爬取搜索出来的电影的下载地址并保存到excel
2018-02-06 18:12
507 查看
一、背景
利用Requests模块获取页面,BeautifulSoup来获取需要的内容,最后利用xlsxwriter模块讲内容保存至excel,首先通过讲关键字收拾出来的页面获取到子页面的url,然后再次去抓取获取到子页面的信息保存到excel二、代码
编写了两个模块,geturldytt和getexceldytt,最后在main内调用
git源码地址
geturldyttd代码如下:
#!/bin/env python
# -*- coding:utf-8 -*-
from urllib import parse
import requests
from bs4 import BeautifulSoup
#http://s.dydytt.net/plus/search.php?keyword=%BF%C6%BB%C3&searchtype=titlekeyword&channeltype=0&orderby=&kwtype=0&pagesize=10&typeid=0&TotalResult=279&PageNo=4
class get_urldic:
def __init__(self):
self.first_url = 'http://s.dydytt.net/plus/search.php?'
self.second_url = '&searchtype=titlekeyword&channeltype=0&orderby=&kwtype=0&pagesize=10&typeid=0&TotalResult=279&PageNo='
self.info_url = 'http://s.dydytt.net'
#获取搜索关键字
def get_url(self):
urlList = []
# first_url = 'http://s.dydytt.net/plus/search.php?'
# second_url = '&searchtype=titlekeyword&channeltype=0&orderby=&kwtype=0&pagesize=10&typeid=0&TotalResult=279&PageNo='
try:
search = input("Please input search name:")
dic = {'keyword':search}
keyword_dic = parse.urlencode(dic,encoding='gb2312')
page = int(input("Please input page:"))
except Exception as e:
print('Input error:',e)
exit()
for num in range(1,page+1):
url = self.first_url + str(keyword_dic) + self.second_url + str(num)
urlList.append(url)
print("Please wait....")
print(urlList)
return urlList,search
#获取网页文件
def get_html(self,urlList):
response_list = []
for r_num in urlList:
request = requests.get(r_num)
response = request.content.decode('gbk','ignore').encode('utf-8')
response_list.append(response)
return response_list
#获取blog_name和blog_url
def get_soup(self,html_doc):
result = {}
for g_num in html_doc:
soup = BeautifulSoup(g_num,'html.parser')
context = soup.find_all('td', width="55%")
for i in context:
title=i.get_text()
result[title.strip()]=self.info_url + i.b.a['href']
return result
def get_info(self,info_dic):
info_tmp = []
for k,v in info_dic.items():
print(v)
response = requests.get(v)
new_response = response.content.decode('gbk').encode('utf-8')
