网易云课堂吴恩达Andrew Ng深度学习笔记(三)
2018-03-02 00:01
232 查看
01.神经网络和深度学习
第三周 浅层神经网络
上一周的课程讲解了单神经元的正向及反向传播推导公式及向量化。
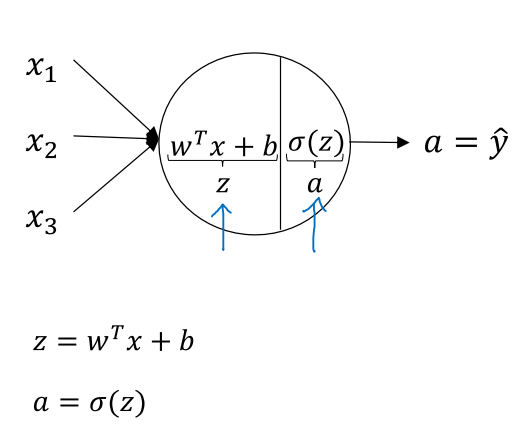
一个神经元内部的操作分为两步:第一步是输入特征的线性组合,第二步是将z通过激活函数进行非线性变化得到a,也就是对y的拟合。先沿着正向计算损伤函数L(a,y),再反向计算梯度,沿着dw下降方向来调整参数w = w - α*dw。
这里介绍一个典型的2层神经网络,第1层有4个神经元,第二层有1个神经元。

每个节点都在执行相同的操作

按照向量化的思想,把变量堆积成行变量可以把计算合并
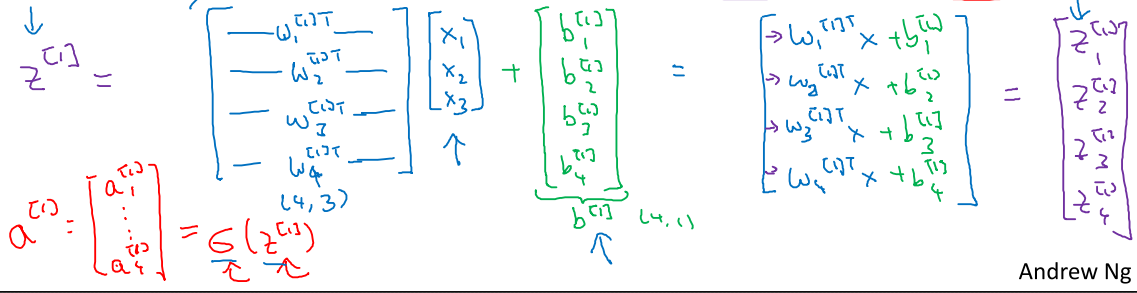

向量化后每层w维度为[此层神经元个数,输入特征个数],b维度为[此层神经元个数,1]
维持等式左右维度相等,a[1] = w[1]*a[0] + b[1]。图示神经网络是[4,1] = [4,3]*[3,1]+[4,1]
第一层的结果a[1]作为第二层的输入。
上面说明的是单示例输入的情况,在真实环境下会有x[1],x[2],x[3]...x[m],每一个示例都可以计算一个a[2]
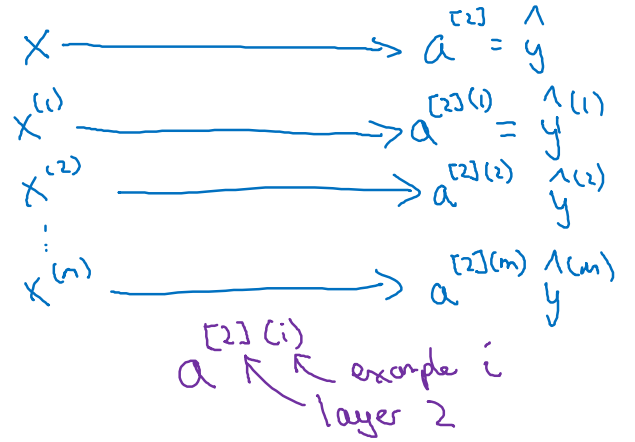
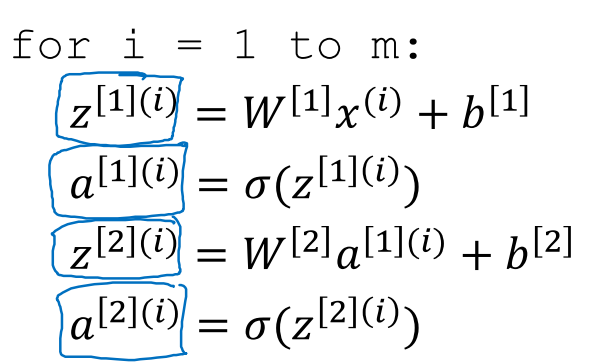
在向量化操作中,将每个示例作为一列,合并成矩阵,列数即为训练样本的个数
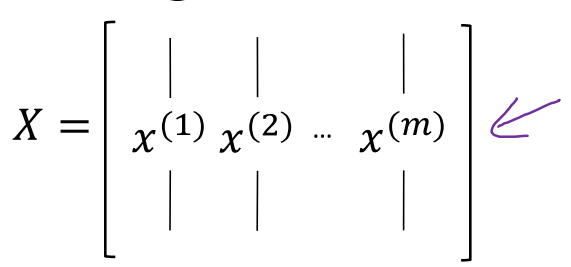
同理,中间每层的输出a[1],a[2]也合并组成矩阵

