使用Python的BeautifulSoup库实现一个可以爬取1000条百度百科数据的爬虫
2018-02-23 18:55
836 查看
BeautifulSoup模块介绍和安装
BeautifulSoupBeautifulSoup是Python的第三方库,用于从HTML或XML中提取数据,通常用作于网页的解析器
BeautifulSoup官网: https://www.crummy.com/software/BeautifulSoup/
官网文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
BeautifulSoup安装很简单,我们可以直接使用pip来安装BeautifulSoup,安装命令如下:
pip install beautifulsoup4
如果使用的IDE是Pycharm的话,安装更简单,直接编写导入模块的语句:
import bs4,然后会报错,提示模块不存在,接着按 alt + 回车,会出现错误修正提示,最后选择安装模块即可自动安装。
安装完成之后编写一段测试代码:
import bs4 print(bs4)
如果执行这段代码,并且正常输出没有报错则代表已经安装成功。
BeautifulSoup的语法:
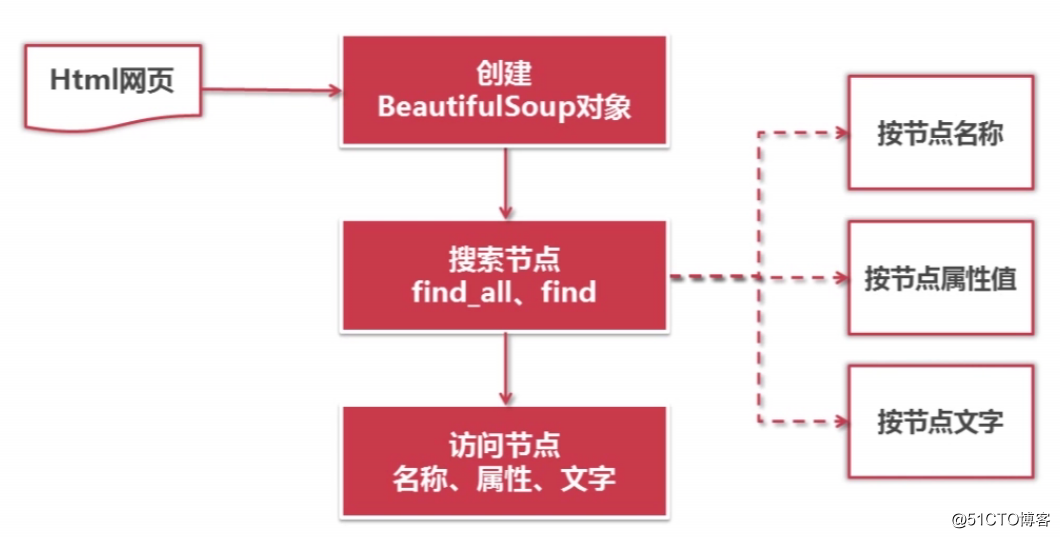
访问节点信息:

语法格式:
from bs4 import BeautifulSoup
import re
# 根据HTML网页字符串内容创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, # HTML文档字符串
'html.parser', # HTML解析器
from_encoding='utf-8' # HTML文档的编码,在python3中不需要加上这个参数
)
# 方法:find_all(name, attrs, string)
# 查找所有标签为 a 的节点
soup.find_all('a')
# 查找所有标签为 a 的节点,并链接符合/view/123.html形式的节点
soup.find_all('a', href='/view/123.html')
soup.find_all('a', href=re.compile('/view/\d+\.html'))
# 查找所有标签为div,class为abc,标签内容为Python的节点
soup.find_all('div', class_='abc', string='标签内容为Python的节点')
# 得到节点:<a href='1.html'>Python</a>
# 获取查找到的节点的标签名称
node.name
# 获取查找到的a节点的href属性
node['href']
# 获取查找到的a节点的链接文字
node.get_text()实际的测试代码:
from bs4 import BeautifulSoup
import re
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')
print("获取所有的连接")
links = soup.find_all('a')
for link in links:
print(link.name, link['href'], link.get_text())
print("\n获取lacie的连接")
link_node = soup.find('a', href='http://example.com/lacie')
print(link_node.name, link_node['href'], link_node.get_text())
print("\n使用正则表达式进行匹配")
link_node = soup.find('a', href=re.compile(r"ill"))
print(link_node.name, link_node['href'], link_node.get_text())
print("\n获取p段落文字")
p_node = soup.find('p', class_="title")
print(p_node.name, p_node.get_text())实例爬虫
简单了解了BeautifulSoup并且完成了BeautifulSoup的安装后,我们就可以开始编写我们的爬虫了。我们编写一个简单的爬虫一般需要完成以下几个步骤:
确定目标确定要爬取的网页,例如本实例要爬取的是百度百科与Python相关的词条网页以及标题和简介
分析目标
分析目标网页的URL格式,避免抓取不相干的URL
分析要抓取的数据格式,例如本实例中要抓取的是标题和简介等数据
分析目标网页的编码,不然有可能在使用解析器解析网页内容时会出现乱码的情况
编写代码
分析完目标页面后就是编写代码去进行数据的爬取
执行爬虫
代码编写完成之后,自然是执行这个爬虫,测试能否正常爬取数据
开始分析本实例需要爬取的目标网页:
目标:百度百科Python词条相关词条网页-标题和简介入口页:https://baike.baidu.com/item/Python/407313
