【Python 2.7】火车票查询
2018-02-10 10:16
225 查看
『一』初衷
春节临近,为了能够更加快速进行查询(其实还是懒得在12306上一次次重复点点点)自己想要的火车票的余票信息,就萌生出了想要写一个爬取火车票的小程序的想法,正好公司主要使用的Python 2.7,自己刚接触Python一个多月正需要验证一下学习情况,就自己动手写了这个火车票查询程序。
『二』准备工作1、我需要完成的是从12306上抓取数据,因此需要使用requests包的get()方法;
2、对抓取到的数据进行解析,因为获取到的数据均为json格式数据,则需要使用json包;
3、我想要在数据获取之后以一个比较美观的形式展示出来,因此使用了prettytable模块用来展示。
4、通过查看12306上查询余票信息时调用的接口信息,如下: https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2018-02-13&leftTicketDTO.from_station=XAY&leftTicketDTO.to_station=BJP&purpose_codes=ADULT 注意其中标红的字段,train_date是乘车日期,from_station为出发站,to_station为到达站,这三个参数是必需的,所以我先从这三个参数入手。
首先,观察到出发站和到达站不是该站点的拼音,而是不同的Code,所以我们要先获取各个车站站点的Code并生成一个字典,这样在之后进行查询时也能对输入数据的合法性进行判断。
新建一个get_station.py文件,编写:
#-*- coding: utf-8 -*-
import re
import requests
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9042'#获取站点拼音和代码对应的网址
station_html = requests.get(url)
stationtxt = station_html.text
stationtxt = stationtxt.encode('unicode_escape')
stationtxt = stationtxt.encode('utf-8')
list = stationtxt.split('@')
length = len(list)
stationsCP = {}
for i in range(1,length):
st = list[i]
list_new = st.split('|')
Pinyin = list_new[3]#拼音
Code = list_new[2]#代码
Chinese = list_new[1]#汉字
stationsCP[Code] = (Pinyin)
print "stationsCP = ",stationsCP
#执行 python get_stations.py > stations.py 完成后会生成stations.py文件,用来保存站点的拼音和代码 完成上一步之后我们就获取到了一个包含所有站点的字典啦~接下来进行下一步,读取用户输入的出发站、到达站、乘车日期这三个参数并进行合法性判断。我选择新建一个文件,将这些函数都写在这个文件里,命名为Get_and_Check.py,编写:#-*- coding: utf-8 -*-
#获取出发站并判定信息合法性
def get_from_station(correct_station):#correct_station为上一步生成的那个stations字典
import re
while 1:
#对用户输入的数据进行预处理,去除前后和中间包含的空格,并将字符置为小写
get_from_station = (raw_input("Please Input from_Station:")).lower().strip()
get_from_station = "".join(get_from_station.split())
if get_from_station == '':
continue
if get_from_station in correct_station:#判断是否合法,合法返回,不合法再次输入
return get_from_station
elif get_from_station == 'q':
return 'quit'
else:
print "\nThe from_Station IS WRONG! Please TRY AGAIN!\n"
#获取到达站并判断信息合法性
def get_to_station(correct_station,get_from_station):#correct_station为上一步生成的那个stations字典
import re
while 1:
#对用户输入的数据进行预处理,去除前后和中间包含的空格,并将字符置为小写
get_to_station = (raw_input("Please Input to_Station:")).lower().strip()
get_to_station = "".join(get_to_station.split())
if get_to_station == '':
continue
if get_to_station in correct_station:#判断是否合法,合法返回,不合法再次输入
if get_to_station == get_from_station:#出发站和到达站不能相同
print "\nSAME STATIONS!!!\n"
continue
else:
return get_to_station
elif get_to_station == 'q':
return 'quit'
else:
print "\nThe to_Station IS WRONG! Please TRY AGAIN!\n"
#获取发车时间并判断信息合法性
def get_search_date(today,lastday):#today为今天的日期,lastday为本系统可查询的最后日期
import re, datetime
today = str(today)#获取今天的日期
today = re.match(r'^(\d{4}).(\d{2}).(\d{2})',today)#将日期进行匹配分割
now_year = int(today.group(1))
now_month = int(today.group(2))
now_day = int(today.group(3))
today = datetime.date(now_year,now_month,now_day)#重新组合成****-**-**的格式
while 1:
#对用户输入的数据进行预处理,去除前后和中间包含的空格
get_search_date = raw_input("Please Input search_Time:").strip()
get_search_date = "".join(get_search_date.split())
