计算几何入门 6:凸包的构造——Graham Scan算法
2018-02-08 01:03
260 查看
上文简要分析出了凸包构造问题算法的下界:O(nlogn),在此就引入一种下界意义上最优的算法:Graham Scan算法。这种算法可以保证在最坏情况下时间复杂度也不超过nlogn。我们先大致了解一下算法的流程,然后通过一个例子深入算法的细节,最后给出理论性的分析。
Graham Scan首先要做的是一个预处理排序操作(presorting)。即找到某个基准点,然后将其余所有的点按照相对于基准点的极坐标排序。如下图:
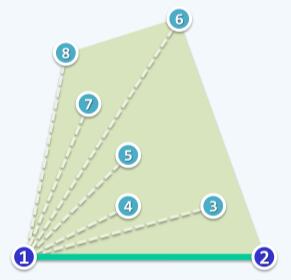
点的排序可以套用任意排序算法的框架,只是将排序对象由数值变为了平面上的点,而比较器改为to left test实现。
以点1为基准点,其余点按照相当于点1的极角依次排序为2、3、4......理论上讲任何一个点都能当第一个基准点,为了简化算法通常选择lowest-then-leftmost point(LTL)作为基准点。
然后对于与基准点1极角最小的点,也就是图中点2(假设没有三点共线的情况)。将点1和点2作为算法的起始点。
再来看Graham Scan用到的数据结构。整个算法非常简明,核心数据结构只有两个栈,分别记作栈S和栈T。便于理解我们将S和T画成开口相对的形式,如下图:
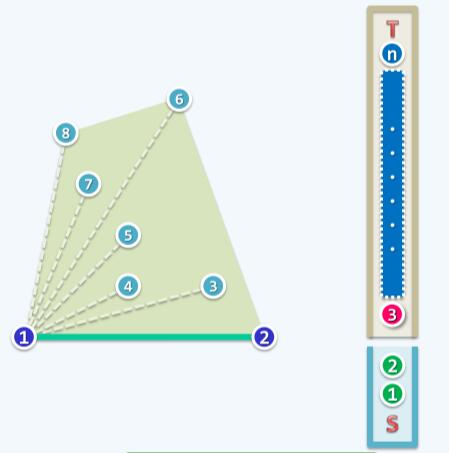
算法开始前先将起始点1和2入栈S,其他的n-2个点入栈T,如上图。注意S和T中元素的入栈顺序。至此presorting已经完成。
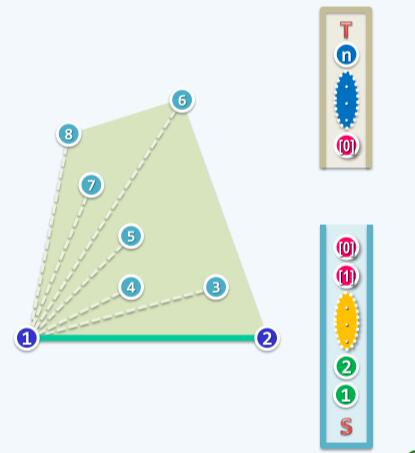
完成预处理之后,就能开始算法的核心:scan操作。scan的过程中要时刻关注三个点:栈S的栈顶(S[0])、次栈顶(S[1])和栈T的栈顶(T[0])。也就下图红色标注的三个点:
算法的总体框架为:
while( !T.empty() )
4000
//检查栈T中所有点
if ( toLeft( S[1], S[0], T[0]) ) //判断点T[0]位于边S[0]S[1]的左边还是右边,
S.push( T.pop() ); //左边则将T栈顶推入S,即向前扩展一条边
else
S.pop(); //右边则弹出S栈顶点,即回溯,将此前认为是极点的点丢弃
可以观察到,每次待处理的S[0]和S[1]构成的边一定是一条极边(如上图点1和点2),算法关键步骤就是对边这条极边和T[0]做to left test,判断T[0]位于边S[0]S[1]的左边还是右边。若在左边则继续拓展,若在右边则否定掉此前认定的极边。无论结果如何,每次判定都会将问题规模缩小一个单元,算法结束时T最终肯定为空。T空后,S中存留下的点正是凸包的极点,这些点自底而上正是凸包边界点的逆时针遍历,也得到了整个凸包构造问题的解。
先来看一个最简单的例子,即点集S中所有的点都在凸包边界上。如下图:
先找到LTL,也就是图中点1。然后基于点1对其余点按极角排序为点2、3、4......(实际上以一个点为中心的有序的点集,构成了所谓的星形多边形(star-shaped polygon),中心点正是星形多边形核(kernel)的一部分。凸多边形必然是星形多边形,反之则不然。)然后找到点1的后继2,点1和点2构成第一条极边。初始化栈S和栈T。
现在要关心S[1], S[0]和T[0],就是点1,2和3。点3位于边12左侧,to left关系为true,S.push( T.pop() ),向前拓展了一条暂定极边。
接下来重复上述过程。考虑点2,3和4。to left关系为true,S.push( T.pop() )......最终栈T空,算法结束,凸包由栈S自底向上得到。S和T的变化过程如下图:

===>

===>

===>

输入的点集S,并进行预处理排序,并初始化栈S、T,如下图:
接下来对点1,2和3进行to left测试,本质上就是判断边2→3(图中黄色边)能否被暂时采纳。测试结果为true,暂时采纳边2→3,S.push( T.pop() )。如下图所示:
注意图中蓝色边表示已经被暂时接纳的边,也就是算法暂时认定的极边。上一次操作将蓝色边推进一个单元,接下来关注点2,3和4,来判断下一条黄色边3→4能否被接纳。to left测试为true,S.push( T.pop() ),接纳边3→4。如下图右侧所示:
然后判断点3,4和5。点5在边3→4的右侧,即to left测试为false。S.pop(),也就是判断出点4不可能为极点,丢弃4。因此算法回溯到点3,判断点2,3和5的关系。5在2→3的左侧,暂时接纳边3→5,S.push( T.pop() )。如下图:
算法经历了无效操作,进行了回溯,得到了目前来说最优的“极边”。虽然这些”极边“不一定能最终保留,但问题的规模得到了削减。
下一次scan考察的就是3,5和6了。
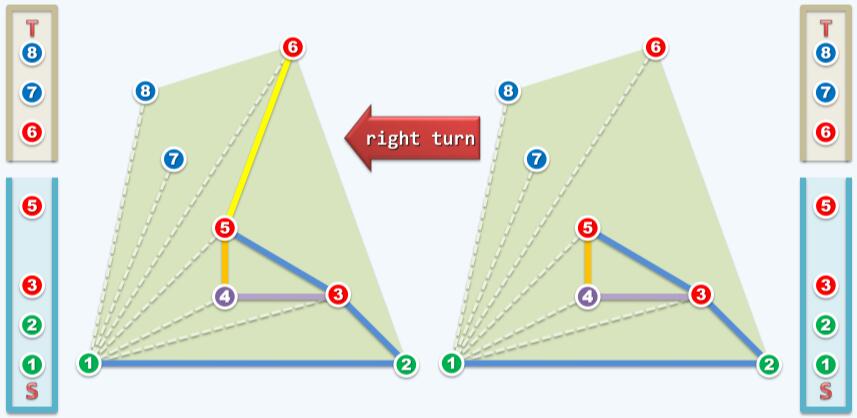
3,5和6的to left测试为false,S.pop(),舍弃点5。然后考察点2,3和6,to left测试为false,S.pop()舍弃点3。如下图:
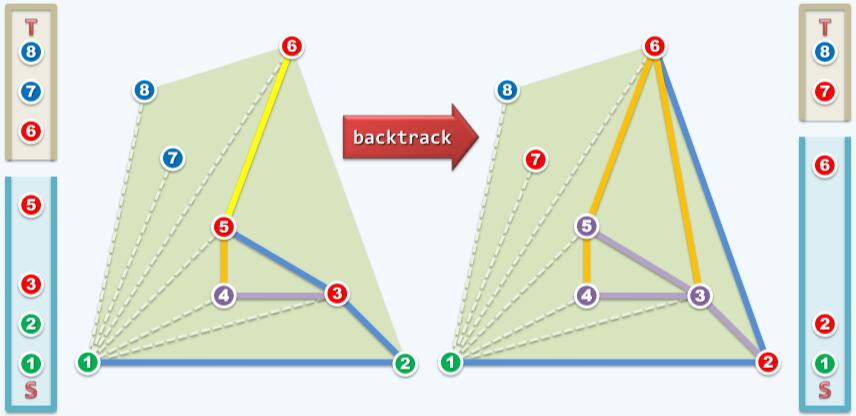
考察点2,6和7,点7在边2→6左侧,暂时接纳边6→7,S.push( T.pop() )。然后考察点6,7和8。
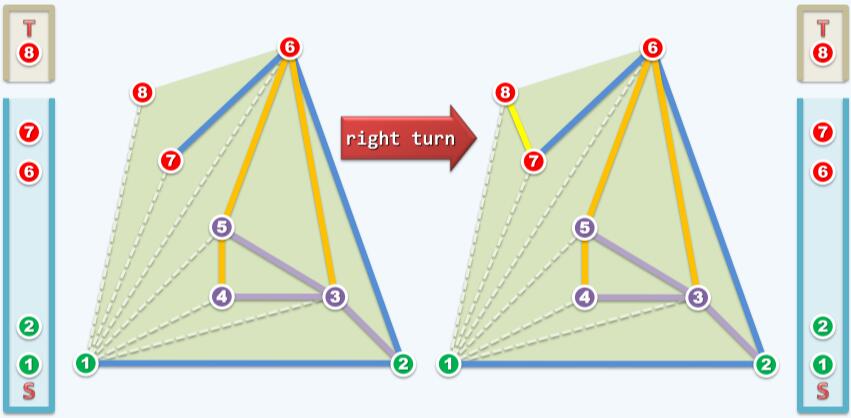
点8在边6→7右侧,S.pop(),舍弃点7。然后考察点2,6和8,如下图:
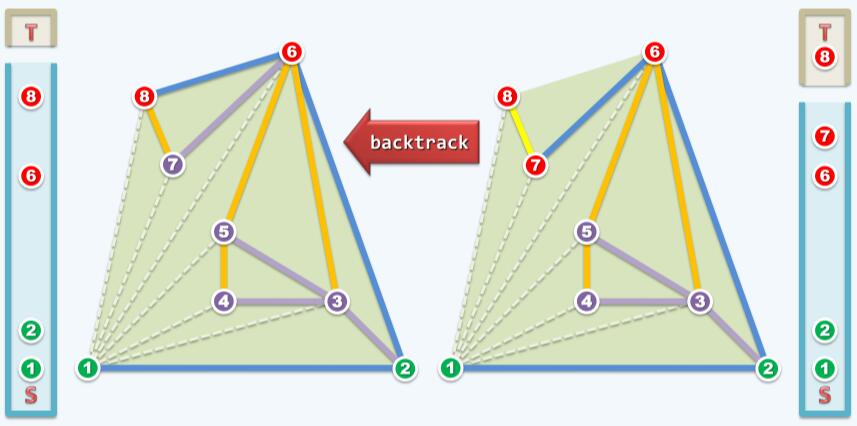
点8在边2→6左边,S.push( T.pop() ),接纳边6→8。
此时栈T已经空了,算法结束。栈S自底向上依次为1、2、6、8,也就构造出了凸包。
Graham Scan过程就是一个个引入点的过程。每当我们得到第k个点的时候,算法所得到的就是前k个点对应的“最好的凸包”。因此当k = n时得到的是整体的凸包。
归纳的第一步就是证明k = 3时得到的是当前点集S‘ = {1,2,3}中的极边,也就是证明第1张骨牌会倒。显然边1→2是S’的一条极边。而根据预处理的方式,3相较于1的极角一定小于2,因此点3一定在边1→2的左侧,因此边2→3会得到保留。对于三个点来说,任意两条边一定都是极边,2→3也是一条极边。