soup = BeautifulSoup(new_response, 'html.parser')
info_dic = soup.find_all('div', class_="co_content8")
info_list1= []
for context in info_dic:
result = list(context.get_text().split())
for i in range(0, len(result)):
if '发布' in result[i]:
public = result[i]
info_list1.append(public)
elif "豆瓣" in result[i]:
douban = result[i] + result[i+1]
info_list1.append(douban)
elif "【下载地址】" in result[i]:
download = result[i] + result[i+1]
info_list1.append(download)
else:
pass
info_tmp.append(info_list1)
return info_tmp
if __name__ == '__main__':
blog = get_urldic()
urllist, search = blog.get_url()
html_doc = blog.get_html(urllist)
result = blog.get_soup(html_doc)
for k,v in result.items():
print('search blog_name is:%s,blog_url is:%s' % (k,v))
info_list = blog.get_info(result)
for list in info_list:
print(list)getexceldytt代码如下:
#!/bin/env python
# -*- coding:utf-8 -*-
# @Author : kaliarch
import xlsxwriter
class create_excle:
def __init__(self):
self.tag_list = ["movie_name", "movie_url"]
self.info = "information"
def create_workbook(self,search=" "):
excle_name = search + '.xlsx'
#定义excle名称
workbook = xlsxwriter.Workbook(excle_name)
worksheet_M = workbook.add_worksheet(search)
worksheet_info = workbook.add_worksheet(self.info)
print('create %s....' % excle_name)
return workbook,worksheet_M,worksheet_info
def col_row(self,worksheet):
worksheet.set_column('A:A', 12)
worksheet.set_row(0, 17)
worksheet.set_column('A:A',58)
worksheet.set_column('B:B', 58)
def shell_format(self,workbook):
#表头格式
merge_format = workbook.add_format({
'bold': 1,
'border': 1,
'align': 'center',
'valign': 'vcenter',
'fg_color': '#FAEBD7'
})
#标题格式
name_format = workbook.add_format({
'bold': 1,
'border': 1,
'align': 'center',
'valign': 'vcenter',
'fg_color': '#E0FFFF'
})
#正文格式
normal_format = workbook.add_format({
'align': 'center',
})
return merge_format,name_format,normal_format
#写入title和列名
def write_title(self,worksheet,search,merge_format):
title = search + "搜索结果"
worksheet.merge_range('A1:B1', title, merge_format)
