Prometheus监控使用实践
2018-03-01 00:00
691 查看
摘要: 记录Prometheus的大致介绍,部署实践中遇到的一些问题,以及一些注意点。
Prometheus介绍
Prometheus是一套开源监控报警系统(包括时序列数据库TSDB),自2012年来被许多公司与组织所采用。其中Prometheus的特点如下:
多维数据模型(时序列数据由metric名和一组key/value组成)
在多维度上灵活的查询语言(PromQL)
不依赖分布式存储,单主节点工作.
通过基于HTTP的pull方式采集时序数据
可以通过中间网关进行时序列数据推送(pushing)
目标服务器可以通过发现服务或者静态配置实现
多种可视化和仪表盘支持
其中Prometheus生态系统可以有多个组件构成,大多组件都是独立工作的,可以有选择的配置自己需要的服务,主要有以下:
Prometheus 主服务,用来抓取和存储时序数据
client library 用来构造应用或 exporter 代码 (go,java,python,ruby)
push 网关可用来支持短连接任务
可视化的dashboard (两种选择,promdash 和 grafana.目前主流选择是 grafana.)
实验性的报警管理端(alertmanager,单独进行报警汇总,分发,屏蔽等 )
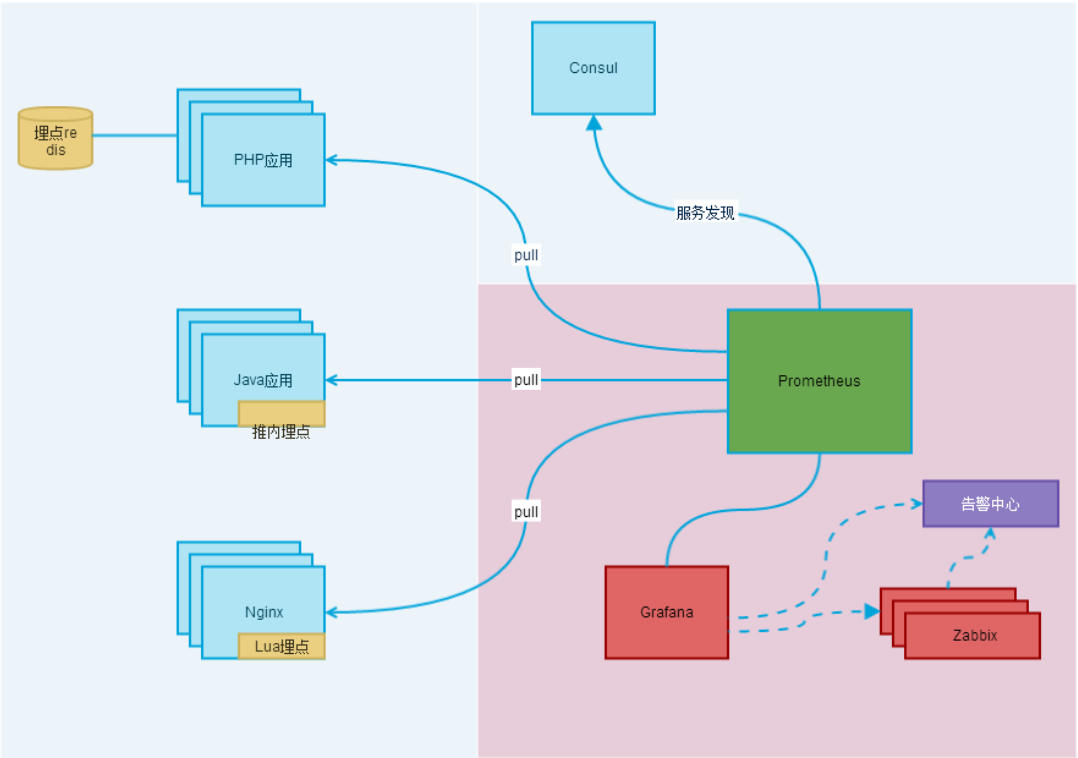
2. Prometheus简单部署(Linux-Centos)
先在官网下载对应安装包(https://prometheus.io/download/),放在Linux中进行解压。具体执行命令如下:
在prometheus文件目录中有一个prometheus.yml文件,使用的是是整个Prometheus运行的主配置文件,其中默认配置包含了大多标准配置及自控配置:
其中job-name作为监控的对象名称,每个job-name不可以重复,其中static_configs下的targets参数很关键,决定了监听的服务地址。在prometheus文件目录下,可以通过如下命令去启动关闭服务。
在启动服务之后,我们可以在虚拟机内访问 http://localhost:9090查看监控状况,也可通过虚拟机的映射地址远程访问。大致如下图所示
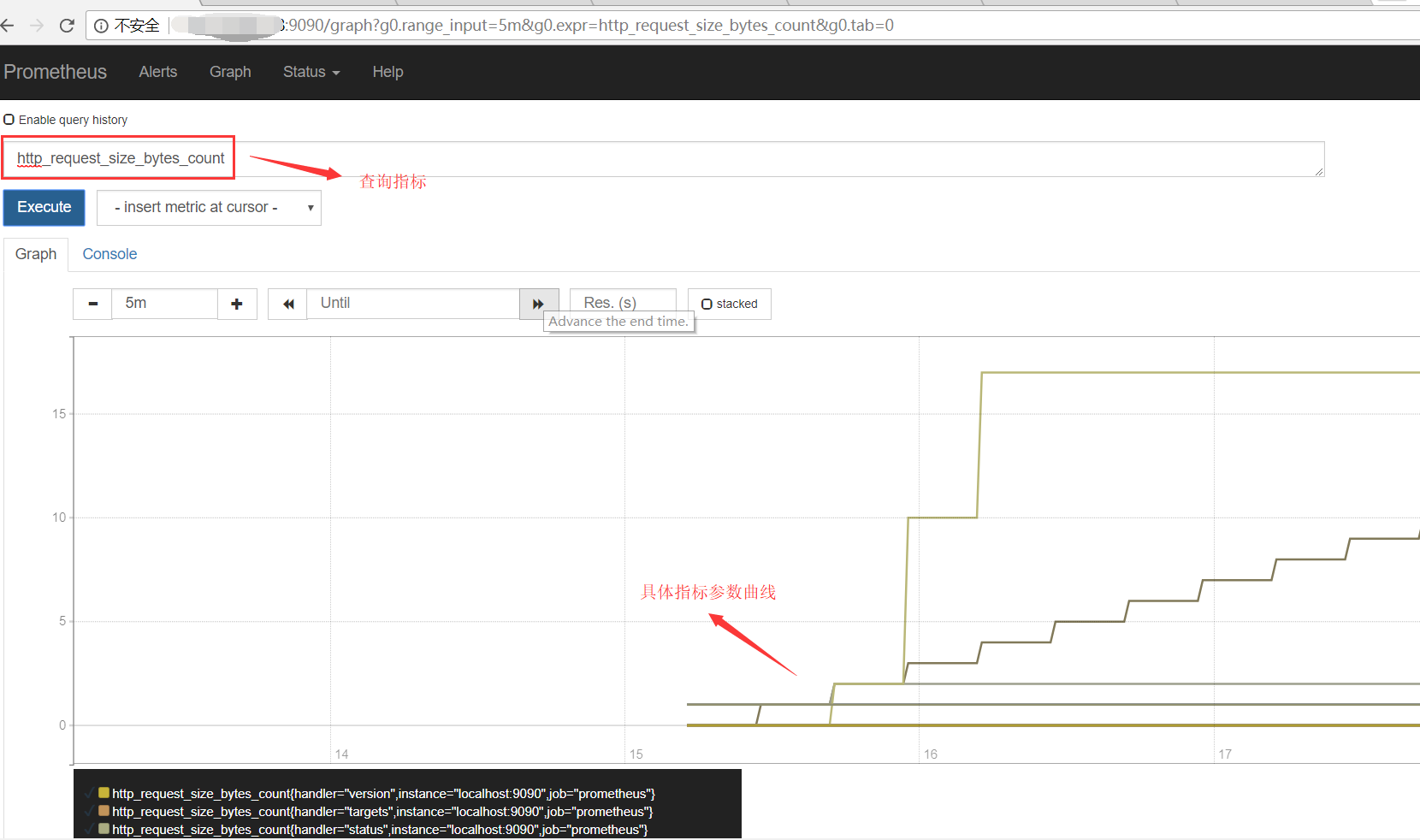
3. Prometheus中PromQL语法记录
在上面的第一个查询框中,可以通过PromQL语句对采集的数据进行处理展示,故把常用的PromQL语法记录如下。
常见匹配符:
常见函数:
具体使用:
后续会继续更新prometheus配合其他组件、监控多种服务的实践记录,若此文存在不足或漏洞,也请在评论中不吝指教。
Prometheus介绍
Prometheus是一套开源监控报警系统(包括时序列数据库TSDB),自2012年来被许多公司与组织所采用。其中Prometheus的特点如下:
多维数据模型(时序列数据由metric名和一组key/value组成)
在多维度上灵活的查询语言(PromQL)
不依赖分布式存储,单主节点工作.
通过基于HTTP的pull方式采集时序数据
可以通过中间网关进行时序列数据推送(pushing)
目标服务器可以通过发现服务或者静态配置实现
多种可视化和仪表盘支持
其中Prometheus生态系统可以有多个组件构成,大多组件都是独立工作的,可以有选择的配置自己需要的服务,主要有以下:
Prometheus 主服务,用来抓取和存储时序数据
client library 用来构造应用或 exporter 代码 (go,java,python,ruby)
push 网关可用来支持短连接任务
可视化的dashboard (两种选择,promdash 和 grafana.目前主流选择是 grafana.)
