opencv3.3 级联分类器生成xml以及遇到的一些问题
2018-02-08 14:35
316 查看
opencv3.3 训练级联分类器训练成功 来分享一波
今天遇到一位群友 对于级联分类器有点问题 于是我决定把训练的过程分享出来,并且和大家说说训练过程中可能会出现的问题。创建样本步骤:
准备训练集
首先 准备好训练集 正样本和负样本 (我做的是车牌识别 所以选取的正样本是车牌),
正样本放在positive文件夹下的img文件夹里(positive上面那个img文件夹存放的负样本,大家不要混淆了)
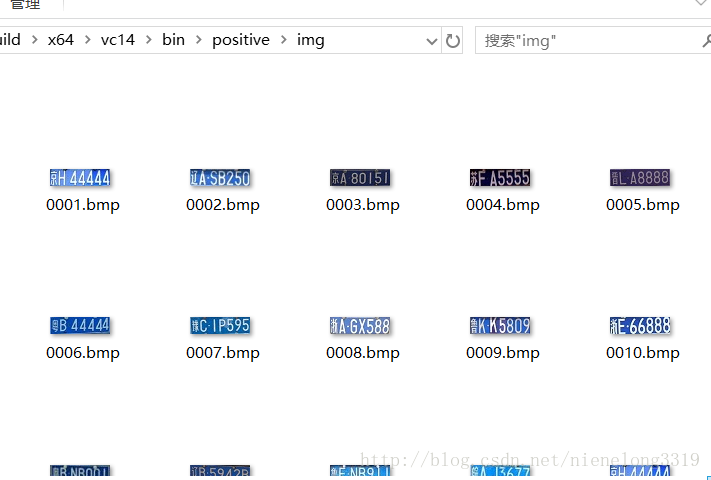
正样本的话 不需要相同大小 ,但是一定要相同比例 ,怕出问题的的就把正样本变成相同大小吧。我用的60*17的车牌图片
负样本的话,是指不包含正样本的其他任意图片,最好能有各种不同大小的不同场景的图片。
