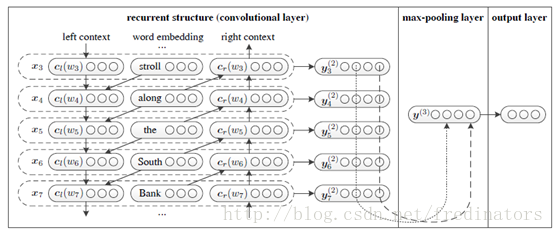
实验
实验中使用了四个数据集。
20Newsgroups:qwone.com/˜jason/20Newsgroups/
数据集包含20个新闻组的信息,我们使用日期版本并选择四种主要类别(综合,政治,娱乐和宗教)
Fudan set:2www.datatang.com/data/44139 and 43543
复旦大学文件分类集合是一个中文文件分类集合,包含20个分类,包括艺术教育和能源。
ACL Anthology Network:old-site.clsp.jhu.edu/˜sbergsma/Stylo/
该数据集包含了由ACL和相关组织发布的科学文献。它由五种语言注解:英语,日语,德语,中文和法语。
Stanford Sentiment Treebank:nlp.stanford.edu/sentiment/
这个数据集包含了电影评论解析,和五种标签:非常消极,消极,中立,积极,非常积极。
实验设置
对于英文文件,使用Stanford Tokenizer来获取令牌(nlp.stanford.edu/software/tokenizer.shtml)。对于中文文件,使用ICTCLAS来分词(ictclas.nlpir.org)。
不移除文本中的任何stop words或符号。所有的四个数据集被事先分为训练集和测试集
神经网络的超参数设置取决于使用的数据集。选择先前学习中的一系列常见的超参数。此外,设置随机梯度下降的学习率为 =0.01,隐层的大小为H=100,词嵌入的向量大小为|e|=50.上下文向量的大小为|c|=50.使用word2vec中(使用的Skip-gram算法:code.google.com/p/word2vec)的默认参数训练词嵌入。用英文和中文的维基百科转储来训练单词嵌入。
方法
Bag of Words/Bigrams + LR/SVM
文本分类的基准主要使用单词或双词作为特征的机器学习算法。
分别使用LR和SVM(www.csie.ntu.edu.tw/˜cjlin/liblinear),每个特征的权重为术语出现的频率。
Average Embedding + LR
这个基准使用词嵌入的平均权重,随后应用到一个softmax层。每个单词的权重是它词频-逆向文件频率的值(http://www.cnblogs.com/sddai/p/5660181.html)。
LDA
在集中分类任务中,基于LDA的方法能够较好捕获文本的语义。我们选择两种方法用于比较:ClassifyLDA-EM和Labeled-LDA。
Tree Kernels
使用各种tree kernel作为特征,是ACL母语分类任务中最先进的工作。列举两个主要方法用以比较:the context-free grammar (CFG) produced by the Berkeley parser (Petrov et al. 2006) and the reranking feature set of Charniak and Johnson (2005) (C&J).