if get_search_date == 'q':
return 'quit'
else:#用户输入了年月日
search_date = re.match(r'^(\d{4}).(\d{2}).(\d{2})',get_search_date)
if search_date:
year = int(search_date.group(1))
month = int(search_date.group(2))
day = int(search_date.group(3))
try:
search_time = datetime.date(year,month,day)
except ValueError:
print "\nWRONG DATE TYPE!\n"
continue
if today <= search_time and search_time <= lastday:#判断查询日期是否在系统可查询时间范围内
return search_time
else:
print "\nWRONG DATE RANGE!!\n"
continue
else:#用户只输入了月和日,则默认本年
search_date = re.match(r'^(\d{2}).(\d{2})',get_search_date)
if search_date:
year = now_year
month = int(search_date.group(1))
day = int(search_date.group(2))
try:
search_time = datetime.date(year,month,day)
except ValueError:
print "\nWRONG DATE TYPE!\n"
continue
if today <= search_time and search_time <= lastday:
return search_time
else:
print "\nWRONG DATE RANGE!!\n"
continue
else:#用户只输入了日,则默认为本年本月
search_date = re.match(r'^(\d{2})',get_search_date)
if search_date:
year = now_year
month = now_month
day = int(search_date.group(1))
try:
search_time = datetime.date(year,month,day)
except ValueError:
print "\nWRONG DATE TYPE!\n"
continue
if today <= search_time and search_time <= lastday:
return search_time
else:
print "
4000
\nWRONG DATE RANGE!!\n"
continue
else:#用户什么都没有输入,则默认为本日
return today 因为有时查某一天的车票没有余票了,就要再切换其他日期,那么我就再新增了一个可以查询连续30天余票信息的功能:#获取连续天数
def get_running_days():
get_running_days = raw_input("Please input the running_days:").strip()
get_running_days == "".join(get_running_days.split())
if get_running_days == '':
pass
if get_running_days == 'q':
return 'quit'
try:
get_running_days = int(get_running_days)
if get_running_days is None:
running_days = 1
elif get_running_days >= 30:
running_days = 29
else:
running_days = int(get_running_days)
running_days = running_days
except:
running_days = 1
return running_days 好的,到这一步,需要准备的基本数据已经足够了,那么接下来是要进行构建URL、尝试进行连接并抓取数据,然后进行解析输出展示。
先进行连接这一步吧,还是在Get_and_Check.py中新增一段代码:#构建url并获取网页数据
def connect_and_get(code_date,code_from_station,code_to_station):#分别是查询日期,出发站Code,到达站Code
import requests,json,time
url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}
&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(code_date, code_from_station, code_to_station)
while 1:
try:
r = requests.get(url,timeout = 4)
trains_info = r.json()['data']['result']#解析数据
if len(trains_info) != '':
return trains_info
elif len(trains_info) == '':
continue
except:
return '0'#连接失败 构建URL过程中,使用format将数据填充进去,比拼接字符串简洁明了。
接下来是要将抓取到的车票信息进行分类保存,包括商务座、一等座、二等座等等类型,为使用prettytable模块做铺垫:#3 车次 4 始发站 5 出发站 6 终点站 7 到达站 8 发车时间 9 到达时间 10 历时
#11 票种(成人,学生,儿童) 13 日期 32 商务座/特等座 31 一等座
#30 二等座 23 软卧 28 硬卧 29 硬座 26 无座
#车次信息
def analyze(trains_info,stations,search_date):
from prettytable import PrettyTable
tickets = []
if trains_info == '0':
return '0'
else:
for t_info in trains_info:
tickets_info = t_info.split('|')
train_name = tickets_info[3]
from_station = tickets_info[6]
to_station = tickets_info[7]
from_time = tickets_info[8]
arrive_time = tickets_info[9]
duration = tickets_info[10]
train_date = search_date
business_seat = tickets_info[32]