<
d799
/p>我将负样本放在img目录下
这个负样本是网上下的 相同大小 20*20 有点粗糙 大家不要学我 。。(最好是能有各种不同大小不同场景的!!)
样本准备好了 接下来生成路径
为正负样本生成描述文件:
将文件夹下的图片遍历一遍 保存到txt文件里,可以用代码,也可以手动的复制粘贴路径写入txt。。
我用的java将文件夹下的图片遍历出来的 ,java代码在下面链接
资源链接
接下来展示一下存放正样本路径的txt的内容
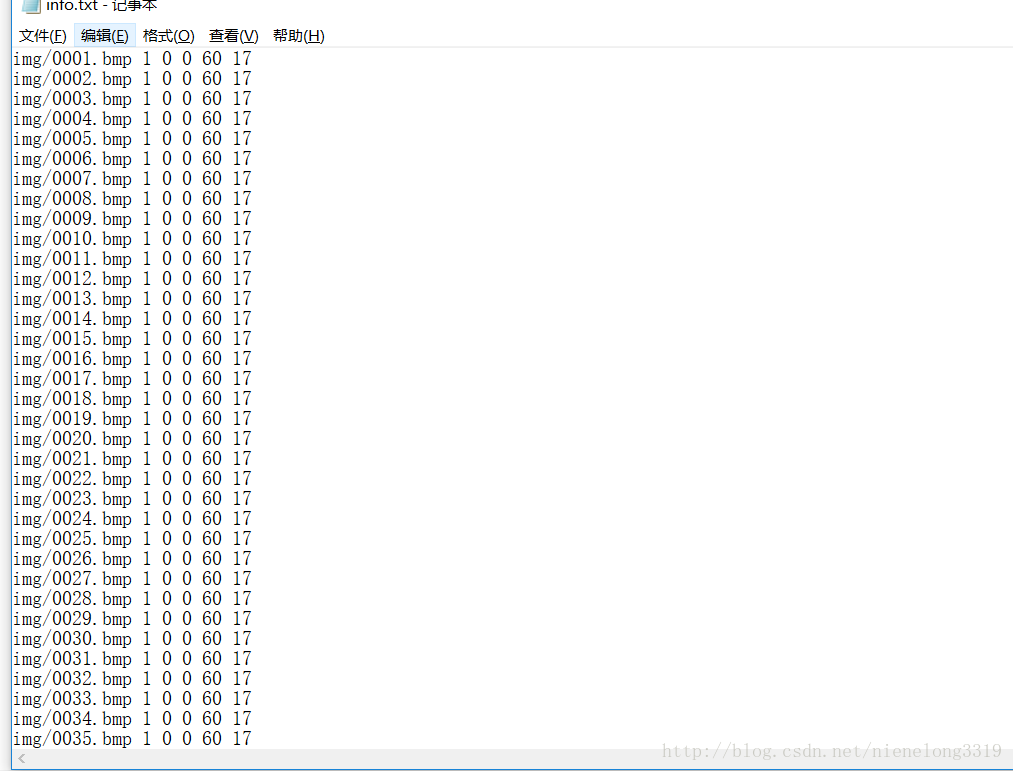
正样本用描述文件格式描述 如下
[filename] [# of objects] [[x y width height] [... 2nd object] ...]
x y指的是图片左上角坐标 width height指的是图片宽高
举个例子:
img/0001.bmp 1 0 0 60 17