整个求解过程可以向量化,在多示例向量化的过程中,W和b不变化,和单示例保持一致

就下来说明激活函数,并不限于我们前面求解过程假设的sigmoid函数
sigmoid函数在实际使用中很少,除了在输出层,可以将最后的输出限定在[0,1],常见于二分类问题。
其有个变体函数tanh函数,对比两者的形状


sigmoid函数范围的[0,1],tanh函数将其零点位置拉低到x=0位置,这利于数据的中心化,让下一层的学习更加容易。
而吴老师推荐的是ReLU(Rectified Linear Unit)函数及其变体Leak ReLU
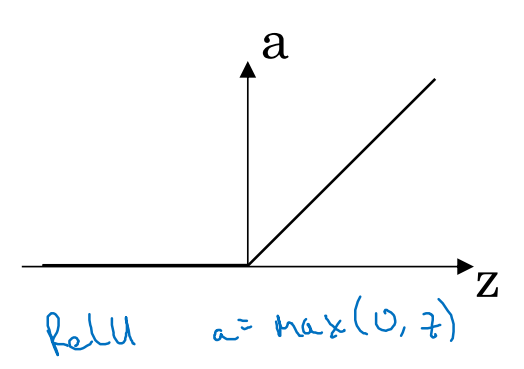
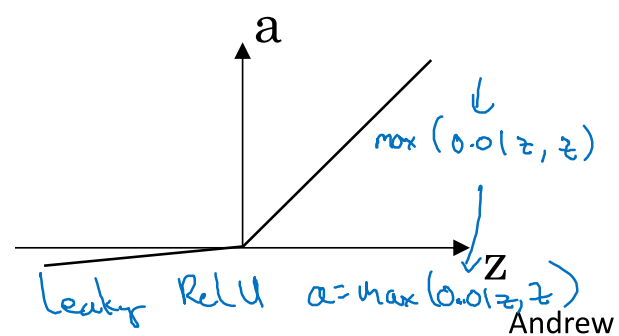
ReLU的好处是其没有导数变化缓慢的区段,在z>0区段,其导数保持在1。而无论是sigmoid还是tanh,在z很大或者很小时都变化相对缓慢。
Leaking ReLU是防止出现z<0时导数为0的情况,当然大多数情况下z都是正数。
为什么我们会需要非线性函数作为激活函数?
可以想象一下求解三元方程式,我们只有2个式子,无论我们把现有的2个式子做何种线性组合变化,产生的第三个方程都没有办法求解方程式。在神经网络中一样,如果激活函数是线性的,多层神经网络的效果就会降低到只有一层。2次线性组合完全可以合并成1次线性组合。
这里我个人疑惑过ReLU相对于分段的线性函数,为何其就可以做激活函数?然后百度了下,发现正是因为其分段,让其导数不是一个恒定量,就不会出现上面说的问题。所以从整体上说ReLU是一个非线性函数。
神经网络的逆向推导
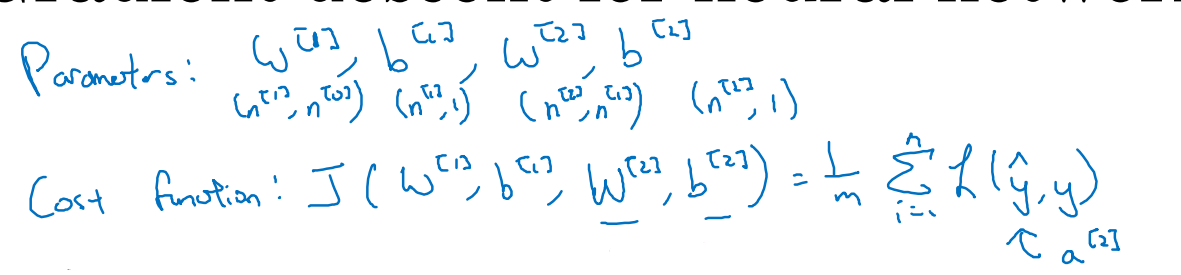
神经网络中,cost函数是单个loss函数的平均,参数w,b的维度不变。