first_seat = tickets_info[31]
second_seat = tickets_info[30]
softsleep = tickets_info[23]
hardsleep = tickets_info[28]
hard_seat = tickets_info[29]
without_seat = tickets_info[26]
station = (' - '.join([stations[from_station],stations[to_station]]))
time = (' - '.join([from_time,arrive_time]))
tickets.append([train_date,train_name,station,time,duration,business_seat,first_seat,second_seat,softsleep,hardsleep,hard_seat,without_seat])
return tickets 『三』主程序
到此,所有的准备工作都做完了,接下来就是要进行展示了。我用到的是PrettyTable模块,不是内置模块,所以需要下载安装一下,进入Python 2.7的安装目录下,我的是 C:\\Python27\Scripts\,然后执行命令 pip install prettytable 下载安装。完成之后我们新建一个新的文件作为主程序,命名为Ticket_Check_System.py#-*- coding: utf-8 -*-
from stations import stations
import Get_and_Check
#注意:如果以上两个文件:stations.py和Get_and_Check.py与主函数不在同一文件目录下,则需要以下方法增加路径
#import sys
#sys.path.append(r"")#双引号内为文件完整路径,如E:\\test\
import datetime
import time
from datetime import date,timedelta
from prettytable import PrettyTable
import requests,re
today = date.today()
now = datetime.datetime.now()
correct_station = stations.keys()#获取站点的Code
lastday = today + timedelta(days = 29)#规定最终日期
#格式化输出
string_1 = '\t\t\t\t+=======================================+'
string_2 = '\t\t\t\t+ # Tickets Search System # +'
print string_1,'\n',string_2,'\n','\t\t\t\t+','\t',today,'to',lastday,'\t','+','\n',string_1,'\n\t\t\t\t Now_Time:',now,'\n'
def get_and_check():
#获取需要进行查询的信息
from_station = Get_and_Check.get_from_station(correct_station)
if from_station == 'quit':
return 'q'
to_station = Get_and_Check.get_to_station(correct_station,from_station)
if to_station == 'quit':
return 'q'
search_date = Get_and_Check.get_search_date(today,lastday)
if search_date == 'quit':
return 'q'
running_days = Get_and_Check.get_running_days()
if running_days == 'quit':
return 'q'
print "\n\t\t\t\t\tFrom_Station:",from_station,"\tTo_Station:",to_station,"\tFrom_Date:",search_date,'\n'
#获取出发站、到达站、发车时间,连接网络获取信息
code_from_station = stations.get(from_station)
code_to_station = stations.get(to_station)
code_date = str(search_date)
#prettytable设置列
pt = PrettyTable('No Date Train From_Station/To_Station From_Date/To_Date Duration Business_Seat FSoft_Seat SSoft_Seat Soft_Sleep Hard_Sleep Hard_Seat Without_Seat'.split(' '))
count = 0#查询到的列车车次计数
pt.clear_rows()#初始化
start_time = time.clock()
#查询
for i in range(running_days):
trains_info = Get_and_Check.connect_and_get(code_date,code_from_station,code_to_station)
tickets = Get_and_Check.analyze(trains_info,stations,search_date)
if tickets == '0':
print code_date,"\tCAN NOT GET CONNETION"
tickets = ""
for ticket in tickets:
ticket.insert(0,count+1)
pt.add_row(ticket)
count = count + 1
search_date = search_date + timedelta(days = 1)
code_date = str(search_date)
end_time = time.clock()
spend_time = end_time - start_time#系统查询运行时间
if count == 0:
print "\nSORRY, I CAN NOT FIND ANY TICKETS!\n"
else:
print '\nTOTAL:',count,'trains\t','Spend Seconds: %d'%spend_time
print pt.get_string()#打印结果
pt.clear()#清空缓存
if __name__ == '__main__':
while 1:
gc = get_and_check()
if gc == 'q':
print "\nSuccessful Quit!"
