关联分析
2018-02-06 20:56
113 查看
关联分析
1、事务:每一条交易称为一个事务,例如示例1中的数据集就包含四个事务。
2、项:交易的每一个物品称为一个项,例如Cola、Egg等。
3、项集:包含零个或多个项的集合叫做项集,例如{Cola, Egg, Ham}。
4、k−项集:包含k个项的项集叫做k-项集,例如{Cola}叫做1-项集,{Cola, Egg}叫做2-项集。
5、支持度计数:一个项集出现在几个事务当中,它的支持度计数就是几。例如{Diaper, Beer}出现在事务 002、003和004中,所以它的支持度计数是3。
6、支持度:支持度计数除于总的事务数。例如上例中总的事务数为4,{Diaper, Beer}的支持度计数为3,所以它的支持度是3÷4=75%,说明有75%的人同时买了Diaper和Beer。
7、频繁项集:支持度大于或等于某个阈值的项集就叫做频繁项集。例如阈值设为50%时,因为{Diaper, Beer}的支持度是75%,所以它是频繁项集。
8、前件和后件:对于规则{Diaper}→{Beer},{Diaper}叫做前件,{Beer}叫做后件。
9、置信度:对于规则{Diaper}→{Beer},{Diaper, Beer}的支持度计数除于{Diaper}的支持度计数,为这个规则的置信度。例如规则{Diaper}→{Beer}的置信度为3÷3=100%。说明买了Diaper的人100%也买了Beer。
10、强关联规则:大于或等于最小支持度阈值和最小置信度阈值的规则叫做强关联规则。关联分析的最终目标就是要找出强关联规则。
11、频繁K项集:满足最小支持度阈值的K项集合。
12、候选K项集:通过连接形成的K项集合。
交易号码 商品
0 豆奶,莴苣
1 莴苣,尿布,葡萄酒,甜菜
2 豆奶,尿布,葡萄酒,橙汁
3 莴苣,豆奶,尿布,葡萄酒
4 莴苣,豆奶,尿布,橙汁
一个项集的 支持度 被定义数据集中包含该项集的记录所占的比例。
如上图中,{豆奶}的支持度为4/5,{豆奶,尿布}的支持度为3/5。
支持度是针对项集来说的,因此可以定义一个最小支持度,而只保留满足最小值尺度的项集。
可信度或置信度(confidence)是针对关联规则来定义的。
规则{尿布}➞{啤酒}的可信度被定义为"支持度({尿布,啤酒})/支持度({尿布})",
由于{尿布,啤酒}的支持度为3/5,尿布的支持度为4/5,所以"尿布➞啤酒"的可信度为3/4。
这意味着对于包含"尿布"的所有记录,我们的规则对其中75%的记录都适用。
1)Apriori算法
Apriori原理是说如果某个项集是频繁的,那么它的所有子集也是频繁的。更常用的是它的逆否命题,即如果一个项集是非频繁的,那么它的所有超集也是非频繁的。
步骤:
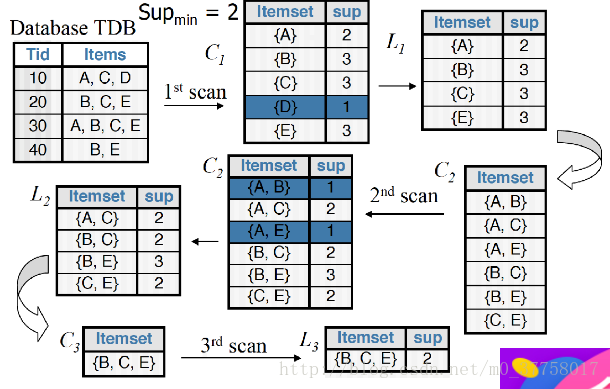
1.先计算1项集的支持度,筛选出频繁1项集。
2.然后排列组合出2项集,计算出2项集的支持度,筛选出频繁2项集。
3.然后通过连接和剪枝计算出3项集,计算出3项集的支持度,筛选出频繁3项集。
4.然后依次类推处理K项集,直到没有频繁集出现(具体例子参考首图)。
优点:
使用先验性质,大大提高了频繁项集逐层产生的效率;简单易理解;数据集要求低
缺点:
1、候选频繁K项集数量巨大。
2、在验证候选频繁K项集的时候,需要对整个数据库进行扫描,非常耗时。
2)FP-growth算法
参考:http://blog.csdn.net/huagong_adu/article/details/17739247