dz[2]的维度为[1,1],dZ[2]的维度为[1,m],m为样本个数。
其可以直接从单维向量扩展到二维矩阵。
而dW[2]和db[2]的维度在单样本和多样本情况下不会变化。而dZ[2]A[1]是[1,m]*[m,n1],n1为第一层神经元个数。计算出来虽然也是[1,n1],但是每个位置都是m次叠加,为了和单样本情况保持维度,故在前面加上1/m进行缩放。
同理db[2]也是这个原因,db[2]维度应该是[1,1]。dZ[2]是[1,m],要加和后乘上1/m。


根据导数的递推特点,dz[1] = dL/dz[2] * dz[2]/dz[1]
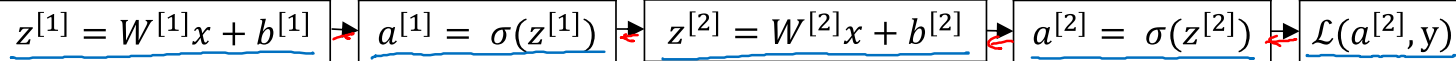
dz[2]/dz[1] = dz[2]/da[1] * da[1]/dz[1] = W[2] * g[1]'
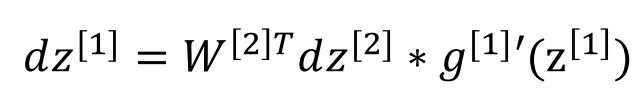
上式中乘号为点乘,保持等号两边维度一致,[n1,1] = [n1,n2][n2,1] * [n1,1]
最后介绍下为何不能初始化为0,要使用随机初始化。
当全部初始化一致时,每层的节点的计算输出会一致,这样反向推导的dw改变也完全一致,使得神经元的个数失去作用。
所以常见做法是初始化随机参数w。在w不同的情况下,允许b初始化为0.
第三周 浅层神经网络
上一周的课程讲解了单神经元的正向及反向传播推导公式及向量化。
一个神经元内部的操作分为两步:第一步是输入特征的线性组合,第二步是将z通过激活函数进行非线性变化得到a,也就是对y的拟合。先沿着正向计算损伤函数L(a,y),再反向计算梯度,沿着dw下降方向来调整参数w = w - α*dw。
这里介绍一个典型的2层神经网络,第1层有4个神经元,第二层有1个神经元。
每个节点都在执行相同的操作
按照向量化的思想,把变量堆积成行变量可以把计算合并
向量化后每层w维度为[此层神经元个数,输入特征个数],b维度为[此层神经元个数,1]
维持等式左右维度相等,a[1] = w[1]*a[0] + b[1]。图示神经网络是[4,1] = [4,3]*[3,1]+[4,1]
第一层的结果a[1]作为第二层的输入。
上面说明的是单示例输入的情况,在真实环境下会有x[1],x[2],x[3]...x[m],每一个示例都可以计算一个a[2]
在向量化操作中,将每个示例作为一列,合并成矩阵,列数即为训练样本的个数
同理,中间每层的输出a[1],a[2]也合并组成矩阵
整个求解过程可以向量化,在多示例向量化的过程中,W和b不变化,和单示例保持一致
就下来说明激活函数,并不限于我们前面求解过程假设的sigmoid函数
sigmoid函数在实际使用中很少,除了在输出层,可以将最后的输出限定在[0,1],常见于二分类问题。
其有个变体函数tanh函数,对比两者的形状
sigmoid函数范围的[0,1],tanh函数将其零点位置拉低到x=0位置,这利于数据的中心化,让下一层的学习更加容易。
而吴老师推荐的是ReLU(Rectified Linear Unit)函数及其变体Leak ReLU
ReLU的好处是其没有导数变化缓慢的区段,在z>0区段,其导数保持在1。而无论是sigmoid还是tanh,在z很大或者很小时都变化相对缓慢。
Leaking ReLU是防止出现z<0时导数为0的情况,当然大多数情况下z都是正数。
为什么我们会需要非线性函数作为激活函数?
可以想象一下求解三元方程式,我们只有2个式子,无论我们把现有的2个式子做何种线性组合变化,产生的第三个方程都没有办法求解方程式。在神经网络中一样,如果激活函数是线性的,多层神经网络的效果就会降低到只有一层。2次线性组合完全可以合并成1次线性组合。