然后证明:假设已经处理到第k个点,得到的是前点集S' = {1,2,3,...,k}中所谓“最好的凸包”。根据算法处理方式,接下来从S'' = {1,2,3,...,k,k+1}得到的结果是否也是正确的。也就是证明第n张骨牌会倒则第n+1张骨牌也会倒下。
预处理的方式是对2-n所有点相较于点1按极角排序,因此下一个要处理点k+1一定出现在线1→k的左侧,也就是下图蓝色区域和绿色区域(假设k = 9):
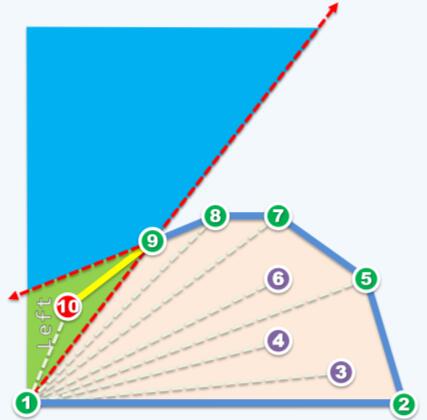
而根据目前接纳的最后一条极边 k-1→k (例如图中8→9)来划分,点k+1可能出现的区域又分为两块,即该极边的左侧(绿色区域)和右侧(蓝色区域)。这也正对应于算法判定的两个分支。
左侧的情况很简单,点k+1显然会是一个新的极点。Graham Scan要做的正是暂时接纳边k→k+1,拓展了一个新的单位。
再看k+1落在右侧的情况。如下图点10:
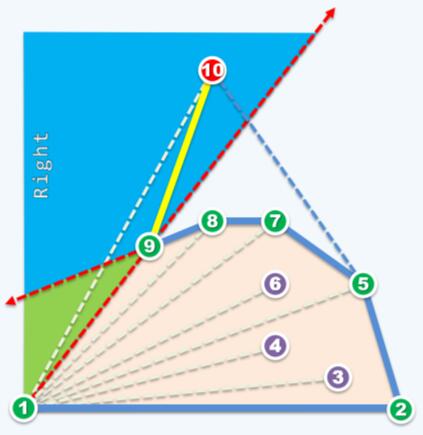
Graham Scan要做的是丢弃点k(图中点9),也就是判定出点k不可能是极点。这样做的原因:是引入点k+1后,点k一定会被包含在三角形(1, k-1, k+1)内部。如图中点9一定包含于三角形(1, 8, 10)内部。正如极点法中排除非极点的做法,点k被排除是正确的做法。接下来点k-1,k-2等(如图中点8,点7等)也可能是非极点,按照算法的流程,它们总会被判定在某个三角形的内部(例如点7在三角形(1, 5, 10)内部)而被排除,直到left test为true,回溯停止。
换个角度考虑,回溯停止时得到的新边正是增量构造法中每步得到的support line,即切线。例如图中线5→10正是算法当前保留的”凸包“的切线。这也能论证Graham Scan处理方式的正确性。
至此,算法思路上的正确性已经证明完毕。
接下来还要考虑算法的表述方式是否有漏洞:代码中每次to left test之前并没有判断S栈中是否有≥2个元素。这也可以由预处理的方式来论证。点1选取的是LTL,而点2是相对于点1极角最小的点,这样的做法保证了除了点1和点2之外所有的点一定是在边1→2左侧的。因此算法回溯最多到点2,永远不可能把点2丢弃,S中元素任何时候至少有两个。
Graham Scan算法的正确性论证完毕。
最后来思考一下预处理操作:presorting。仔细回顾上述论证过程会发现,每一步的正确性都是建立在最初的排序上的。那么这个预处理排序真的是必要的吗?可以来举极端的反例,每次选取下一个点都是随机的,例如下图的路径:
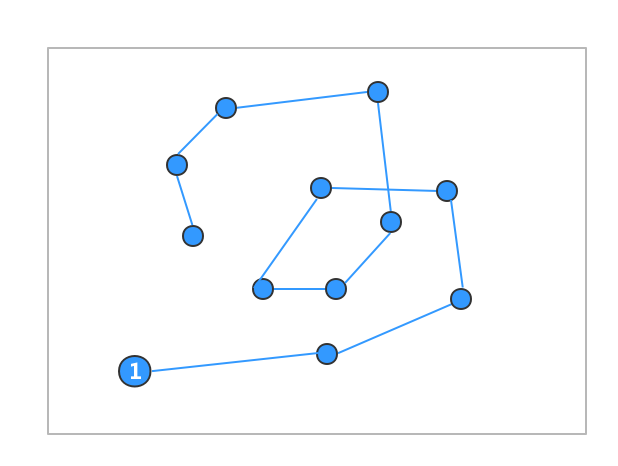
上图中从点1开始出发进行to left测试,可以发现,每次判定结果都为true,最终所有的点都被保留了下了,而显然这并不是一个凸包。因此presorting是整个算法成立的基础。
直观上无法断定Graham Scan是一个最优的算法,尤其是以下极端情况令人质疑其效率:
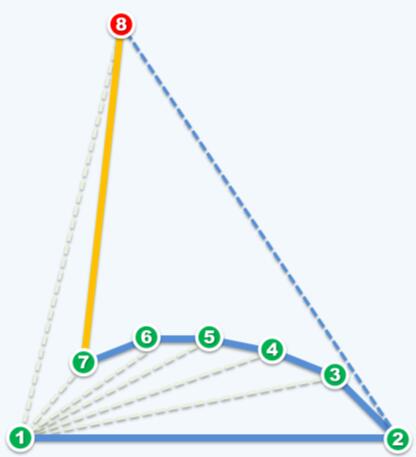