RecursiveNN
我们使用两种递归结构比较:the Recursive Neural Network (RecursiveNN) (Socher et al. 2011a) 和它的改进版本 the Recursive Neural Tensor Networks (RNTNs)。
CNN
选择卷积神经网络用于比较。它的卷积内核只是简单的级联了预定义窗口大小的词嵌入。
结果和讨论
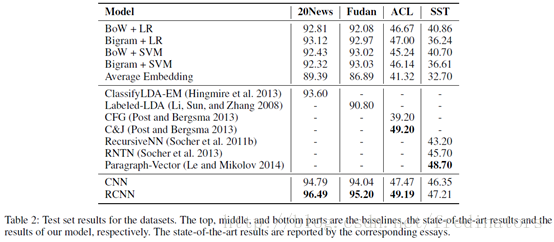
RCNN使用一个循环结构能够捕获更广的上下文信息。相较于其他模型更为出色。
实验
实验中使用了四个数据集。
20Newsgroups:qwone.com/˜jason/20Newsgroups/
数据集包含20个新闻组的信息,我们使用日期版本并选择四种主要类别(综合,政治,娱乐和宗教)
Fudan set:2www.datatang.com/data/44139 and 43543
复旦大学文件分类集合是一个中文文件分类集合,包含20个分类,包括艺术教育和能源。
ACL Anthology Network:old-site.clsp.jhu.edu/˜sbergsma/Stylo/
该数据集包含了由ACL和相关组织发布的科学文献。它由五种语言注解:英语,日语,德语,中文和法语。
Stanford Sentiment Treebank:nlp.stanford.edu/sentiment/
这个数据集包含了电影评论解析,和五种标签:非常消极,消极,中立,积极,非常积极。
实验设置
对于英文文件,使用Stanford Tokenizer来获取令牌(nlp.stanford.edu/software/tokenizer.shtml)。对于中文文件,使用ICTCLAS来分词(ictclas.nlpir.org)。
不移除文本中的任何stop words或符号。所有的四个数据集被事先分为训练集和测试集
神经网络的超参数设置取决于使用的数据集。选择先前学习中的一系列常见的超参数。此外,设置随机梯度下降的学习率为 =0.01,隐层的大小为H=100,词嵌入的向量大小为|e|=50.上下文向量的大小为|c|=50.使用word2vec中(使用的Skip-gram算法:code.google.com/p/word2vec)的默认参数训练词嵌入。用英文和中文的维基百科转储来训练单词嵌入。
方法
Bag of Words/Bigrams + LR/SVM
文本分类的基准主要使用单词或双词作为特征的机器学习算法。
分别使用LR和SVM(www.csie.ntu.edu.tw/˜cjlin/liblinear),每个特征的权重为术语出现的频率。
Average Embedding + LR
这个基准使用词嵌入的平均权重,随后应用到一个softmax层。每个单词的权重是它词频-逆向文件频率的值(http://www.cnblogs.com/sddai/p/5660181.html)。
LDA
在集中分类任务中,基于LDA的方法能够较好捕获文本的语义。我们选择两种方法用于比较:ClassifyLDA-EM和Labeled-LDA。
Tree Kernels
使用各种tree kernel作为特征,是ACL母语分类任务中最先进的工作。列举两个主要方法用以比较:the context-free grammar (CFG) produced by the Berkeley parser (Petrov et al. 2006) and the reranking feature set of Charniak and Johnson (2005) (C&J).
RecursiveNN
我们使用两种递归结构比较:the Recursive Neural Network (RecursiveNN) (Socher et al. 2011a) 和它的改进版本 the Recursive Neural Tensor Networks (RNTNs)。
CNN
选择卷积神经网络用于比较。它的卷积内核只是简单的级联了预定义窗口大小的词嵌入。
结果和讨论
RCNN使用一个循环结构能够捕获更广的上下文信息。相较于其他模型更为出色。

相关文章推荐
- 路由部分综合大实验
- nios II--实验6——串口软件部分
- Ch2r_ood_understanding 本文档为论文限定领域口语对话系统中超出领域话语的对话行为识别的部分实验代码。代码基于Python,需要用到的外部库有: Keras(搭建神经网络) S
- NetworkIPC之初识Client-Server实验部分(五)
- nios II--实验7——数码管IP硬件部分
- 网络学习(二)VMware Workstation7虚拟机使用前介绍及部分实验成果展
- 信号之后续实验部分(二)
- CCNP之BSCI部分实验1:EIGRP基本配置和邻接
- 实验部分类的代码
- nios II--实验7——数码管IP软件部分
- 剖析使用物理端口建立的BGP关系(实验部分)
- 《算法竞赛入门经典》(第2版)第一章 部分实验题
- 2013=12=3 数据库实验七 数据控制实验(完整性部分)
- 论文Sequential Short-Text Classification with Recurrent and Convolutional Neural Networks 的实验部分
- 实验 5.2.8-3 对文件的任意部分加锁 1. 用 fcntl()对文件进行锁操作。 2. 完善课件中的示例程序,给出程序运行结果及分析。 给b.txt中的前10个字节加写锁
- 语法分析实验部分简易版
- Red Hat Linux 033 实验部分
- ucore操作系统lab2实验报告之理论部分
- nios II--实验1——hello_world硬件部分