Kmeans聚类算法
2018-03-01 12:18
281 查看
(该方法不适于发现非凸面形状的簇或大小差别很大的簇。缺点是K值难确定) k均值算法的计算过程: 1、从D中随机取k个元素,作为k个簇的各自的中心。 2、分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇。 3、根据聚类结果,重新计算k个簇各自的中心,计算方法是取簇中所有元素各自维度的算术平均数。 4、将D中全部元素按照新的中心重新聚类。 5、重复第4步,直到聚类结果不再变化。 6、将结果输出。计算距离的方法是使用欧式距离:

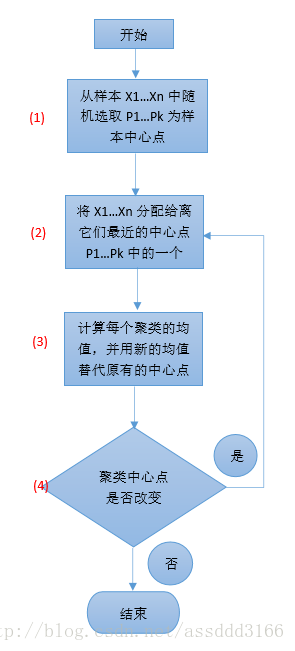
流程图聚类例子
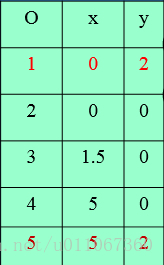
数据对象集合S见上表,作为一个聚类分析的二维样本,要求的簇的数量k=2。
(1)选择
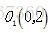
,
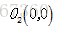
为初始的簇中心,即
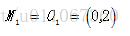
,
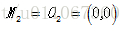
。
(2)对剩余的每个对象,根据其与各个簇中心的距离,将它赋给最近的簇对O3 :
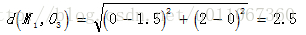
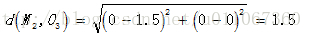
显然
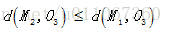
O3,故将C2分配给
对于O4:
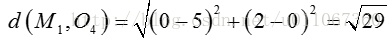
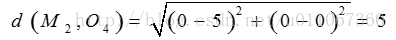
因为:
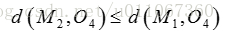
所以将O4分配给C2对于O5:
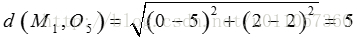
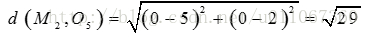
因为:
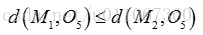
所以讲O5分配给C1
更新,得到新簇
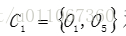
和
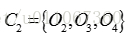
计算平方误差准则,单个方差为
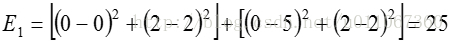
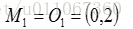
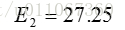
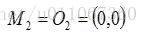
总体平均方差是:
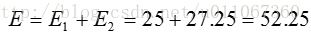
(3)计算新的簇的中心。
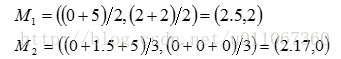
重复(2)和(3),得到O1分配给C1;O2分配给C2,O3分配给C2 ,O4分配给C2,O5分配给C1。更新,得到新簇
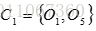
和
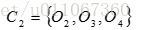
。 中心为
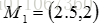
,
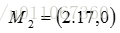
。单个方差分别为
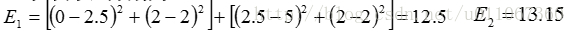
总体平均误差是:
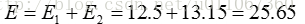
由上可以看出,第一次迭代后,总体平均误差值52.25~25.65,显著减小。由于在两次迭代中,簇中心不变,所以停止迭代过程,算法停止。
流程图聚类例子
数据对象集合S见上表,作为一个聚类分析的二维样本,要求的簇的数量k=2。
(1)选择
,
为初始的簇中心,即
,
。
(2)对剩余的每个对象,根据其与各个簇中心的距离,将它赋给最近的簇对O3 :
显然
O3,故将C2分配给
对于O4:
因为:
所以将O4分配给C2对于O5:
因为:
所以讲O5分配给C1
更新,得到新簇
和
计算平方误差准则,单个方差为
总体平均方差是:
(3)计算新的簇的中心。
重复(2)和(3),得到O1分配给C1;O2分配给C2,O3分配给C2 ,O4分配给C2,O5分配给C1。更新,得到新簇
和
。 中心为
,
。单个方差分别为
总体平均误差是:
由上可以看出,第一次迭代后,总体平均误差值52.25~25.65,显著减小。由于在两次迭代中,簇中心不变,所以停止迭代过程,算法停止。

相关文章推荐
- KMEANS聚类算法
- Kmeans聚类算法及其Python实现
- Kmeans聚类算法原理与实现
- 大数据:Spark mlib(一) KMeans聚类算法源码分析
- matlab下的Kmeans聚类算法
- Kmeans聚类算法及其java实现
- 基础算法(二):Kmeans聚类算法的基本原理与应用
- Kmeans聚类算法-理解
- KMeans聚类算法
- KMeans聚类算法思想与可视化
- KMeans聚类算法Hadoop实现
- kNN与kMeans聚类算法的区别
- kmeans聚类算法
- Kmeans聚类算法原理与实现
- Kmeans聚类算法及其matlab源码
- 改用MyAnalyzer的KMeans聚类算法
- Kmeans聚类算法分析(转帖)
- Kmeans聚类算法 java精简版设计实现编程
- Scala语言实现Kmeans聚类算法
- Spark MLlib StreamingKmeans 实时KMeans聚类算法源代码解读