算法复杂度由三部分决定:
persorting,采用一般排序算法,复杂度是O(nlogn)
逐步迭代,O(n)
scan,O(?)
算法的总体复杂度就是O(nlogn + n * ?)。可见scan的复杂度决定了算法总体的复杂度
算法一步步纳入新点,会迭代n步。但是在每个点上都有可能做回溯操作,所以scan的复杂度是不确定的。我们来以上图最坏情况为例,到第8个点时判定为false,舍弃点7,回溯。下一步判断也为false,舍弃点6,回溯。如此回溯直到算法开始的点2。这次scan倒退了高达O(n)个点,如果每次scan都是如此那么算法整体复杂度就为:O(nlogn + n * n) = O(n^2)了,那这种算法的意义也就不大了。
其实上述分析并非错误,只是不够精确。O(n^2)确实是Graham Scan算法的一个上界,但是这个上界并不是紧的。问题就出在分析假定了每次都会出现回退高达O(n)个点。
下图展示了整个Graham Scan的流程:
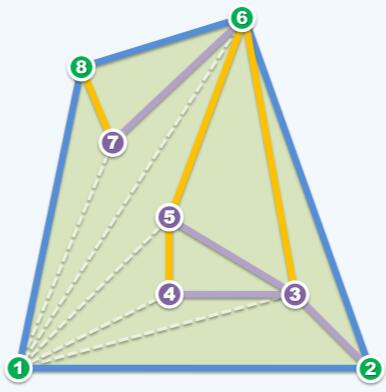
图中黄色边是没有采纳的,就是to left测试判定为false后直接舍去的。紫色边则是曾经被认为是极边而接纳的,后来经过回溯又舍去了。无论是黄边还是紫边,在其上耗费的都是常数时间,关键就在于黄色边和紫色边的数目了。
通过观察可以发现,从图论的角度看,所有的黄色边和紫色边连在一起构成了一张平面图,也就是它们互相是不可能内部相交的。平面图的一个重要性质:
平面图中所有边的数目和顶点数目保持同阶
这个性质来自欧拉公式:有n个点的平面图,边的数目上限是3n,也就是O(3n)。
根据这个性质,在persorting之后的整个流程中,Graham Scan所能走过的所有边不仅不会到达n^2,而顶多到达和n同阶的一个线性数目。因此整个算法的复杂度也就取决于persorting的O(nlogn)了。
首先再来回顾一下预处理排序,这是算法成立必不可少的一步。排序算法套用成熟的方法即可,利用数学方法计算偏角不仅复杂而且引入了误差,所以要采用to left test。要做的就是两点:
套用成熟的排序算法,将待排序元素由数值变为点
将排序算法的比较器改为to left test实现
按照这样的流程就能间接地实现persorting。
有时候我们并不是从零开始构造凸包,例如得到的待处理点集已经是有某种次序的(比如已经按x坐标大小排序,如下图)。

这种情况也不一定非得进行persorting构造新的次序,通常改变观察的角度,换一种理解方式就能免去预处理而直接进行后面的线性的scan操作了。
考虑y轴负方向无穷远一个点,所有的点相对于这个点的极角排序恰好就是各点的x坐标序!也就是将无穷远的点看作起始点①,最右侧点(图中点8)看作点②,进行scan过程直到最左边的点(图中点1)结束,就得到了凸包的上半部分(upper hull),也就是下图的8→7→2→1:
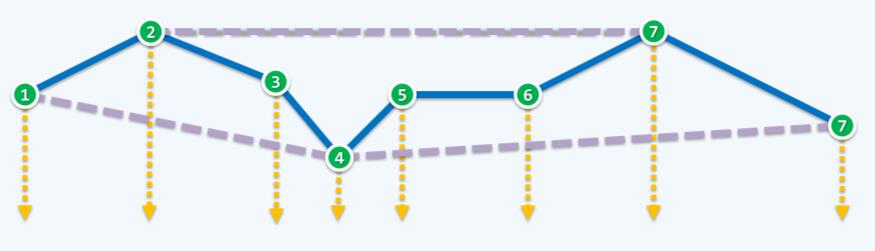
下半部分凸包(lower hull)的构造也是如此。考虑一个在y轴正方向无穷远的一个点,以此为起点进行scan,最终得到lower hull:1→4→7。最后将两个凸包合二为一即可。
