pandas常用函数使用备忘
2018-03-02 15:11
337 查看
http://pandas.pydata.org/pandas-docs/stable/index.html
pandas官方文档
Drop columns
Drop a row by index
Sort by col1
DataFrame.drop_duplicates(subset=None, keep=’first’, inplace=False)
subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列
keep : {‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项
inplace :默认为 False ,保留一个副本
True 是在原来数据上修改
pandas官方文档
>>> df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A', 'B', 'C', 'D']) >>> df A B C D 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11
Drop columns
>>> df.drop(['B', 'C'], axis=1) A D 0 0 3 1 4 7 2 8 11
>>> df.drop(columns=['B', 'C']) A D 0 0 3 1 4 7 2 8 11
Drop a row by index
>>> df.drop([0, 1]) A B C D 2 8 9 10 11
>>> df = pd.DataFrame({
... 'col1' : ['A', 'A', 'B', np.nan, 'D', 'C'],
... 'col2' : [2, 1, 9, 8, 7, 4],
... 'col3': [0, 1, 9, 4, 2, 3],
... })
>>> df
col1 col2 col3
0 A 2 0
1 A 1 1
2 B 9 9
3 NaN 8 4
4 D 7 2
5 C 4 3Sort by col1
>>> df.sort_values(by=['col1']) col1 col2 col3 0 A 2 0 1 A 1 1 2 B 9 9 5 C 4 3 4 D 7 2 3 NaN 8 4
DataFrame.drop_duplicates(subset=None, keep=’first’, inplace=False)
subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列
keep : {‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项
inplace :默认为 False ,保留一个副本
True 是在原来数据上修改
df = pd.DataFrame({'a': [4,4,5,6],
'b': [7,7,8,9],
'c': [10,10,11,12]},index=['a','b','c','d'])
df.drop_duplicates(inplace=True) #在原数据上修改df = pd.DataFrame({'A': [4,4,5,6], 'B': [7,7,8,9], 'C': [10,10,11,12]},index=['a','b','c','d'])
A B C
a 4 7 10
b 4 7 10
c 5 8 11
d 6 9 12
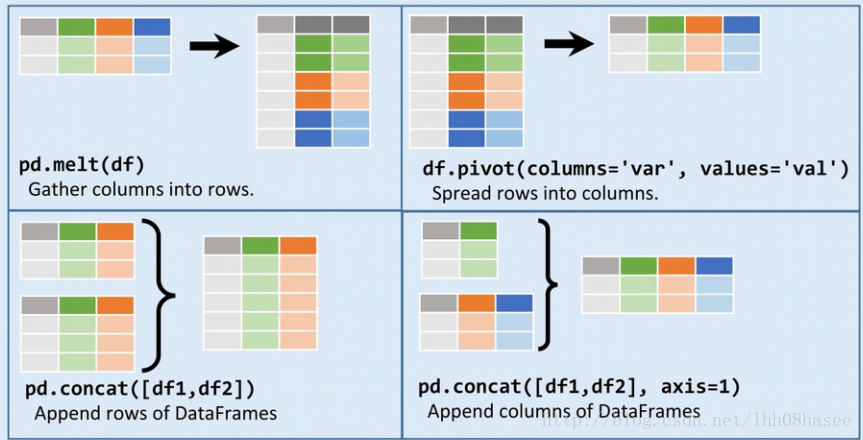
df1 = pd.melt(df) #把列的数据移到行上
variable value
0 A 4
1 A 4
2 A 5
3 A 6
4 B 7
5 B 7
6 B 8
7 B 9
8 C 10
9 C 10
10 C 11
11 C 12
df2 = df.reset_index() #把行索引,复制当成一列
index A B C
0 a 4 7 10
1 b 4 7 10
2 c 5 8 11
3 d 6 9 12
a = df.sort_values(by='C', ascending=False) #对C那一列,排序由高到低,True为由低到高
b = df.drop('a') #删除行索引'a'的那行
A B C
d 6 9 12
c 5 8 11
a 4 7 10
b 4 7 10df数据: A B C a 4 7 10 b 4 7 10 c 5 8 11 d 6 9 12 df.loc['a'] #通过行标签索引行数据 A 4 B 7 C 10 df.iloc[2] #通过行号索引行数据 A 5 B 8 C 11 df.ix['a'] #通过行标签或者行号索引行数据(基于loc和iloc 的混合) A 4 B 7 C 10 df.ix[:,'A'] #索引A 那一列 a 4 b 4 c 5 d 6

相关文章推荐
- C++常用字符串处理函数及使用示例
- ASP.NET 程序设计中常用到的一些通用函数 自己的封装 可以做成dll来使用。
- 常用oracle函数使用实例
- 常用函数使用:
- JS 操作IE游览器常用函数使用说明
- ajax 常用函数和类的使用
- 常用网络命令(备忘使用)
- php常用函数使用示例
- 【转帖】C语言的常用库函数使用方法分析及用途
- oracle常用函数使用大全
- perl 常用函数(2)-可供查阅使用
- 常用的对话框函数使用方法
- Ajax常用的几个函数及Alexa查询的几个查询接口及使用方法
- C++常用字符串处理函数及使用示例(ASCII)
- DataGrid使用小结(二)——常用函数方法
- 常用的对话框函数使用
- C++常用字符串处理函数及使用示例
- 使用C#创建webservice及三种调用方式 (ASP.NETweb编程常用到的27个函数集)
- 常用的oracle函数使用说明(二)
- [备忘]Printf和Scan函数使用细节大披露