break『四』结果截图
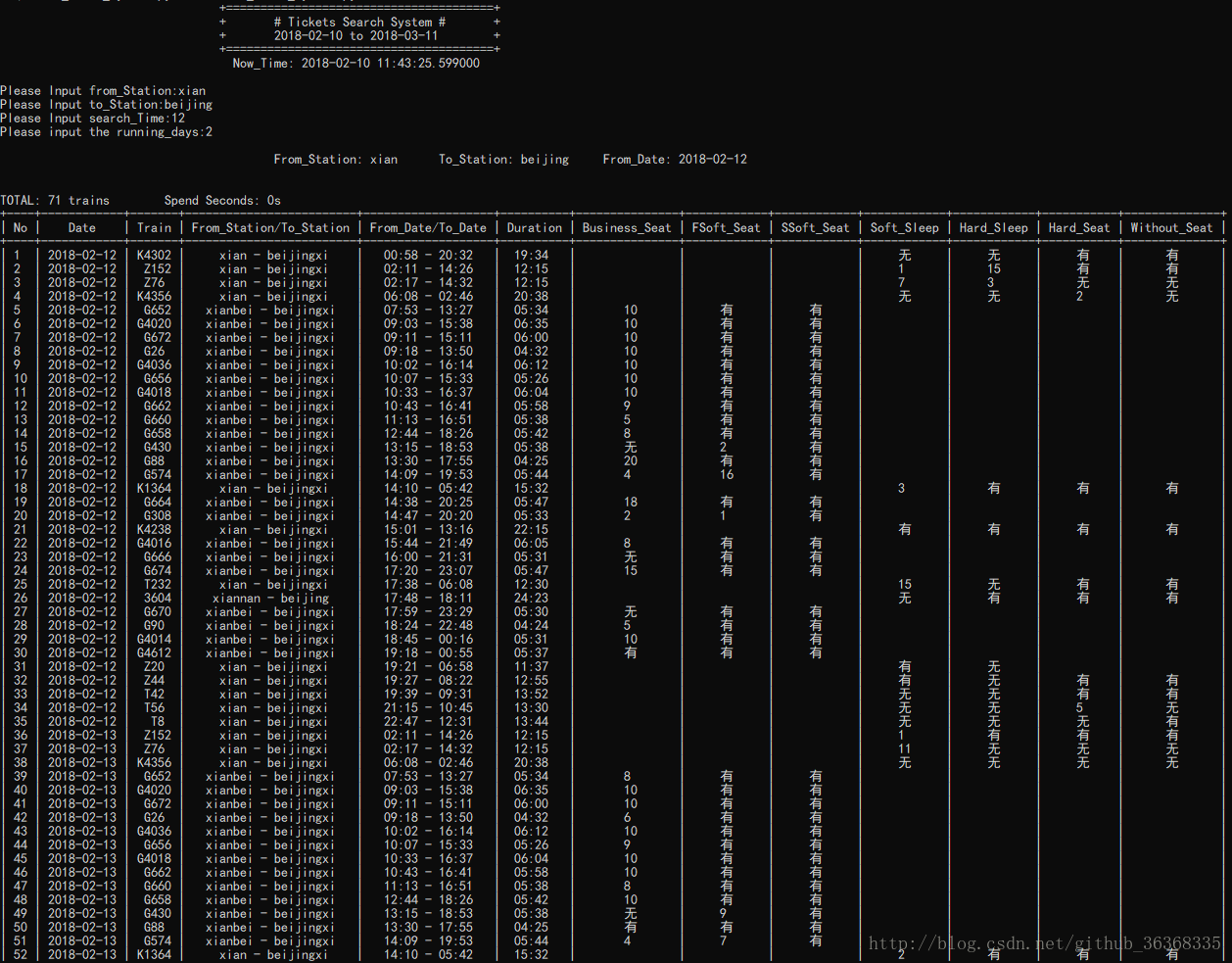
『五』总结
blahblah =。= 太懒了,不想写总结。。。
算了,还是提一下优化问题
1、建议while循环使用 while 1代替 while true,在Python 2.7中,True是全局变量而不是关键字,所以效率上会拖那么一丢丢后腿
2、查询时使用dict代替list,这样会极大地减少查询的时间,但是对内存会有较大需求
3、格式化字符,第一种方式("字符串"+"字符串"+...+"字符串"),用时最短。这里:

这是第二种方式("字符串{}...字符串{}".format(a,b...,n)),用时比第一种慢一点。第三种:

这是最慢的一种方式("字符串%d字符串%s" % (a,b) ),但是可读性是最高的『%d整数 %s字符串 %f浮点数 %c字符』
4、if判断时尽量使用 if ... is ...替代 if ... == ...
5、使用join合并迭代器中的字符串
6、使用级联比较 a<b<c替代 a<b and b<c
7、可以使用性能分析工具查看程序运行时所有模块的花费时间,使用方法如下:
python -m cProfile Ticket_Check_System.py
以上所有提及的性能优化的都可以在本例中找到,也都可以进行优化。
春节临近,为了能够更加快速进行查询(其实还是懒得在12306上一次次重复点点点)自己想要的火车票的余票信息,就萌生出了想要写一个爬取火车票的小程序的想法,正好公司主要使用的Python 2.7,自己刚接触Python一个多月正需要验证一下学习情况,就自己动手写了这个火车票查询程序。
『二』准备工作1、我需要完成的是从12306上抓取数据,因此需要使用requests包的get()方法;
2、对抓取到的数据进行解析,因为获取到的数据均为json格式数据,则需要使用json包;
3、我想要在数据获取之后以一个比较美观的形式展示出来,因此使用了prettytable模块用来展示。
4、通过查看12306上查询余票信息时调用的接口信息,如下: https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2018-02-13&leftTicketDTO.from_station=XAY&leftTicketDTO.to_station=BJP&purpose_codes=ADULT 注意其中标红的字段,train_date是乘车日期,from_station为出发站,to_station为到达站,这三个参数是必需的,所以我先从这三个参数入手。
首先,观察到出发站和到达站不是该站点的拼音,而是不同的Code,所以我们要先获取各个车站站点的Code并生成一个字典,这样在之后进行查询时也能对输入数据的合法性进行判断。
新建一个get_station.py文件,编写:
#-*- coding: utf-8 -*-
import re
import requests
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9042'#获取站点拼音和代码对应的网址
station_html = requests.get(url)
stationtxt = station_html.text
stationtxt = stationtxt.encode('unicode_escape')
stationtxt = stationtxt.encode('utf-8')
list = stationtxt.split('@')
length = len(list)
stationsCP = {}
for i in range(1,length):
st = list[i]
list_new = st.split('|')
Pinyin = list_new[3]#拼音
Code = list_new[2]#代码
Chinese = list_new[1]#汉字
stationsCP[Code] = (Pinyin)
print "stationsCP = ",stationsCP
#执行 python get_stations.py > stations.py 完成后会生成stations.py文件,用来保存站点的拼音和代码 完成上一步之后我们就获取到了一个包含所有站点的字典啦~接下来进行下一步,读取用户输入的出发站、到达站、乘车日期这三个参数并进行合法性判断。我选择新建一个文件,将这些函数都写在这个文件里,命名为Get_and_Check.py,编写:#-*- coding: utf-8 -*-
#获取出发站并判定信息合法性
def get_from_station(correct_station):#correct_station为上一步生成的那个stations字典
import re
while 1:
#对用户输入的数据进行预处理,去除前后和中间包含的空格,并将字符置为小写