思想和算法步骤:遍历数据集中每个元素,获得每个元素出现的次数,然后根据元素出现的频率,去掉不满足最小支持度的元素项。获得过滤后的频繁项集,然后开始构建FP树。
构建BP树的过程就是向树中添加频繁项集的过程,这就需要第二次遍历数据集,遍历数据集中元素时,这是只考虑频繁项集,对每个频繁项根据支持度递减的次序进行排序,然后使用排序后的频繁项集进行对树的填充,
填充过程为:首先建一个空树,当遍历第一组频繁项集时,将所有项集填入树中,作为树的子节点(添的时候从上到下依次添入,比如下图中第一步add{z,r}),
然后,再填入下一组频繁项集时,对每个频繁项有:遍历树中的每个元素,从上到下,从左到右,如果该频繁项已存在树的子节点中,只需将该子节点的频繁项数加1即可,
如果该频繁项不存在树的子节点中,就将该频繁项添加到树中,作为新的子节点,接下来添加频繁项组的过程跟上述一样,直到将所有频繁项都添加到FP树中。
应用场景:
优化货架商品摆放,或优化邮寄商品目录的内容
交叉销售和捆绑销售
异常识别等
优点:只进行2次数据集扫描而且不使用候选集,直接压缩数据集成一个频繁模式树(FP树),最后通过这个FP树生成频繁项集
缺点:不适用于数据量很大情况
1、事务:每一条交易称为一个事务,例如示例1中的数据集就包含四个事务。
2、项:交易的每一个物品称为一个项,例如Cola、Egg等。
3、项集:包含零个或多个项的集合叫做项集,例如{Cola, Egg, Ham}。
4、k−项集:包含k个项的项集叫做k-项集,例如{Cola}叫做1-项集,{Cola, Egg}叫做2-项集。
5、支持度计数:一个项集出现在几个事务当中,它的支持度计数就是几。例如{Diaper, Beer}出现在事务 002、003和004中,所以它的支持度计数是3。
6、支持度:支持度计数除于总的事务数。例如上例中总的事务数为4,{Diaper, Beer}的支持度计数为3,所以它的支持度是3÷4=75%,说明有75%的人同时买了Diaper和Beer。
7、频繁项集:支持度大于或等于某个阈值的项集就叫做频繁项集。例如阈值设为50%时,因为{Diaper, Beer}的支持度是75%,所以它是频繁项集。
8、前件和后件:对于规则{Diaper}→{Beer},{Diaper}叫做前件,{Beer}叫做后件。
9、置信度:对于规则{Diaper}→{Beer},{Diaper, Beer}的支持度计数除于{Diaper}的支持度计数,为这个规则的置信度。例如规则{Diaper}→{Beer}的置信度为3÷3=100%。说明买了Diaper的人100%也买了Beer。
10、强关联规则:大于或等于最小支持度阈值和最小置信度阈值的规则叫做强关联规则。关联分析的最终目标就是要找出强关联规则。
11、频繁K项集:满足最小支持度阈值的K项集合。
12、候选K项集:通过连接形成的K项集合。
交易号码 商品
0 豆奶,莴苣
1 莴苣,尿布,葡萄酒,甜菜
2 豆奶,尿布,葡萄酒,橙汁
3 莴苣,豆奶,尿布,葡萄酒
4 莴苣,豆奶,尿布,橙汁
一个项集的 支持度 被定义数据集中包含该项集的记录所占的比例。
如上图中,{豆奶}的支持度为4/5,{豆奶,尿布}的支持度为3/5。
支持度是针对项集来说的,因此可以定义一个最小支持度,而只保留满足最小值尺度的项集。
可信度或置信度(confidence)是针对关联规则来定义的。
规则{尿布}➞{啤酒}的可信度被定义为"支持度({尿布,啤酒})/支持度({尿布})",