URL格式:
词条页面URL:/item/name/id 或者 /item/name/,例:/item/C/7252092 或者 /item/Guido%20van%20Rossum
数据格式:
标题格式:
<dd class="lemmaWgt-lemmaTitle-title"><h1>***</h1>***</dd>
简介格式:
<div class="lemma-summary" label-module="lemmaSummary">***</div>
页面编码:UTF-8
分析完成之后开始编写实例代码
该爬虫需要完成的目标:爬取百度百科Python词条相关1000个页面数据首先创建一个工程目录,并在目录下创建一个python包,在该包下创建相应的模块文件,如下图:
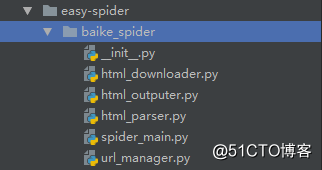
spider_main:爬虫调度器程序,也是主入口文件
url_manager:url管理器,管理并存储待爬取的url
html_downloader:下载器,用于下载目标网页的内容
html_parser:解析器,解析下载好的网页内容
html_outputer:输出器,将解析后的数据输出到网页上或控制台中
爬虫调度器程序代码:
'''
爬虫调度器程序,也是主入口文件
'''
import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
# 初始化各个对象
def __init__(self):
self.urls = url_manager.UrlManager() # url管理器
self.downloader = html_downloader.HtmlDownloader() # 下载器
self.parser = html_parser.HtmlParser() # 解析器
self.outputer = html_outputer.HtmlOutputer() # 输出器
# 爬虫调度方法
def craw(self, root_url):
# 记录当前爬取的是第几个URL
count = 1
# 将入口页面的url添加到url管理器里
self.urls.add_new_url(root_url)
# 启动爬虫的循环
while self.urls.has_new_url():
try:
# 获取待爬取的url
new_url = self.urls.get_new_url()
# 每爬取一个页面就在控制台打印一下
print("craw", count, new_url)
# 启动下载器来下载该url的页面内容
html_cont = self.downloader.download(new_url)
# 调用解析器解析下载下来的页面内容,会得到新的url列表及新的数据
new_urls, new_data = self.parser.parse(new_url, html_cont)
# 将新的url列表添加到url管理器里
self.urls.add_new_urls(new_urls)
# 收集解析出来的数据
self.outputer.collect_data(new_data)
# 当爬取到1000个页面时则停止爬取
if count == 1000:
break
count += 1
except:
# 爬取时出现异常则在控制台中输出一段文字
print("craw failed")
# 输出处理好的数据
self.outputer.output_html()
# 判断本模块是否作为入口文件被执行
if __name__ == "main":
# 目标入口页面的URL
root_url = "https://baike.baidu.com/item/Python/407313"
obj_spider = SpiderMain()
# 启动爬虫
obj_spider.craw(root_url)url管理器代码:
''' url管理器,管理并存储待爬取的url。 url管理器需要维护两个列表,一个是 待爬取的url列表,另一个是已爬取的 url列表。 ''' class UrlManager(object): def __init__(self): self.new_urls = set() # 待爬取的url列表 self.old_urls = set() # 已爬取的url列表 def add_new_url(self, url): ''' 向管理器中添加新的url,也就是待爬取的url :param url: 新的url :return: ''' # url为空则结束 if url is None: return # 该url不在两个列表中才是新的url if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): ''' 向管理器中批量添加新的url :param urls: 新的url列表 :return: ''' if urls is None or len(urls) == 0: return for url in urls: self.add_new_url(url) def has_new_url(self): ''' 判断管理器中是否有待爬取的url :return: True 或 False ''' return len(self.new_urls) != 0 def get_new_url(self): ''' 从url管理器中获取一个待爬取的url :return: 返回一个待爬取的url ''' # 出栈一个url,并将该url添加在已爬取的列表中 new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url