本文是学堂在线课程《计算几何》的笔记,帮助理解和记录思考过程,不够严谨请见谅。
一、Graham Scan算法流程
假设待处理点集S共有n个点。Graham Scan首先要做的是一个预处理排序操作(presorting)。即找到某个基准点,然后将其余所有的点按照相对于基准点的极坐标排序。如下图:
点的排序可以套用任意排序算法的框架,只是将排序对象由数值变为了平面上的点,而比较器改为to left test实现。
以点1为基准点,其余点按照相当于点1的极角依次排序为2、3、4......理论上讲任何一个点都能当第一个基准点,为了简化算法通常选择lowest-then-leftmost point(LTL)作为基准点。
然后对于与基准点1极角最小的点,也就是图中点2(假设没有三点共线的情况)。将点1和点2作为算法的起始点。
再来看Graham Scan用到的数据结构。整个算法非常简明,核心数据结构只有两个栈,分别记作栈S和栈T。便于理解我们将S和T画成开口相对的形式,如下图:
算法开始前先将起始点1和2入栈S,其他的n-2个点入栈T,如上图。注意S和T中元素的入栈顺序。至此presorting已经完成。
完成预处理之后,就能开始算法的核心:scan操作。scan的过程中要时刻关注三个点:栈S的栈顶(S[0])、次栈顶(S[1])和栈T的栈顶(T[0])。也就下图红色标注的三个点:
算法的总体框架为:
while( !T.empty() )
4000
//检查栈T中所有点
if ( toLeft( S[1], S[0], T[0]) ) //判断点T[0]位于边S[0]S[1]的左边还是右边,
S.push( T.pop() ); //左边则将T栈顶推入S,即向前扩展一条边
else
S.pop(); //右边则弹出S栈顶点,即回溯,将此前认为是极点的点丢弃
可以观察到,每次待处理的S[0]和S[1]构成的边一定是一条极边(如上图点1和点2),算法关键步骤就是对边这条极边和T[0]做to left test,判断T[0]位于边S[0]S[1]的左边还是右边。若在左边则继续拓展,若在右边则否定掉此前认定的极边。无论结果如何,每次判定都会将问题规模缩小一个单元,算法结束时T最终肯定为空。T空后,S中存留下的点正是凸包的极点,这些点自底而上正是凸包边界点的逆时针遍历,也得到了整个凸包构造问题的解。
先来看一个最简单的例子,即点集S中所有的点都在凸包边界上。如下图:
先找到LTL,也就是图中点1。然后基于点1对其余点按极角排序为点2、3、4......(实际上以一个点为中心的有序的点集,构成了所谓的星形多边形(star-shaped polygon),中心点正是星形多边形核(kernel)的一部分。凸多边形必然是星形多边形,反之则不然。)然后找到点1的后继2,点1和点2构成第一条极边。初始化栈S和栈T。
现在要关心S[1], S[0]和T[0],就是点1,2和3。点3位于边12左侧,to left关系为true,S.push( T.pop() ),向前拓展了一条暂定极边。