1代表一个文件 0 0 代表左上角x y坐标 60 17 表示宽高
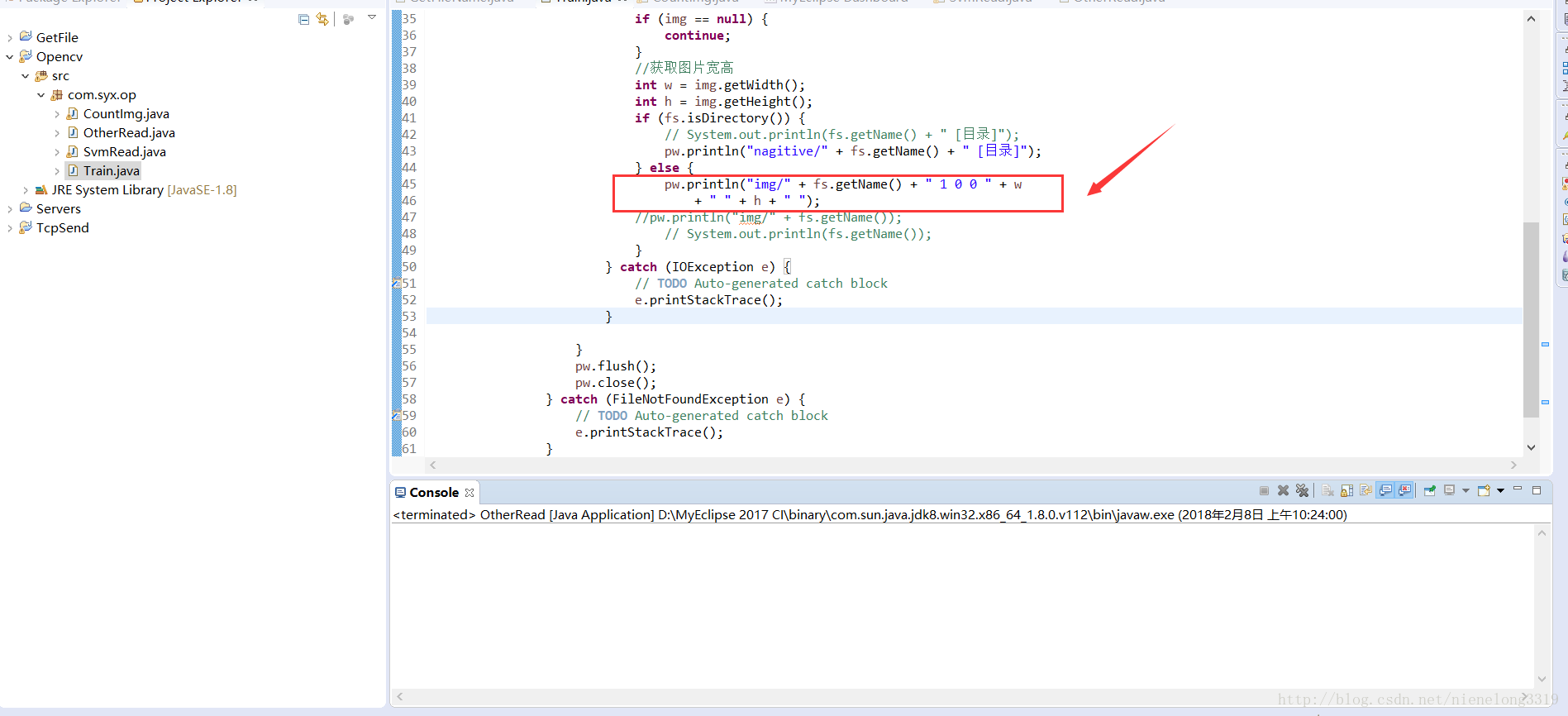
看这个红框代码 自己领悟
然后就是负样本的txt文件 负样本用集合文件格式描述
集合文件格式(collection file format)就是如下形的描述文件:[filename]我将负样本放在bg.txt文件下
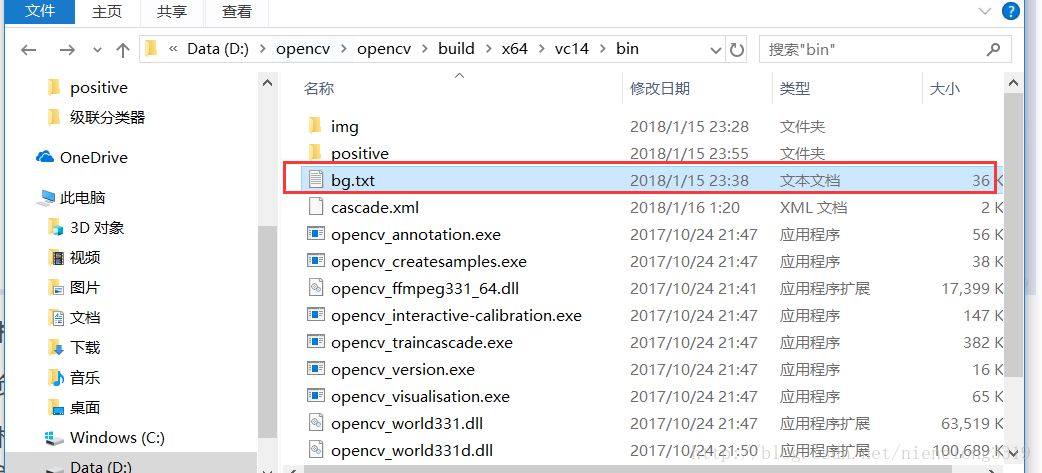

创建样本 直接上图
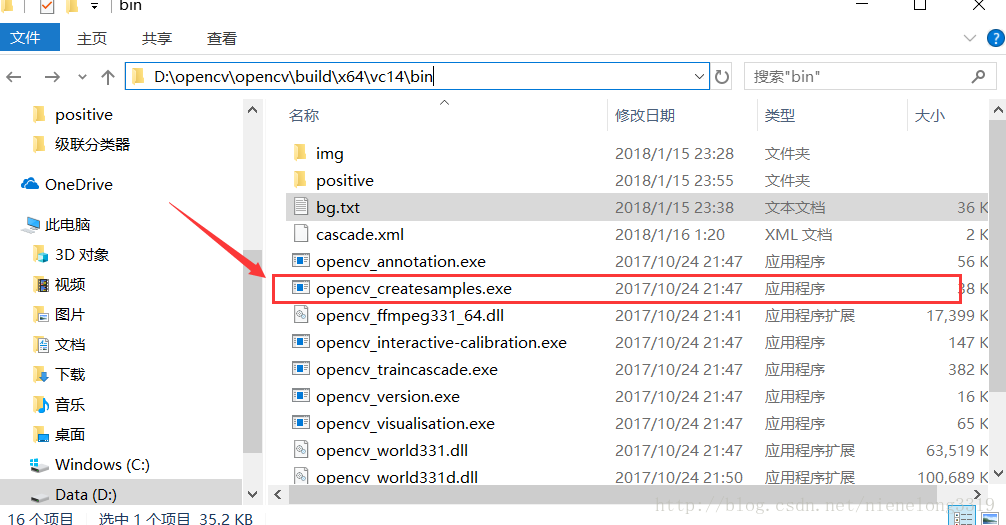
这就是生成样本的exe,win+R 输入cmd 进入该路径
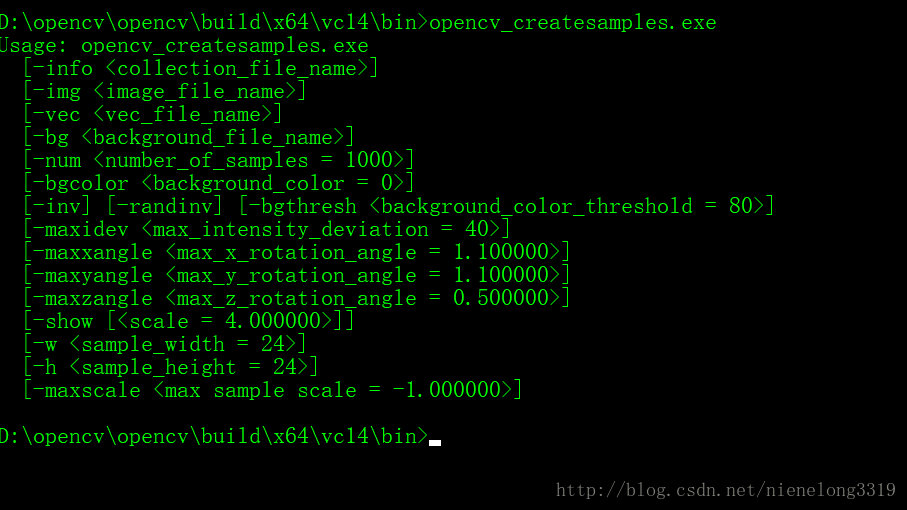