这里我个人疑惑过ReLU相对于分段的线性函数,为何其就可以做激活函数?然后百度了下,发现正是因为其分段,让其导数不是一个恒定量,就不会出现上面说的问题。所以从整体上说ReLU是一个非线性函数。
神经网络的逆向推导
神经网络中,cost函数是单个loss函数的平均,参数w,b的维度不变。
dz[2]的维度为[1,1],dZ[2]的维度为[1,m],m为样本个数。
其可以直接从单维向量扩展到二维矩阵。
而dW[2]和db[2]的维度在单样本和多样本情况下不会变化。而dZ[2]A[1]是[1,m]*[m,n1],n1为第一层神经元个数。计算出来虽然也是[1,n1],但是每个位置都是m次叠加,为了和单样本情况保持维度,故在前面加上1/m进行缩放。
同理db[2]也是这个原因,db[2]维度应该是[1,1]。dZ[2]是[1,m],要加和后乘上1/m。
根据导数的递推特点,dz[1] = dL/dz[2] * dz[2]/dz[1]
dz[2]/dz[1] = dz[2]/da[1] * da[1]/dz[1] = W[2] * g[1]'
上式中乘号为点乘,保持等号两边维度一致,[n1,1] = [n1,n2][n2,1] * [n1,1]
最后介绍下为何不能初始化为0,要使用随机初始化。
当全部初始化一致时,每层的节点的计算输出会一致,这样反向推导的dw改变也完全一致,使得神经元的个数失去作用。
所以常见做法是初始化随机参数w。在w不同的情况下,允许b初始化为0.

相关文章推荐
- 网易云课堂吴恩达Andrew Ng深度学习笔记(四)
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第二节:什么是神经网络
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第四节:为什么深度学习会兴起?
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第三节:用神经网络进行监督学习
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第五节:关于这门课
- 吴恩达(Andrew Ng)深度学习工程师笔记 - 第一门课-神经网络和深度学习-第一周深度学习概论-第六节:课程资源
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(2-1)-- 深度学习的实践方面
- 吴恩达深度学习笔记之卷积神经网络(实例探究)
- 吴恩达深度学习笔记-损失函数和成本函数
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(2-2)-- 优化算法
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础
- 吴恩达【深度学习工程师】学习笔记(三)
- 吴恩达-深度学习笔记《神经网络基础》
- 吴恩达深度学习课程笔记-2
- 吴恩达深度学习笔记 第二章作业1
- 吴恩达深度学习笔记course3 week2 测验
- 吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(4-2)-- 深度卷积模型
- 吴恩达深度学习笔记之改善神经网络(三)
- 吴恩达深度学习课程笔记
- 学习Andrew Ng的神经网络与深度学习的课程Part(一) 笔记一