get_from_station = (raw_input("Please Input from_Station:")).lower().strip()
get_from_station = "".join(get_from_station.split())
if get_from_station == '':
continue
if get_from_station in correct_station:#判断是否合法,合法返回,不合法再次输入
return get_from_station
elif get_from_station == 'q':
return 'quit'
else:
print "\nThe from_Station IS WRONG! Please TRY AGAIN!\n"
#获取到达站并判断信息合法性
def get_to_station(correct_station,get_from_station):#correct_station为上一步生成的那个stations字典
import re
while 1:
#对用户输入的数据进行预处理,去除前后和中间包含的空格,并将字符置为小写
get_to_station = (raw_input("Please Input to_Station:")).lower().strip()
get_to_station = "".join(get_to_station.split())
if get_to_station == '':
continue
if get_to_station in correct_station:#判断是否合法,合法返回,不合法再次输入
if get_to_station == get_from_station:#出发站和到达站不能相同
print "\nSAME STATIONS!!!\n"
continue
else:
return get_to_station
elif get_to_station == 'q':
return 'quit'
else:
print "\nThe to_Station IS WRONG! Please TRY AGAIN!\n"
#获取发车时间并判断信息合法性
def get_search_date(today,lastday):#today为今天的日期,lastday为本系统可查询的最后日期
import re, datetime
today = str(today)#获取今天的日期
today = re.match(r'^(\d{4}).(\d{2}).(\d{2})',today)#将日期进行匹配分割
now_year = int(today.group(1))
now_month = int(today.group(2))
now_day = int(today.group(3))
today = datetime.date(now_year,now_month,now_day)#重新组合成****-**-**的格式
while 1:
#对用户输入的数据进行预处理,去除前后和中间包含的空格
get_search_date = raw_input("Please Input search_Time:").strip()
get_search_date = "".join(get_search_date.split())
if get_search_date == 'q':
return 'quit'
else:#用户输入了年月日
search_date = re.match(r'^(\d{4}).(\d{2}).(\d{2})',get_search_date)
if search_date:
year = int(search_date.group(1))
month = int(search_date.group(2))
day = int(search_date.group(3))
try:
search_time = datetime.date(year,month,day)
except ValueError:
print "\nWRONG DATE TYPE!\n"
continue
if today <= search_time and search_time <= lastday:#判断查询日期是否在系统可查询时间范围内
return search_time
else:
print "\nWRONG DATE RANGE!!\n"
continue
else:#用户只输入了月和日,则默认本年
search_date = re.match(r'^(\d{2}).(\d{2})',get_search_date)
if search_date:
year = now_year
month = int(search_date.group(1))
day = int(search_date.group(2))
try:
search_time = datetime.date(year,month,day)