可以看到相关的一些参数 -vec 后面跟着要存放的路径 -num指的是正样本数量 -w是输出样本的宽 -h是输出样本的高 这就上面提到的 为什么可以大小不相同 一定要相同比例的问题
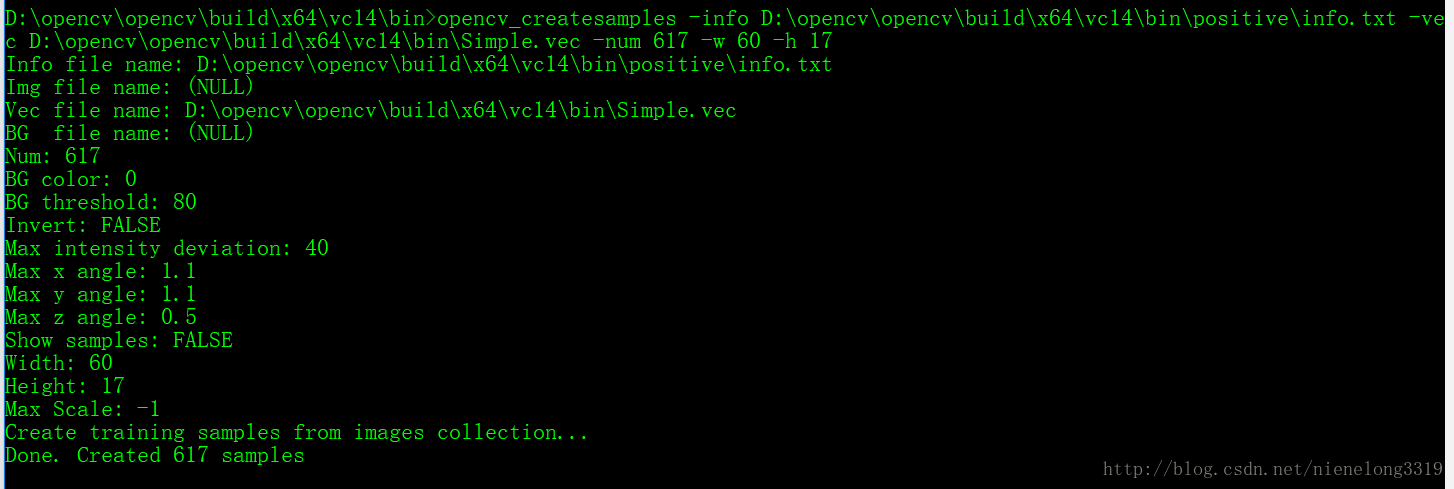
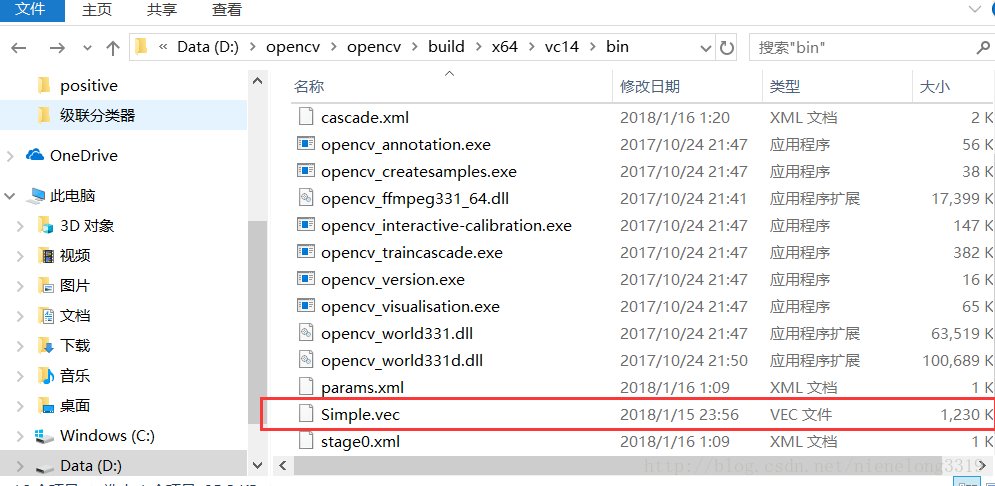
.vec文件生成 。
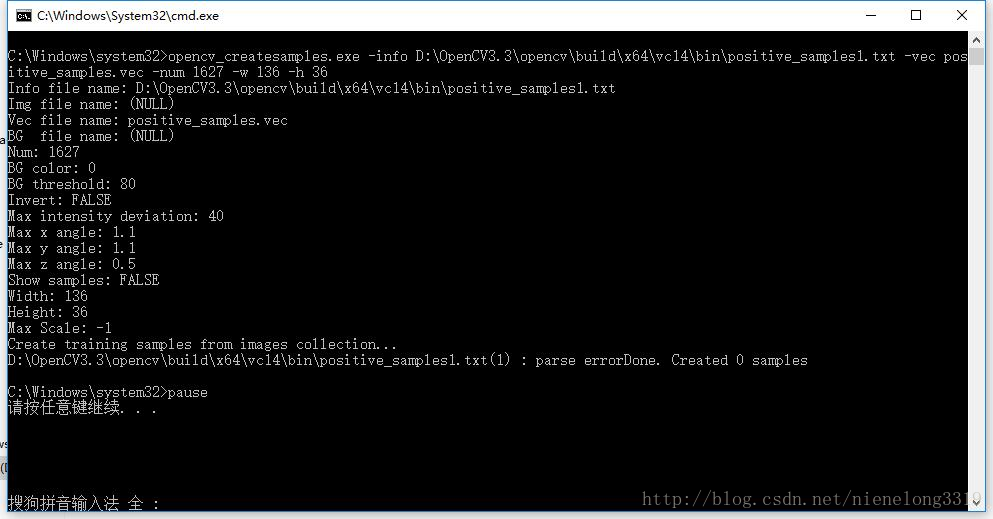
在此注意 正样本.txt需要ANSI编码,那位群友使用的C#遍历文件夹图片 使用UNICODE编码,会出现如下内容:parse errorDone. Created 0 samples 据说-num数量不对也会出现该情况
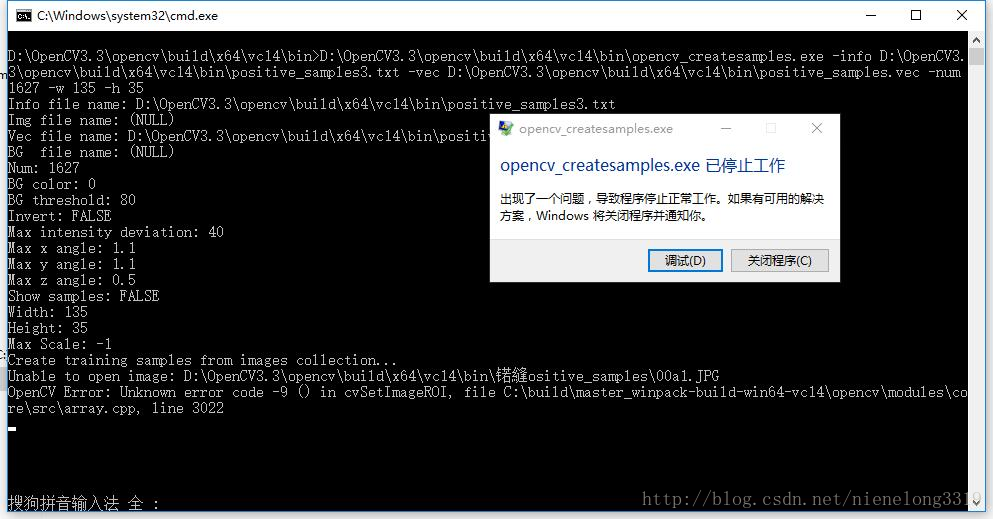
经测试 使用utf-8编码 会出现如下情况
.vec文件创建后 就是训练分类器了
训练分类器