接下来重复上述过程。考虑点2,3和4。to left关系为true,S.push( T.pop() )......最终栈T空,算法结束,凸包由栈S自底向上得到。S和T的变化过程如下图:
===>
===>
===>
二、举例
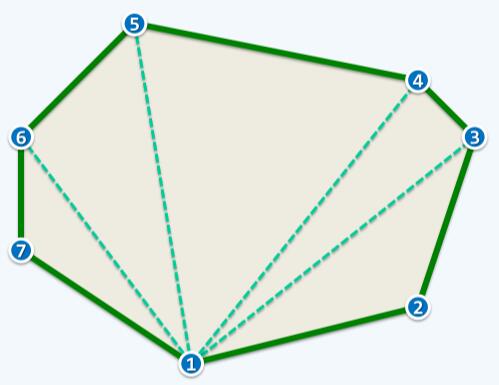
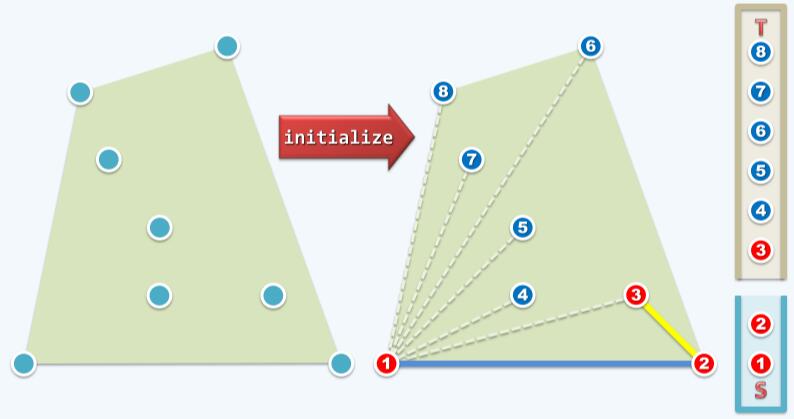
上面列举了最简单的情况下Graham Scan的过程,接下来列举一个更有代表性的实例深入算法的细节。输入的点集S,并进行预处理排序,并初始化栈S、T,如下图:
接下来对点1,2和3进行to left测试,本质上就是判断边2→3(图中黄色边)能否被暂时采纳。测试结果为true,暂时采纳边2→3,S.push( T.pop() )。如下图所示:
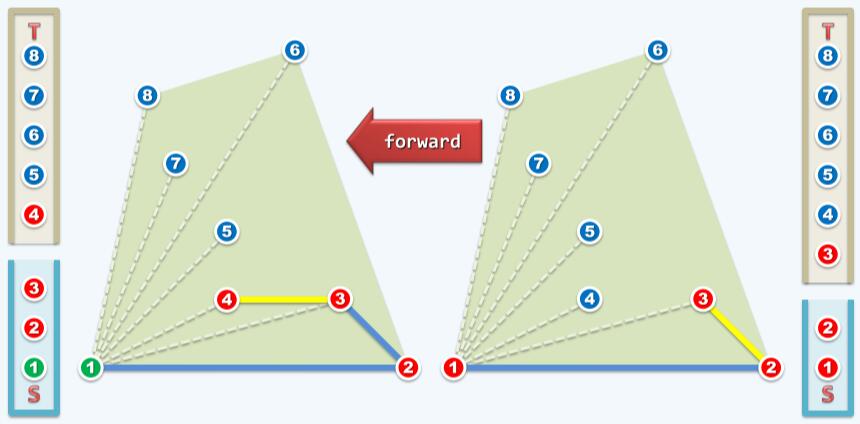
注意图中蓝色边表示已经被暂时接纳的边,也就是算法暂时认定的极边。上一次操作将蓝色边推进一个单元,接下来关注点2,3和4,来判断下一条黄色边3→4能否被接纳。to left测试为true,S.push( T.pop() ),接纳边3→4。如下图右侧所示:
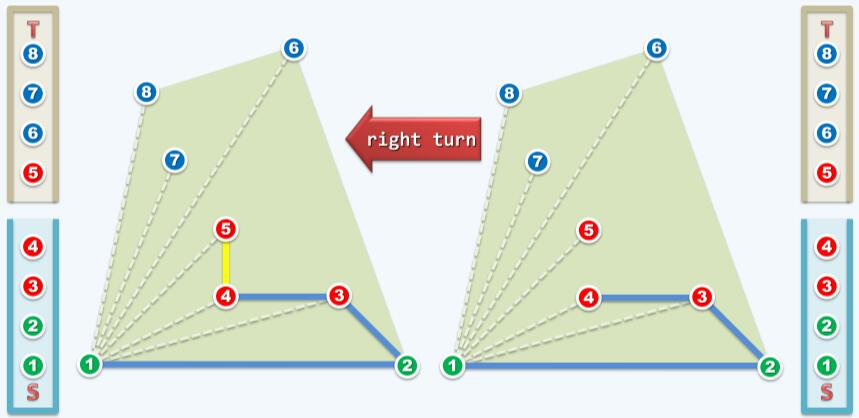
然后判断点3,4和5。点5在边3→4的右侧,即to left测试为false。S.pop(),也就是判断出点4不可能为极点,丢弃4。因此算法回溯到点3,判断点2,3和5的关系。5在2→3的左侧,暂时接纳边3→5,S.push( T.pop() )。如下图:
算法经历了无效操作,进行了回溯,得到了目前来说最优的“极边”。虽然这些”极边“不一定能最终保留,但问题的规模得到了削减。
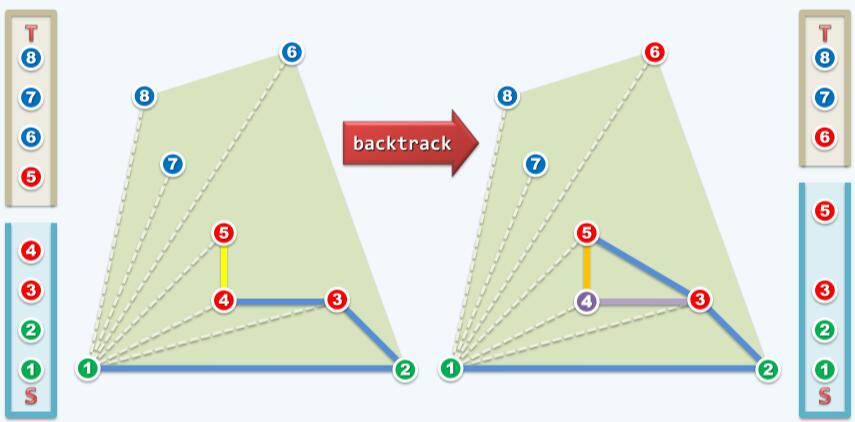
下一次scan考察的就是3,5和6了。
3,5和6的to left测试为false,S.pop(),舍弃点5。然后考察点2,3和6,to left测试为false,S.pop()舍弃点3。如下图:
考察点2,6和7,点7在边2→6左侧,暂时接纳边6→7,S.push( T.pop() )。然后考察点6,7和8。
点8在边6→7右侧,S.pop(),舍弃点7。然后考察点2,6和8,如下图:
点8在边2→6左边,S.push( T.pop() ),接纳边6→8。
此时栈T已经空了,算法结束。栈S自底向上依次为1、2、6、8,也就构造出了凸包。
三、算法正确性
了解了算法的整体流程之后,我们再来论证一下算法的正确性。证明一个算法正确性的方法有很多,在此选用数学归纳法。数学归纳法的思想可用多米诺骨牌类比,要做的无非是两件事:证明第1张骨牌会倒;证明如果第n张骨牌会倒则第n+1张骨牌也会倒下。Graham Scan过程就是一个个引入点的过程。每当我们得到第k个点的时候,算法所得到的就是前k个点对应的“最好的凸包”。因此当k = n时得到的是整体的凸包。
归纳的第一步就是证明k = 3时得到的是当前点集S‘ = {1,2,3}中的极边,也就是证明第1张骨牌会倒。显然边1→2是S’的一条极边。而根据预处理的方式,3相较于1的极角一定小于2,因此点3一定在边1→2的左侧,因此边2→3会得到保留。对于三个点来说,任意两条边一定都是极边,2→3也是一条极边。