except ValueError:
print "\nWRONG DATE TYPE!\n"
continue
if today <= search_time and search_time <= lastday:
return search_time
else:
print "\nWRONG DATE RANGE!!\n"
continue
else:#用户只输入了日,则默认为本年本月
search_date = re.match(r'^(\d{2})',get_search_date)
if search_date:
year = now_year
month = now_month
day = int(search_date.group(1))
try:
search_time = datetime.date(year,month,day)
except ValueError:
print "\nWRONG DATE TYPE!\n"
continue
if today <= search_time and search_time <= lastday:
return search_time
else:
print "
4000
\nWRONG DATE RANGE!!\n"
continue
else:#用户什么都没有输入,则默认为本日
return today 因为有时查某一天的车票没有余票了,就要再切换其他日期,那么我就再新增了一个可以查询连续30天余票信息的功能:#获取连续天数
def get_running_days():
get_running_days = raw_input("Please input the running_days:").strip()
get_running_days == "".join(get_running_days.split())
if get_running_days == '':
pass
if get_running_days == 'q':
return 'quit'
try:
get_running_days = int(get_running_days)
if get_running_days is None:
running_days = 1
elif get_running_days >= 30:
running_days = 29
else:
running_days = int(get_running_days)
running_days = running_days
except:
running_days = 1
return running_days 好的,到这一步,需要准备的基本数据已经足够了,那么接下来是要进行构建URL、尝试进行连接并抓取数据,然后进行解析输出展示。
先进行连接这一步吧,还是在Get_and_Check.py中新增一段代码:#构建url并获取网页数据
def connect_and_get(code_date,code_from_station,code_to_station):#分别是查询日期,出发站Code,到达站Code
import requests,json,time
url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}
&leftTicketDTO.to_station={}&purpose_codes=ADULT'.format(code_date, code_from_station, code_to_station)
while 1:
try:
r = requests.get(url,timeout = 4)
trains_info = r.json()['data']['result']#解析数据
if len(trains_info) != '':
return trains_info
elif len(trains_info) == '':
continue
except:
return '0'#连接失败 构建URL过程中,使用format将数据填充进去,比拼接字符串简洁明了。
接下来是要将抓取到的车票信息进行分类保存,包括商务座、一等座、二等座等等类型,为使用prettytable模块做铺垫:#3 车次 4 始发站 5 出发站 6 终点站 7 到达站 8 发车时间 9 到达时间 10 历时
#11 票种(成人,学生,儿童) 13 日期 32 商务座/特等座 31 一等座
#30 二等座 23 软卧 28 硬卧 29 硬座 26 无座
#车次信息
def analyze(trains_info,stations,search_date):
from prettytable import PrettyTable
tickets = []
if trains_info == '0':
return '0'
else:
for t_info in trains_info:
tickets_info = t_info.split('|')