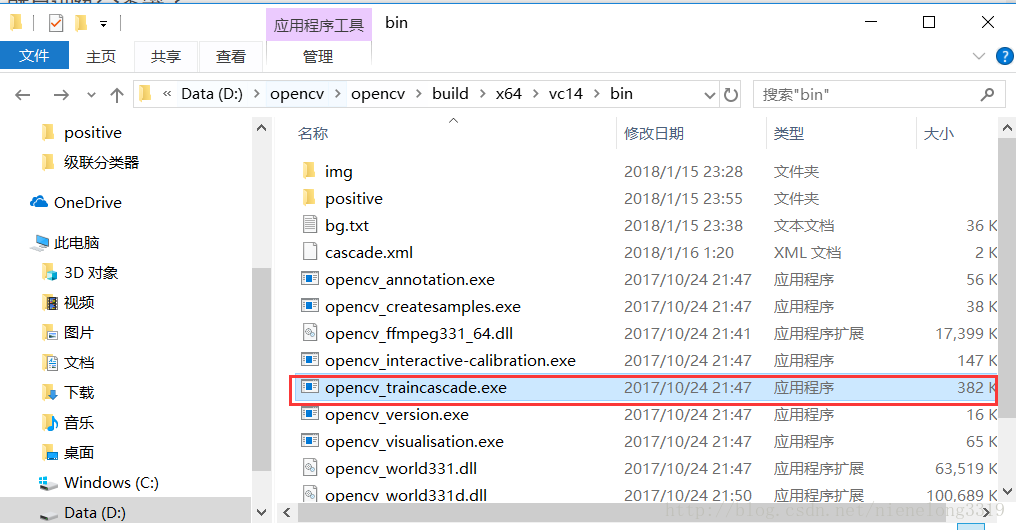
由该程序来实现,opencv2.x应该是叫haartarining.exe opencv3.x将haar和lbp整合成一个,就是上面红框标注和上面使用opencv_createsamples.exe相同 cmd 进入该目录

使用命令 -data 是存放训练好的分类器的路径 -vec 就是存放.vec的路径 -bg 负样本描述文件 -numPos 每一阶段训练的正样本数量 -numNeg 每一阶段训练的负样本数量 (网上说-numPos的参数要比实际正样本数量小,-numNeg 的参数要比实际负样本数量大 ,具体情况不太了解) -numStages 训练阶段数 (这个参数不能太大也不能太小 下面会说到) -featureType 选择LBP还是HAAR 在此选用LBP -w -h 训练样本尺寸 和vec生成的尺寸大小相同 不然会宕机 -minHitRate 最小命中率 -maxFalseAlarmRate 最大虚警率 这两个参数下面链接有说明 在此不多说http://www.mamicode.com/info-detail-1724988.html
对了 提醒一下 如果 -featureType选择HAAR 需要在加上 -mode ALL

然后就是回车 等待训练
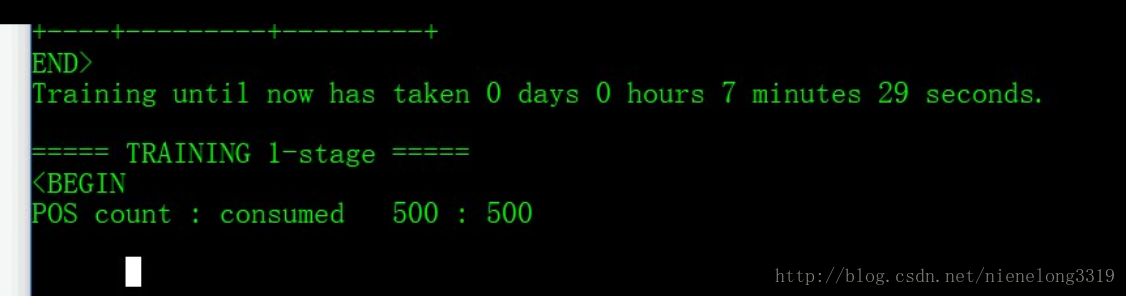
如果卡在POS这里 不要紧张 慢慢等待 我是等了十分钟左右才跳出 如果很久都没跳出 -numStages参数说明太大 改小一点 即可 当然 如果太小的话 生成的xml文档分类效果可能就不太好
当出现如下提示 表示训练完毕

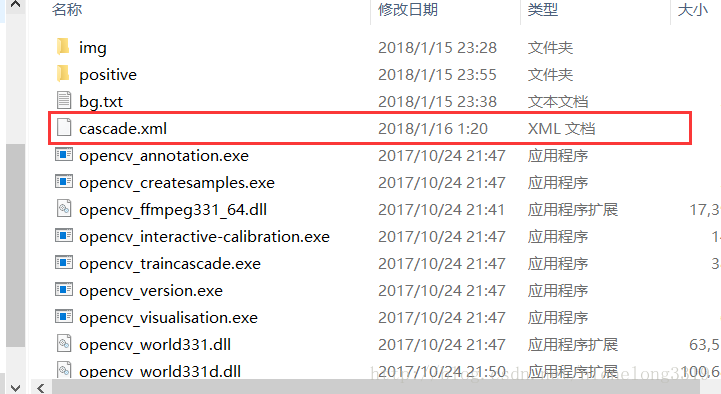