下载器代码:
''' 下载器,用于下载目标网页的内容 ''' from urllib import request class HtmlDownloader(object): def download(self, url): ''' 下载url地址的页面内容 :param url: 需要下载的url :return: 返回None或者页面内容 ''' if url is None: return None response = request.urlopen(url) if response.getcode() != 200: return None return response.read()
解析器代码:
'''
解析器,解析下载好的网页内容
'''
import re
import urllib.parse
from bs4 import BeautifulSoup
class HtmlParser(object):
def parse(self, page_url, html_cont):
'''
解析下载好的网页内容
:param page_url: 页面url
:param html_cont: 网页内容
:return: 返回新的url列表及解析后的数据
'''
if page_url is None or html_cont is None:
return
soup = BeautifulSoup(html_cont, 'html.parser')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
def _get_new_urls(self, page_url, soup):
'''
得到新的url列表
:param page_url:
:param soup:
:return:
'''
new_urls = set()
# 词条页面URL:/item/name/id 或者 /item/name/,例:/item/C/7252092 或者 /item/Guido%20van%20Rossum
links = soup.find_all('a', href=re.compile(r"/item/(.*)"))
for link in links:
new_url = link['href']
# 拼接成完整的url
new_full_url = urllib.parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
'''
解析数据,并返回解析后的数据
:param page_url:
:param soup:
:return:
'''
# 使用字典来存放解析后的数据
res_data = {}
# url
res_data['url'] = page_url
# 标题标签格式:<dd class="lemmaWgt-lemmaTitle-title"><h1>***</h1>***</dd>
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
# 简介标签格式:<div class="lemma-summary" label-module="lemmaSummary">***</div>
summary_node = soup.find('div', class_='lemma-summary')
res_data['summary'] = summary_node.get_text()
return res_data输出器代码:
'''
输出器,将解析后的数据输出到网页上
'''
class HtmlOutputer(object):
def __init__(self):
# 存储解析后的数据
self.datas = []
def collect_data(self, data):
'''
收集数据
:param data:
:return:
'''
if data is None:
return
self.datas.append(data)
def output_html(self):
'''
将收集的数据以html的格式输出到html文件中,我这里使用了Bootstrap
:return:
'''
fout = open('output.html', 'w', encoding='utf-8')