train_name = tickets_info[3]
from_station = tickets_info[6]
to_station = tickets_info[7]
from_time = tickets_info[8]
arrive_time = tickets_info[9]
duration = tickets_info[10]
train_date = search_date
business_seat = tickets_info[32]
first_seat = tickets_info[31]
second_seat = tickets_info[30]
softsleep = tickets_info[23]
hardsleep = tickets_info[28]
hard_seat = tickets_info[29]
without_seat = tickets_info[26]
station = (' - '.join([stations[from_station],stations[to_station]]))
time = (' - '.join([from_time,arrive_time]))
tickets.append([train_date,train_name,station,time,duration,business_seat,first_seat,second_seat,softsleep,hardsleep,hard_seat,without_seat])
return tickets 『三』主程序
到此,所有的准备工作都做完了,接下来就是要进行展示了。我用到的是PrettyTable模块,不是内置模块,所以需要下载安装一下,进入Python 2.7的安装目录下,我的是 C:\\Python27\Scripts\,然后执行命令 pip install prettytable 下载安装。完成之后我们新建一个新的文件作为主程序,命名为Ticket_Check_System.py#-*- coding: utf-8 -*-
from stations import stations
import Get_and_Check
#注意:如果以上两个文件:stations.py和Get_and_Check.py与主函数不在同一文件目录下,则需要以下方法增加路径
#import sys
#sys.path.append(r"")#双引号内为文件完整路径,如E:\\test\
import datetime
import time
from datetime import date,timedelta
from prettytable import PrettyTable
import requests,re
today = date.today()
now = datetime.datetime.now()
correct_station = stations.keys()#获取站点的Code
lastday = today + timedelta(days = 29)#规定最终日期
#格式化输出
string_1 = '\t\t\t\t+=======================================+'
string_2 = '\t\t\t\t+ # Tickets Search System # +'
print string_1,'\n',string_2,'\n','\t\t\t\t+','\t',today,'to',lastday,'\t','+','\n',string_1,'\n\t\t\t\t Now_Time:',now,'\n'
def get_and_check():
#获取需要进行查询的信息
from_station = Get_and_Check.get_from_station(correct_station)
if from_station == 'quit':
return 'q'
to_station = Get_and_Check.get_to_station(correct_station,from_station)
if to_station == 'quit':
return 'q'
search_date = Get_and_Check.get_search_date(today,lastday)
if search_date == 'quit':
return 'q'
running_days = Get_and_Check.get_running_days()
if running_days == 'quit':
return 'q'
print "\n\t\t\t\t\tFrom_Station:",from_station,"\tTo_Station:",to_station,"\tFrom_Date:",search_date,'\n'
#获取出发站、到达站、发车时间,连接网络获取信息
