MySQL探索之路——高性能索引
2018-02-11 01:52
204 查看
索引
索引是存储引擎用于快速找到记录的一种数据结构。索引类似于目录,在索引中找到对饮的值,然后根据索引记录找到对应的数据行。mysql中索引可以包含一个或多个列的值。
索引类型
①B-Tree索引虽然叫B-Tree索引,但不同的存储引擎可能底层的数据结构有所不同,例如NDB集群引擎用的是T-Tree,而InnoDB用的是B+Tree。
首先看一下B树和B+树的区别(此图引用简书:https://www.jianshu.com/p/0371c9569736)
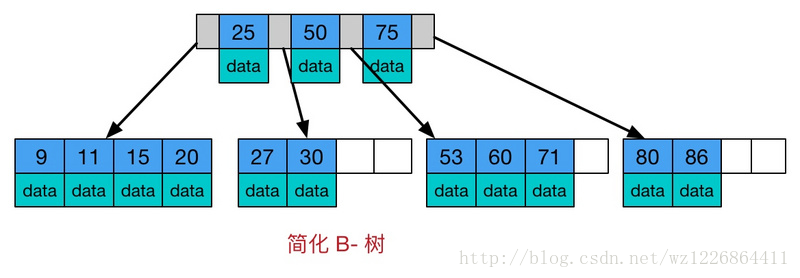
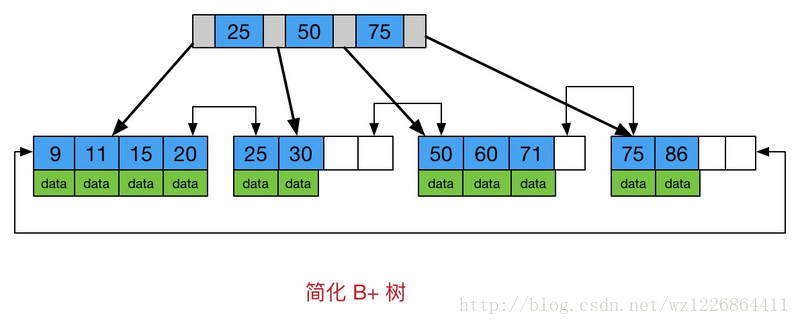
由上两个图可见:
B+树中只有叶子节点会带有指向记录的指针,而B树则所有节点都带有,在内部节点出现的索引项不会再出现在叶子节点中。
B+树中所有叶子节点都是通过指针连接在一起,而B树不会。
B+树的优点:
1. 非叶子节点不会带上指向数据的指针,这样,一个块中可以容纳更多的索引项。
2. 叶子节点之间通过指针来连接,范围扫描将十分简单,而对于B树来说,则需要在叶子节点和内部节点不停的往返移动。
B-tree所有能够加快访问数据的速度,存储引擎不需要进行权标扫描获取数据,通过比较节点的值找对应对数据的指针来访问数据,叶子节点的指针就是指向被索引的数据。同时B-Tree对索引列是顺序组织的,所以很适合查找范围数据。
B-Tree索引适合全键值,键值范围或最左前缀查找。
限制
需要按照索引从最左列开始查找。
不能跳过索引中的列。
范围查找某个列,右边的列无法使用索引优化。
②哈希索引
哈希索引基于哈希表实现,存储引擎根据索引列计算出哈希值,将哈希码存储在索引中,同时保存指向对应数据行的指针。
在mysql中,只有memory引擎支持哈希索引。
限制
哈希索引数据并不是按索引值顺序存储,无法用于排序。
哈希索引不支持部分匹配列查找。因为哈希索引是根据所有选中的列得出哈希值,所以查找时也需要选中所有列。
哈希索引只支持等值查询,如果是范围查询就失效了。
哈希冲突会导致搜索变慢,需要遍历相同索引值的行指针。
自适应哈希索引
这是InnoDB的一个特性,当索引值被使用频繁时,就会在B-Tree索引上再创建一个哈希索引。这个行为是自动的。
③其他索引还有很多
索引优点
①减少了扫描的数据量②避免排序和临时表
③将随机IO变为顺序io
索引优化
①独立索引列:使用独立的索引列,例如select xx where id + 4 = 5;将id和4放在一起,这样mysql无法进行优化。②前缀索引:如果遇到很长的字符列,会让索引变的大很慢,这一采用模拟哈希索引,用crc32产生索引值,用触发器维护索引。还有一种方法是索引部分得到开始字符。但是最降低索引的选择性,所以需要选择既不能太长又可以满足比较高的选择性。也就是说前缀索引的选择性要和原来索引整个列的选择性接近。可以用SELECT COUNT()去统计原来的列和前缀列,使他们结果接近。也可以用SELECT COUNT(DISTINCT 字段)/COUNT() FROM 表计算选择性。
③多列索引:当对几个单独的索引列查询时,应该考虑设置一个多列的索引。
⑤聚簇索引:聚簇索引就是在叶子页将索引和数据聚集在了一起。这种索引使得找到索引后就能直接将全部数据读出来,减少IO次数,访问速度快。二级索引指向的地方不是数据的物理地址,而是主键值,这样数据移动时就不需要修改二级索引指向的地址。
聚簇索引缺点:更新索引代价高,移动索引时也会移动数据行;移动行时可能会导致页分裂;全表扫描变慢;二级索引变大。
⑥覆盖索引:覆盖索引就是索引节点就包含了需要的数据,这样就不用二次根据主键去查找所有数据。但是mysql中只有b-tree支持覆盖索引,因为只有b-tree存储索引列的值。
⑦使用索引扫描做排序:使索引列顺序和order by子句顺序一致,所有列排序方向一致。
###索引和锁
InnoDB只有在访问行时才会加锁,也就是说从存储引擎中拿出数据到服务层进行删选时,这时候就会把这些数据都锁住,我们要做的就尽量减少拿出的数据量,也就是减小锁的范围。

相关文章推荐
- High Performance Mysql 读书笔记——创建高性能索引
- MySql 高性能 5.5 维护索引和表 189页
- 高性能的MySQL(5)创建高性能的索引一哈希索引
- 高性能MySQL之创建高性能的索引
- mysql 创建高性能索引
- MySql 优化详解(二)高性能的索引
- 高性能MySQL笔记-索引设计规范
- 高性能mysql-第五章索引(3)
- 高性能MySQL--创建高性能的索引
- 高性能的MySQL(5)索引策略一聚簇索引
- [高性能MySQL]-创建高性能的索引
- MySQL学习笔记--创建高性能索引
- MySQL索引背后的之使用策略及优化(高性能索引策略)
- 高性能MySQL笔记-第5章Indexing for High Performance-003索引的作用
- mysql性能优化之创建高性能索引
- Mysql优化之创建高性能索引(二)
- 高性能mysql笔记(七)高性能的索引策略
- 高性能Mysql-5创建高性能的索引(上)
- 高性能的MySQL(5)索引策略一聚簇索引
- mysql-高性能索引策略