fout.write("<!DOCTYPE html>")
fout.write("<html>")
fout.write('<head>')
fout.write('<meta charset="UTF-8" />')
fout.write(
'<link rel="stylesheet" href="https://cdn.bootcss.com/bootstrap/3.3.7/css/bootstrap.min.css" integrity="sha384-BVYiiSIFeK1dGmJRAkycuHAHRg32OmUcww7on3RYdg4Va+PmSTsz/K68vbdEjh4u" crossorigin="anonymous"/>')
fout.write('</head>')
fout.write("<body>")
fout.write(
'<div style="width: 1000px;margin: auto" class="bs-example" data-example-id="bordered-table" ><table class="table table-bordered table-striped" >')
fout.write(
'<thead><tr style="height: 70px;font-size: 20px"><th style="text-align: center;vertical-align: middle;width: 60px">#</th><th style="text-align: center;vertical-align: middle;width: 150px">URL & 标题</th><th style="text-align: center;vertical-align: middle;">简介</th></tr></thead><tbody>')
num = 0
for data in self.datas:
fout.write("<tr>")
fout.write("<th style='text-align: center;vertical-align: middle;' scope='row'>%d</th>" % num)
fout.write("<td style='text-align: center;vertical-align: middle;'><a href=%s>%s</a></td>" % (
data['url'], data['title']))
fout.write("<td>%s</td>" % data['summary'])
fout.write("</tr>")
num += 1
fout.write("</tbody></table></div>")
fout.write("</body>")
fout.write("</html>")
fout.close()运行效果:
控制台输出:
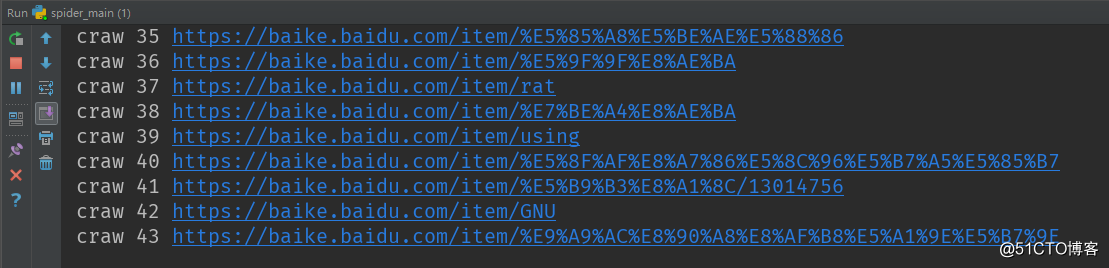
生成的html文件:

至此,我们一个简单的爬虫就完成了。
源码GitHub地址:
https://github.com/Binary-ZeroOne/easy-spider

相关文章推荐
- 使用python实现简单的百度百科词条爬虫
- 【使用JSOUP实现网络爬虫】修改数据-设置一个元素的HTML内容
- Python爬虫实现数据可视化,为你做一个城市旅游数据分析
- 第三百五十节,Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
- 【使用JSOUP实现网络爬虫】修改数据-设置一个元素的HTML内容
- 【C语言】使用回调函数实现一个通用的冒泡排序,可以排序不同的数据类型。
- 使用回调函数实现一个通用的冒泡排序,可以排序不同的数据类型。
- 使用事务与锁,实现一个用户取过的数据不被其他用户取到
- 使用事务与锁,实现一个用户取过的数据不被其他用户取到
- python cgi ajax - 使用CGIHTTPServer实现一个ajax程序
- 用python实现的可以拷贝或剪切一个文件列表中的所有文件
- 使用silverlight构建一个工作流设计器(十八)-持久化数据到数据库—服务器段功能实现
- 使用事务与锁,实现一个用户取过的数据不被其他用户取到
- 使用事务与锁,实现一个用户取过的数据不被其他用户取到
- 使用事务与锁,实现一个用户取过的数据不被其他用户取
- 使用事务与锁,实现一个用户取过的数据不被其他用户取到
- Java 有几程方法可以实现一个线程?用什么关键字修饰同步?stop()和suspend()为什么不推荐使用?
- Getting Started Spidering a Site使用Chilkat(python)练习的一个爬虫(from :http://www.example-code.com)
- 使用事务与锁,实现一个用户取过的数据不被其他用户取到
- 转:邹建-- 使用事务与锁,实现一个用户取过的数据不被其他用户取到