由于{尿布,啤酒}的支持度为3/5,尿布的支持度为4/5,所以"尿布➞啤酒"的可信度为3/4。
这意味着对于包含"尿布"的所有记录,我们的规则对其中75%的记录都适用。
1)Apriori算法
Apriori原理是说如果某个项集是频繁的,那么它的所有子集也是频繁的。更常用的是它的逆否命题,即如果一个项集是非频繁的,那么它的所有超集也是非频繁的。
步骤:
1.先计算1项集的支持度,筛选出频繁1项集。
2.然后排列组合出2项集,计算出2项集的支持度,筛选出频繁2项集。
3.然后通过连接和剪枝计算出3项集,计算出3项集的支持度,筛选出频繁3项集。
4.然后依次类推处理K项集,直到没有频繁集出现(具体例子参考首图)。
优点:
使用先验性质,大大提高了频繁项集逐层产生的效率;简单易理解;数据集要求低
缺点:
1、候选频繁K项集数量巨大。
2、在验证候选频繁K项集的时候,需要对整个数据库进行扫描,非常耗时。
2)FP-growth算法
参考:http://blog.csdn.net/huagong_adu/article/details/17739247
思想和算法步骤:遍历数据集中每个元素,获得每个元素出现的次数,然后根据元素出现的频率,去掉不满足最小支持度的元素项。获得过滤后的频繁项集,然后开始构建FP树。
构建BP树的过程就是向树中添加频繁项集的过程,这就需要第二次遍历数据集,遍历数据集中元素时,这是只考虑频繁项集,对每个频繁项根据支持度递减的次序进行排序,然后使用排序后的频繁项集进行对树的填充,
填充过程为:首先建一个空树,当遍历第一组频繁项集时,将所有项集填入树中,作为树的子节点(添的时候从上到下依次添入,比如下图中第一步add{z,r}),
然后,再填入下一组频繁项集时,对每个频繁项有:遍历树中的每个元素,从上到下,从左到右,如果该频繁项已存在树的子节点中,只需将该子节点的频繁项数加1即可,
如果该频繁项不存在树的子节点中,就将该频繁项添加到树中,作为新的子节点,接下来添加频繁项组的过程跟上述一样,直到将所有频繁项都添加到FP树中。
应用场景:
优化货架商品摆放,或优化邮寄商品目录的内容
交叉销售和捆绑销售
异常识别等
优点:只进行2次数据集扫描而且不使用候选集,直接压缩数据集成一个频繁模式树(FP树),最后通过这个FP树生成频繁项集
缺点:不适用于数据量很大情况

相关文章推荐
- Weka有时候关联分析的"Start"按钮式灰色的
- 数据挖掘:Top 10 Algorithms in Data Mining(四)Apriori 关联分析
- 数据科学之机器学习14: 关联分析之apriori算法
- SAS->关联分析实践
- SEAndroid安全机制中的文件安全上下文关联分析
- 使用Apriori算法进行关联分析
- Activity启动模式 及 Intent Flags 与 栈 的关联分析
- 关联分析——Apriori算法
- 使用Apriori算法进行关联分析
- 使用Apriori算法进行关联分析
- 关联分析(二)
- Apriori算法——关联分析
- 机器学习——使用Apriori算法进行关联分析
- 典型关联分析CCA
- Apriori关联分析与FP-growth挖掘频繁项集
- Python3.6-Apriori算法进行关联分析
- 机器学习实战笔记-使用Apriori算法进行关联分析
- 利用SQL Server进行关联分析
- 安全设备日志关联分析技术
- 关联分析中可能的规则数的求法