十分钟快速上手结巴分词
2018-02-24 21:46
323 查看
一.特点
1、支持三种分词模式精确模式,试图将句子最精确的切开;
全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
2、支持繁体分词
3、支持自定义词典
4、MIT授权协议
二.安装说明
代码对Python 2/3 均兼容全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
手动安装:将jieba目录放置于当前目录或者site-packages目录
通过import jieba 来引用
三.算法
基于前缀词典实现高效的词图扫描,生成了句子中汉字所有可能成词情况所构成的有向无环图(DAG)采用了动态规划查找最大路径概率,找出基于词频的最大切分组合
对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
四.主要功能
1.分词
jieba.cut方法接受三个输入参数:需要分词的字符串;cut_all参数用来控制是否采用全模式;HMM参数用来控制是否使用HMM模型jieba.cut_for_search方法接受两个参数:需要分词的字符串;是否使用HMM模型。该方法适用于搜索引擎构建倒排索引的分词,粒度比较细
待分词的字符串可以是unicode或UTF-8字符串、GBK字符串
jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(Unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回list
jieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定义分词器,可用于同时使用不同词典。jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射
相关函数原型: def cut(self, sentence, cut_all=False, HMM=True):
'''
The main function that segments an entire sentence that contains
Chinese characters into seperated words.
Parameter:
- sentence: The str(unicode) to be segmented.
- cut_all: Model type. True for full pattern, False for accurate pattern.
- HMM: Whether to use the Hidden Markov Model.
'''
def cut_for_search(self, sentence, HMM=True):
"""
Finer segmentation for search engines.
"""
def lcut(self, *args, **kwargs):
return list(self.cut(*args, **kwargs))
def lcut_for_search(self, *args, **kwargs):
return list(self.cut_for_search(*args, **kwargs))代码示例:#_*_coding:utf-8_*_
import jieba
if __name__ == '__main__':
seg_list = jieba.cut("我来到北京清华大学", cut_all=True) #全模式
print("Full Mode:" + "/".join(seg_list))
seg_list = jieba.cut("我来到北京清华大学", cut_all=False) #精确模式
print("Default Mode:" + "/".join(seg_list))
seg_list = jieba.cut("他来到了网易杭研大厦", HMM=False) #不使用HMM模型
print("/".join(seg_list))
seg_list = jieba.cut("他来到了网易杭研大厦", HMM=True) #使用HMM模型
print("/".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造", HMM=False) #搜索引擎模式
print("/".join(seg_list))
seg_list = jieba.lcut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造", HMM=True)
print(seg_list)运行结果:

2.添加自定义词典
载入词典:开发者可以指定自己定义的词典,以便包含jieba词库里没有的词。虽然jieba有新词识别能力,但是自行添加新词可以保证更高的正确率。
用法:jieba.load_userdict(file_name) file_name为文件类对象或自定义词典的路径
词典格式和dict.txt一样,一个词占一行;每一行分三个部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name若为路径或二进制方式打开的文件,则文件必须为UTF-8编码。
词频省略时使用自动计算的能保证分出该次的词频。
例子:import jieba
if __name__ == '__main__':
test_sent = (
"李小福是创新办主任也是云计算方面的专家; 什么是八一双鹿\n"
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凯特琳了。"
)
words = jieba.cut(test_sent) #在使用自定义词典或添加词条前的切割测试
print("/".join(words))
jieba.load_userdict("userdict.txt") #加载用户自定义词典
print("=" * 100)
words = jieba.cut(test_sent) #用户自定义词典中出现的词条被正确划分
print("/".join(words))
jieba.add_word("石墨烯") #添加词条石墨烯和凯特琳
jieba.add_word("凯特琳")
jieba.del_word("自定义词") #删除词条自定义词
print("=" * 100)
words = jieba.cut(test_sent) #再次进行测试
print("/".join(words))更改分词器(默认为jieba.dt)的tem_dir和catch_file属性,可分别指定缓存文件所在的文件夹以及文件名,用于受限的文件系统。
调整词典:
使用add_word(word, freq = None, tag = None)和del_word(word)可在程序中动态修改词典。(在前面的程序实例中已经讲到)
使用suggest_freq(segment, tune = True)可调节单个词语的词频,使其能(或不能)被分出来
注意:自动计算的词频在使用HMM新词发现功能时可能无效。
代码实例:import jieba
if __name__ == '__main__':
print("/".join(jieba.cut("如果放到post中将出错。", HMM=False)))
jieba.suggest_freq(("中", "将"), True) #可以print查看
print("/".join(jieba.cut("如果放到post中将出错。", HMM=False)))
print("/".join(jieba.cut("台中正确应该不会被切开", HMM=False)))
jieba.suggest_freq("台中", True)
print("/".join(jieba.cut("台中正确应该不会被切开", HMM=False)))
3.关键词提取
基于TF-IDF算法的关键词提取import jieba.analyse
jieba.analyse.extract_tags(sentence, topK = 20,withWeight = False, allowPOS = ())
sentence为待提取文本
topK为返回几个TF-IDF权重最大的关键词,默认值为20
withWeight为是否一并返回关键词权重值,默认值为FALSE
allowPOS仅包括指定词性的词,默认值为空,即不筛选
jieba.analyse.TFIDF(idf_path = None)新建TFIDF实例,idf_path为IDF频率文件
代码实例(关键词提取):import jieba
import jieba.analyse
file_name = "testfile"
content = open(file_name, "r")
bf5a
.read()
tags = jieba.analyse.extract_tags(content, topK=10)
print("/".join(tags))
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法:jieba.analyse.set_idf_path(file_path) #file_path为自定义语料库的路径
自定义语料库示例https://raw.githubusercontent.com/fxsjy/jieba/master/extra_dict/idf.txt.big
用法示例:import jieba
import jieba.analyse
file_name = "testfile"
content = open(file_name, "r").read()
jieba.analyse.set_idf_path("path")
tags = jieba.analyse.extract_tags(content, topK=10)
print("/".join(tags))
关键词提取所使用的停用词文本语料库可以切换成自定义语料库的路径
用法:jieba.analyse.set_stop_words(file_path) #file_path为自定义语料库路径
自定义语料库示例:https://github.com/fxsjy/jieba/blob/master/extra_dict/stop_words.txt
用法示例:import jieba
import jieba.analyse
file_name = "testfile"
content = open(file_name, "r").read()
jieba.analyse.set_idf_path("path")
jieba.analyse.set_idf_path("path")
tags = jieba.analyse.extract_tags(content, topK=10)
print("/".join(tags))关键词一并返回关键词权重示例:import jieba
import jieba.analyse
file_name = "testfile"
content = open(file_name, "r").read()
jieba.analyse.set_idf_path("path")
jieba.analyse.set_idf_path("path")
tags = jieba.analyse.extract_tags(content, topK=10, withWeight=True)
for tag in tags:
print("tag:%s\t\t weight:%f" % (tag[0], tag[1]))基于TextRank算法的关键词抽取
jieba.analyse.textrank(sentence, topK = 20, withWeight = False, allowPOS = ('ns', 'n', 'vn', 'v'))直接使用,接口相同,注意默认过滤词性
jieba.analyse.TextRank()新建自定义TextRank示例
基本思想:
将待抽取关键词的文本进行分词
以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
计算图中节点的pagerank,注意是无向带权图
使用示例:import jieba
import jieba.analyse
import jieba.posseg
s = "此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。"
for x, w in jieba.analyse.extract_tags(s, withWeight=True):
print("%s %s" % (x, w))
4.词性标注
jieba.posseg.POSTokenizer(tokenizer = None)新建自定义分词器,tokenizer参数可指定内部使用的jieba.Tokenizer。标注句子分词后每个词的词性,采用和ictclas兼容的标记法。用法示例:import jieba.posseg as pseg
words = pseg.cut("我爱北京天安门")
for word, flag in words:
print("%s %s" % (word, flag))
5.Tokenize:返回词语在原文的起止位置
注意,输入参数只接受Unicode默认模式:import jieba
result = jieba.tokenize("永和服装饰品有限公司")
for tk in result:
print("word %s\t\t start:%d\t\t end:%d" % (tk[0],tk[1],tk[2]))搜索模式:import jieba
result = jieba.tokenize("永和服装饰品有限公司",mode="search")
for tk in result:
print("word %s\t\t start:%d\t\t end:%d" % (tk[0],tk[1],tk[2]))
6.命令行分词
使用示例:Python -m jieba news.txt > cut_result.txt命令行选项:

--help选项输出:
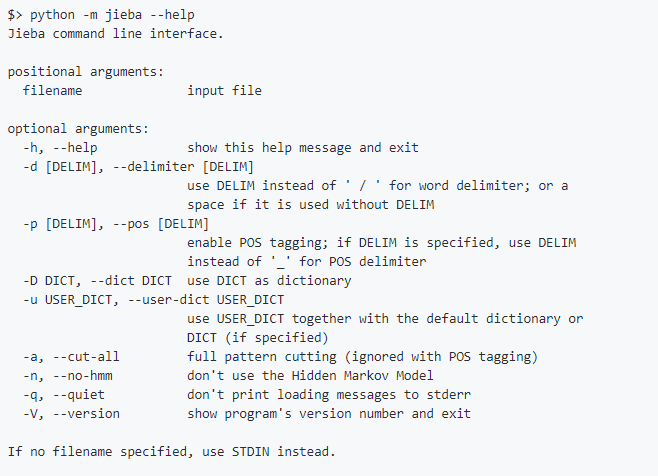
以上就是鸡巴分词...呸,结巴分词的基本用法,关于并行分词和延迟加载机制请查看官方文档。
博主只是学生党一枚,为了做问答系统了解了一下结巴分词,有什么不对的地方还请指出。
最后顺便想你一下@http://blog.csdn.net/weixin_39656575

相关文章推荐
- iBATIS学习01:iBATIS概览+iBATIS十分钟快速上手操练
- 十分钟快速上手tmux,实现高效多屏工作
- python中结巴分词快速入门
- python中结巴分词快速入门
- Eclipse快速上手指南
- 快速上手Spring 加载Bean配置文件
- CSS3快速上手之13:3D效果
- CSS3快速上手之22:按钮样式说明1
- AngularJS入门之如何快速上手(详细讲解什么是angular)
- 结巴分词 0.19 发布 Python 中文分词组件
- 快速上手Delphi三十六计之输入处理篇
- 快速上手MySQL图形化操作详解
- 虚拟机(Virtualbox-Ubuntu)与主机(WIN7)共享文件夹设置 &&19条小技巧让你快速上手Ubuntu 11.04
- J2ME与Web Service-KSOAP的快速上手
- Eclipse快速上手指南之使用ANT
- 一种中文文本的快速分词方法(三)
- 让你快速上手Runtime
- Eclipse快速上手Hibernate--3. 利用XDoclet开发
- iOS适配:Masonry介绍与使用实践:快速上手Autolayout
- 快速上手Spring--5.Bean的标志符(id与name)