code_from_station = stations.get(from_station)
code_to_station = stations.get(to_station)
code_date = str(search_date)
#prettytable设置列
pt = PrettyTable('No Date Train From_Station/To_Station From_Date/To_Date Duration Business_Seat FSoft_Seat SSoft_Seat Soft_Sleep Hard_Sleep Hard_Seat Without_Seat'.split(' '))
count = 0#查询到的列车车次计数
pt.clear_rows()#初始化
start_time = time.clock()
#查询
for i in range(running_days):
trains_info = Get_and_Check.connect_and_get(code_date,code_from_station,code_to_station)
tickets = Get_and_Check.analyze(trains_info,stations,search_date)
if tickets == '0':
print code_date,"\tCAN NOT GET CONNETION"
tickets = ""
for ticket in tickets:
ticket.insert(0,count+1)
pt.add_row(ticket)
count = count + 1
search_date = search_date + timedelta(days = 1)
code_date = str(search_date)
end_time = time.clock()
spend_time = end_time - start_time#系统查询运行时间
if count == 0:
print "\nSORRY, I CAN NOT FIND ANY TICKETS!\n"
else:
print '\nTOTAL:',count,'trains\t','Spend Seconds: %d'%spend_time
print pt.get_string()#打印结果
pt.clear()#清空缓存
if __name__ == '__main__':
while 1:
gc = get_and_check()
if gc == 'q':
print "\nSuccessful Quit!"
break『四』结果截图
『五』总结
blahblah =。= 太懒了,不想写总结。。。
算了,还是提一下优化问题
1、建议while循环使用 while 1代替 while true,在Python 2.7中,True是全局变量而不是关键字,所以效率上会拖那么一丢丢后腿
2、查询时使用dict代替list,这样会极大地减少查询的时间,但是对内存会有较大需求
3、格式化字符,第一种方式("字符串"+"字符串"+...+"字符串"),用时最短。这里:
这是第二种方式("字符串{}...字符串{}".format(a,b...,n)),用时比第一种慢一点。第三种:
这是最慢的一种方式("字符串%d字符串%s" % (a,b) ),但是可读性是最高的『%d整数 %s字符串 %f浮点数 %c字符』
4、if判断时尽量使用 if ... is ...替代 if ... == ...
5、使用join合并迭代器中的字符串
6、使用级联比较 a<b<c替代 a<b and b<c
7、可以使用性能分析工具查看程序运行时所有模块的花费时间,使用方法如下:
python -m cProfile Ticket_Check_System.py
以上所有提及的性能优化的都可以在本例中找到,也都可以进行优化。

相关文章推荐
- Python脚本实现12306火车票查询系统
- Python3 实现火车票查询工具
- Python爬取12306实现火车票查询
- 使用Python和Splinter实现12306火车票查询与抢票
- Python3实现火车票查询工具
- 解决python2.7 查询mysql时出现中文乱码
- 12306火车票查询--python
- python火车票查询系统的实现与总结
- [实验楼]Python 实现火车票查询工具
- Python 实现火车票查询工具
- python2.7---查询信息代码
- 使用python脚本实现查询火车票工具
- 12306火车票查询——Python
- 解决python2.7 查询mysql时出现中文乱码
- python火车票查询工具
- Python实现火车票查询小工具
- python实现2014火车票查询代码分享
- 使用Python和Splinter实现12306火车票查询与抢票
- python实现2014火车票查询代码分享
- python实现12306查询火车票