然后就可以看到一个xml文档生成 , 底下的那个stage0.xml stage1.xml params.xml是是每一阶段训练生成的xml,最终生成的cascade.xml
训练过程会有很多问题 大家多尝试 正样本负样本最好 1:3 ,1:4 比如我正样本617个 负样本2300多个
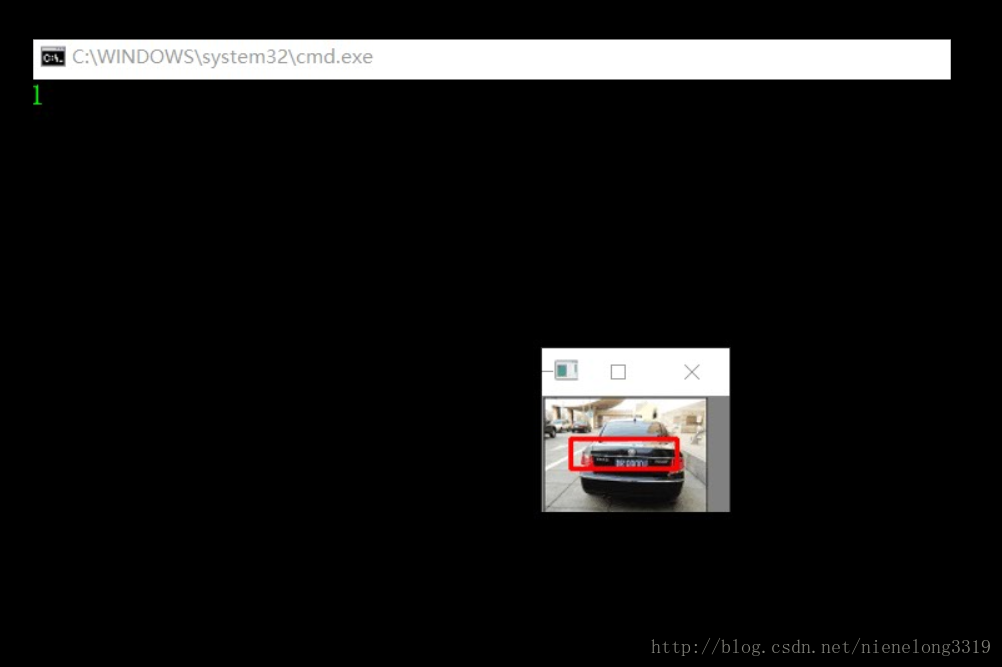
然后就是使用我们训练的xml文件了

相关文章推荐
- maven测试以及一些开发上遇到的问题
- VS2012 编译libmseed源码生成dll文件并调用中遇到的一些问题
- (转)Xtion+opencv+openni+vs2010时遇到的一些问题
- 【Oracle12C】部署服务建立用户及建库建表中遇到的问题以及12C的一些新特性
- Ionic3学习笔记(十四)使用 videogular2 实现视频播放以及遇到的一些问题
- 处理生成xml,遇到超出范围字符导致报错的问题
- 在Linux(CentOS6.2)服务器上配置hadoop时遇到的一些问题以及一些解决办法
- Android程序的反编译和防止反编译,以及操作过程中遇到的一些问题
- Dom4j解析XML中遇到的一些问题
- 一些工作中遇到的小问题,以及一些小技巧积累,慢慢更新
- evc升级到vs2005遇到的一些问题以及解决的方法
- 绿色mysql初始化以及遇到一些问题解决方法
- mysql中遇到的问题,以及一些优化对策
- 最近做网页前端项目时遇到的一些问题以及解决方案
- 生产环境使用elasticsearch遇到的一些问题以及解决方法
- 关于VS2005生成页面遇到的一些问题
- 解析xml时遇到的一些问题
- 使用elasticsearch遇到的一些问题以及解决方法(不断更新)
- opencv 创建和读取xml文件以及matlab生成xml
- github 安装配置以及使用遇到的一些问题