然后证明:假设已经处理到第k个点,得到的是前点集S' = {1,2,3,...,k}中所谓“最好的凸包”。根据算法处理方式,接下来从S'' = {1,2,3,...,k,k+1}得到的结果是否也是正确的。也就是证明第n张骨牌会倒则第n+1张骨牌也会倒下。
预处理的方式是对2-n所有点相较于点1按极角排序,因此下一个要处理点k+1一定出现在线1→k的左侧,也就是下图蓝色区域和绿色区域(假设k = 9):
而根据目前接纳的最后一条极边 k-1→k (例如图中8→9)来划分,点k+1可能出现的区域又分为两块,即该极边的左侧(绿色区域)和右侧(蓝色区域)。这也正对应于算法判定的两个分支。
左侧的情况很简单,点k+1显然会是一个新的极点。Graham Scan要做的正是暂时接纳边k→k+1,拓展了一个新的单位。
再看k+1落在右侧的情况。如下图点10:
Graham Scan要做的是丢弃点k(图中点9),也就是判定出点k不可能是极点。这样做的原因:是引入点k+1后,点k一定会被包含在三角形(1, k-1, k+1)内部。如图中点9一定包含于三角形(1, 8, 10)内部。正如极点法中排除非极点的做法,点k被排除是正确的做法。接下来点k-1,k-2等(如图中点8,点7等)也可能是非极点,按照算法的流程,它们总会被判定在某个三角形的内部(例如点7在三角形(1, 5, 10)内部)而被排除,直到left test为true,回溯停止。
换个角度考虑,回溯停止时得到的新边正是增量构造法中每步得到的support line,即切线。例如图中线5→10正是算法当前保留的”凸包“的切线。这也能论证Graham Scan处理方式的正确性。
至此,算法思路上的正确性已经证明完毕。
接下来还要考虑算法的表述方式是否有漏洞:代码中每次to left test之前并没有判断S栈中是否有≥2个元素。这也可以由预处理的方式来论证。点1选取的是LTL,而点2是相对于点1极角最小的点,这样的做法保证了除了点1和点2之外所有的点一定是在边1→2左侧的。因此算法回溯最多到点2,永远不可能把点2丢弃,S中元素任何时候至少有两个。
Graham Scan算法的正确性论证完毕。
最后来思考一下预处理操作:presorting。仔细回顾上述论证过程会发现,每一步的正确性都是建立在最初的排序上的。那么这个预处理排序真的是必要的吗?可以来举极端的反例,每次选取下一个点都是随机的,例如下图的路径:
上图中从点1开始出发进行to left测试,可以发现,每次判定结果都为true,最终所有的点都被保留了下了,而显然这并不是一个凸包。因此presorting是整个算法成立的基础。
四、算法分析
上面证明了Graham Scan算法的正确性,接下来分析其复杂度是否满足O(nlogn),实现所谓的最优算法。直观上无法断定Graham Scan是一个最优的算法,尤其是以下极端情况令人质疑其效率:
算法复杂度由三部分决定:
persorting,采用一般排序算法,复杂度是O(nlogn)
逐步迭代,O(n)
scan,O(?)