实验性的报警管理端(alertmanager,单独进行报警汇总,分发,屏蔽等 )
2. Prometheus简单部署(Linux-Centos)
先在官网下载对应安装包(https://prometheus.io/download/),放在Linux中进行解压。具体执行命令如下:
tar xvfz prometheus-*.tar.gz cd prometheus-*
在prometheus文件目录中有一个prometheus.yml文件,使用的是是整个Prometheus运行的主配置文件,其中默认配置包含了大多标准配置及自控配置:
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']
其中job-name作为监控的对象名称,每个job-name不可以重复,其中static_configs下的targets参数很关键,决定了监听的服务地址。在prometheus文件目录下,可以通过如下命令去启动关闭服务。
//启动prometheus服务
nohup ./prometheus --config.file=prometheus.yml
//查询启动的prometheus服务
ps -ef |grep prometheus
//关闭prometheus服务
kill -9 {prometheus-id}在启动服务之后,我们可以在虚拟机内访问 http://localhost:9090查看监控状况,也可通过虚拟机的映射地址远程访问。大致如下图所示
3. Prometheus中PromQL语法记录
在上面的第一个查询框中,可以通过PromQL语句对采集的数据进行处理展示,故把常用的PromQL语法记录如下。
常见匹配符:
+,-,*,/,%,^(加,减,乘,除,取余,幂次方) ==,!=,>,<,>=,<=(等于,不等于,大于,小于,大于等于,小于等于)
常见函数:
sum(求和),min(取最小),max(取最大),avg(取平均),count (计数器) stddev (计算偏差),stdvar (计算方差),count_values(每个元素独立值数量),bottomk (取倒数几个),topk(取前几位)
具体使用:
查询指标name为http_requests_total 条件为job,handler 的数据:
http_requests_total{job="apiserver", handler="/api/comments"}
取5min内 其他条件同上的数据:
http_requests_total{job="apiserver", handler="/api/comments"}[5m]
匹配job名称以server结尾的数据:
http_requests_total{job=~".*server"}
匹配status不等于4xx的数据:
http_requests_total{status!~"4.."}
查询5min内,每秒指标为http_requests_total的数据比率:
rate(http_requests_total[5m])
根据job分组,取每秒数据数量:
sum(rate(http_requests_total[5m])) by (job)
取各个实例的未使用内存量(以MB为单位)
(instance_memory_limit_bytes - instance_memory_usage_bytes) / 1024 / 1024
以app,proc为分组,取未使用内存量(以MB为单位)
sum( instance_memory_limit_bytes - instance_memory_usage_bytes) by (app, proc) / 1024 / 1024
假如数据如下:
instance_cpu_time_ns{app="lion", proc="web", rev="34d0f99", env="prod", job="cluster-manager"}
instance_cpu_time_ns{app="elephant", proc="worker", rev="34d0f99", env="prod", job="cluster-manager"}
instance_cpu_time_ns{app="turtle", proc="api", rev="4d3a513", env="prod", job="cluster-manager"}
instance_cpu_time_ns{app="fox", proc="widget", rev="4d3a513", env="prod", job="cluster-manager"}
以app,proc为分组,取花费时间前三的数据:
topk(3, sum(rate(instance_cpu_time_ns[5m])) by (app, proc))
以app分组,取数据的个数:
count(instance_cpu_time_ns) by (app)
http每秒的平均响应时间:
rate(basename_sum[5m]) / rate(basename_count[5m])后续会继续更新prometheus配合其他组件、监控多种服务的实践记录,若此文存在不足或漏洞,也请在评论中不吝指教。

相关文章推荐
- 使用Prometheus监控服务器性能
- Prometheus监控实践:Kubernetes集群监控
- Prometheus监控的最佳实践——关于监控的3项关键指标
- 使用Prometheus和Grafana定制监控报表
- 360基于Prometheus的在线服务监控实践 - PaaS云
- 360基于Prometheus的在线服务监控实践 - PaaS云
- 使用Helm部署Prometheus和Grafana监控Kubernetes
- 使用Python编写Prometheus监控的方法
- 使用prometheus_client监控程序
- Prometheus监控的最佳实践——关于监控的3项关键指标
- 在实践中使用Jstat监控gc情况 [ 光影人像 东海陈光剑 的博客 ]
- Prometheus监控工具初使用
- 在实践中使用Jstat监控gc情况
- 打造立体化监控体系与APM最佳实践系列 --Zipkin部署与使用
- 数据库安全监控最佳实践:使用DAM工具
- Springboot使用 prometheus监控
- Prometheus监控的最佳实践——关于监控的3项关键指标
- 使用prometheus文件服务发现,监控虚拟机
- Redis实践:使用Pub/Sub实现对服务器群的管理监控
- 打造立体化监控体系与APM最佳实践系列 --Zipkin部署与使用