算法的总体复杂度就是O(nlogn + n * ?)。可见scan的复杂度决定了算法总体的复杂度
算法一步步纳入新点,会迭代n步。但是在每个点上都有可能做回溯操作,所以scan的复杂度是不确定的。我们来以上图最坏情况为例,到第8个点时判定为false,舍弃点7,回溯。下一步判断也为false,舍弃点6,回溯。如此回溯直到算法开始的点2。这次scan倒退了高达O(n)个点,如果每次scan都是如此那么算法整体复杂度就为:O(nlogn + n * n) = O(n^2)了,那这种算法的意义也就不大了。
其实上述分析并非错误,只是不够精确。O(n^2)确实是Graham Scan算法的一个上界,但是这个上界并不是紧的。问题就出在分析假定了每次都会出现回退高达O(n)个点。
下图展示了整个Graham Scan的流程:
图中黄色边是没有采纳的,就是to left测试判定为false后直接舍去的。紫色边则是曾经被认为是极边而接纳的,后来经过回溯又舍去了。无论是黄边还是紫边,在其上耗费的都是常数时间,关键就在于黄色边和紫色边的数目了。
通过观察可以发现,从图论的角度看,所有的黄色边和紫色边连在一起构成了一张平面图,也就是它们互相是不可能内部相交的。平面图的一个重要性质:
平面图中所有边的数目和顶点数目保持同阶
这个性质来自欧拉公式:有n个点的平面图,边的数目上限是3n,也就是O(3n)。
根据这个性质,在persorting之后的整个流程中,Graham Scan所能走过的所有边不仅不会到达n^2,而顶多到达和n同阶的一个线性数目。因此整个算法的复杂度也就取决于persorting的O(nlogn)了。
五、算法推广*
Graham Scan算法不仅可以用于凸包构造问题,在其他许多场景下中也十分有效。为了推广Graham Scan算法,首先可以对其做简化,以方便利用在其他问题。首先再来回顾一下预处理排序,这是算法成立必不可少的一步。排序算法套用成熟的方法即可,利用数学方法计算偏角不仅复杂而且引入了误差,所以要采用to left test。要做的就是两点:
套用成熟的排序算法,将待排序元素由数值变为点
将排序算法的比较器改为to left test实现
按照这样的流程就能间接地实现persorting。
有时候我们并不是从零开始构造凸包,例如得到的待处理点集已经是有某种次序的(比如已经按x坐标大小排序,如下图)。
这种情况也不一定非得进行persorting构造新的次序,通常改变观察的角度,换一种理解方式就能免去预处理而直接进行后面的线性的scan操作了。
考虑y轴负方向无穷远一个点,所有的点相对于这个点的极角排序恰好就是各点的x坐标序!也就是将无穷远的点看作起始点①,最右侧点(图中点8)看作点②,进行scan过程直到最左边的点(图中点1)结束,就得到了凸包的上半部分(upper hull),也就是下图的8→7→2→1:
下半部分凸包(lower hull)的构造也是如此。考虑一个在y轴正方向无穷远的一个点,以此为起点进行scan,最终得到lower hull:1→4→7。最后将两个凸包合二为一即可。
本文是学堂在线课程《计算几何》的笔记,帮助理解和记录思考过程,不够严谨请见谅。

相关文章推荐
- 计算几何入门 2:凸包的构造——极点法和极边法
- 计算几何入门 4:凸包的构造——Jarvis March算法
- POJ1113---Wall(基础计算几何:凸包入门)
- poj 2187 计算几何入门题 凸包
- FZU 2148 moon game (计算几何判断凸包)
- 【转载】POJ 计算几何入门题目推荐
- 计算几何-经典算法-凸包
- HDU 4449 Building Design 第37届ACM/ICPC 金华赛区H题 (计算几何,三维凸包+空间坐标旋转+二维凸包)
- SGU 253 计算几何 判定点是否在凸包内
- 计算几何之凸包_卷包裹算法
- POJ 计算几何入门题目推荐(转)
- UVA 11168 (计算几何 凸包)
- 计算几何入门2--poj2653Pick-up sticks
- 【HDU5563 BestCoder Round 62 (div1)A】【计算几何 凸包】Clarke and five-pointed star 正五边形判定 正五角星判定
- 二维计算几何模板--多边形/凸包
- 【BZOJ1069】【SCOI2007】最大土地面积 计算几何 凸包
- uva 10652 凸包 + 更新版计算几何模板
- 计算几何--凸包--Andrew算法--HDU1392
- Gym 101243.I - Land Division Gym - 101243I(计算几何 切割凸包)
- bzoj2829: 信用卡凸包 计算几何 凸包