print('write title success')
def write_tag(self,worksheet,name_format):
tag_row = 1
tag_col = 0
for num in self.tag_list:
worksheet.write(tag_row,tag_col,num,name_format)
tag_col += 1
print('write tag success')
#写入内容
def write_context(self,worksheet,con_dic,normal_format):
row = 2
for k,v in con_dic.items():
if row > len(con_dic):
break
col = 0
worksheet.write(row,col,k,normal_format)
col+=1
worksheet.write(row,col,v,normal_format)
row+=1
print('write context success')
#写入子页面详细内容
def write_info(self,worksheet_info,info_list,normal_format):
row = 1
for infomsg in info_list:
for num in range(0,len(infomsg)):
worksheet_info.write(row,num,infomsg[num],normal_format)
num += 1
row += 1
print("wirte info success")
#关闭excel
def workbook_close(self,workbook):
workbook.close()
if __name__ == '__main__':
print('This is create excel mode')main代码如下:
#!/bin/env python # -*- coding:utf-8 -*- import geturldytt import getexceldytt #获取url字典 def get_dic(): blog = geturldytt.get_urldic() urllist, search = blog.get_url() html_doc = blog.get_html(urllist) result = blog.get_soup(html_doc) info_list= blog.get_info(result) return result,search,info_list #写入excle def write_excle(urldic,search,info_list): excle = getexceldytt.create_excle() workbook, worksheet, worksheet_info = excle.create_workbook(search) excle.col_row(worksheet) merge_format, name_format, normal_format = excle.shell_format(workbook) excle.write_title(worksheet,search,merge_format) excle.write_tag(worksheet,name_format) excle.write_context(worksheet,urldic,normal_format) excle.write_info(worksheet_info,info_list,normal_format) excle.workbook_close(workbook) def main(): url_dic ,search_name, info_list = get_dic() write_excle(url_dic,search_name,info_list) if __name__ == '__main__': main()
三、效果展示
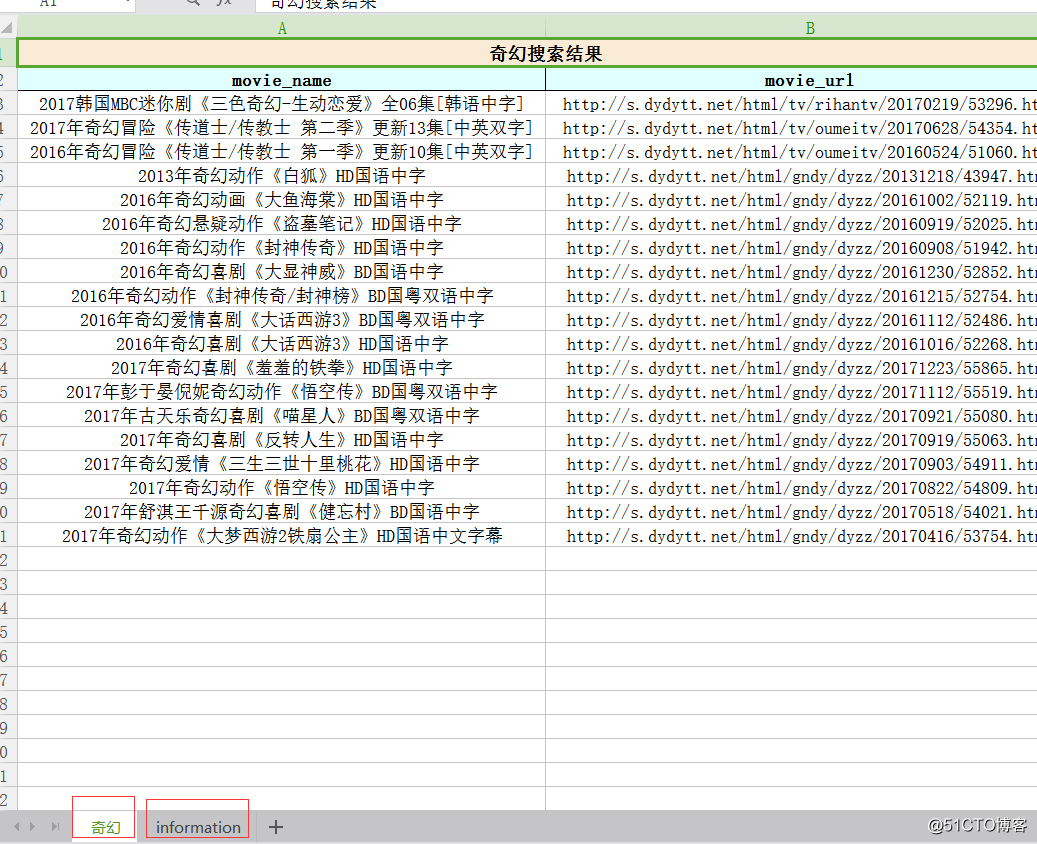
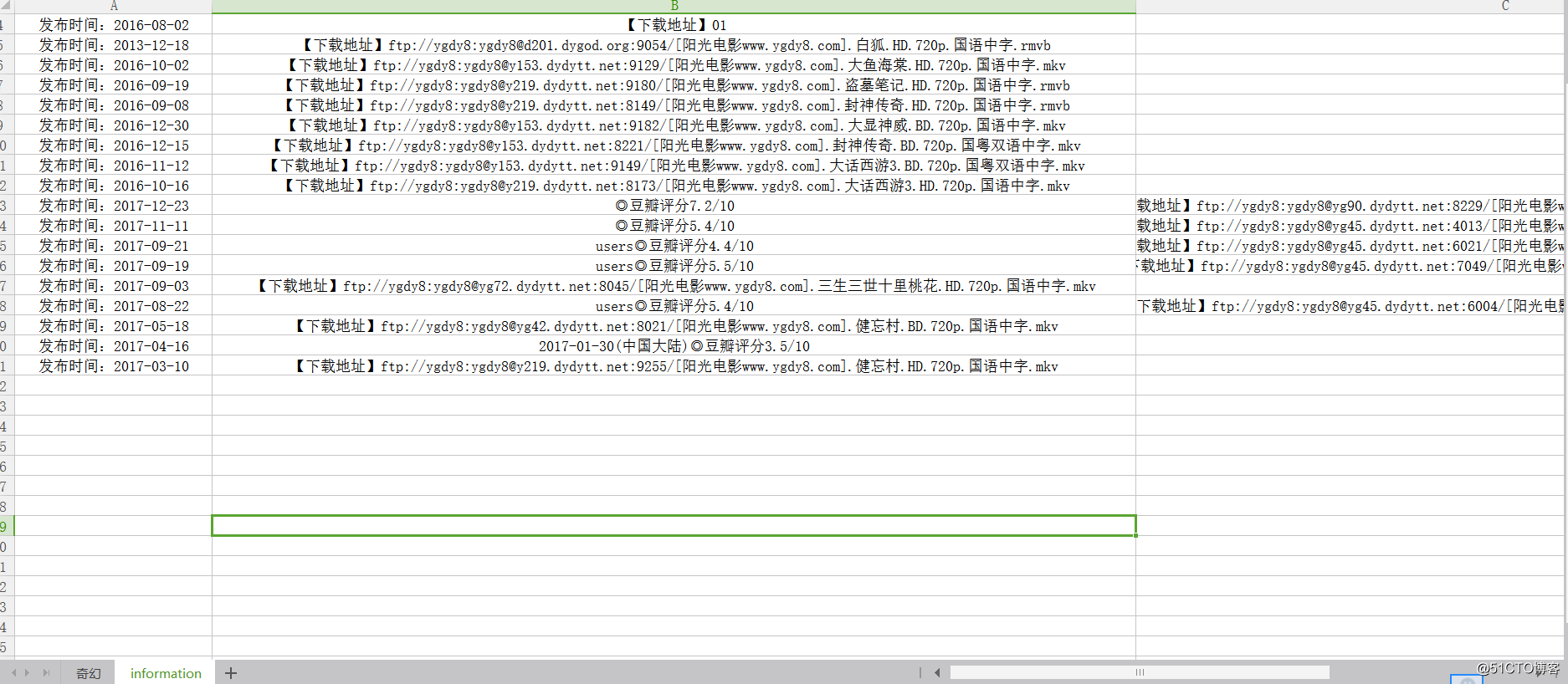
运行代码,填写搜索的关键字,及搜索多少页,生成excel的sheet1内容为首先搜索的页面及url,sheet2为sheet1内url对应的电影下载链接及豆瓣评分,有的子页面存在没有豆瓣评分或下载链接。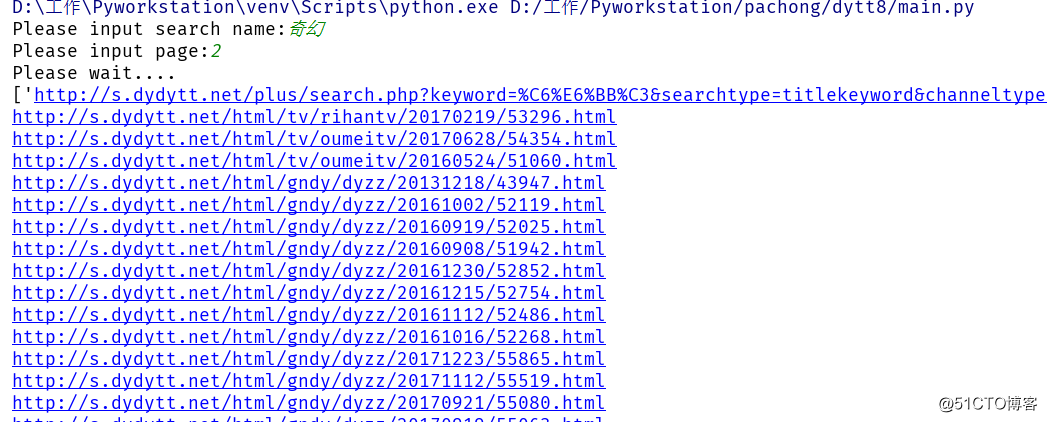

相关文章推荐
- Python---对html文件内容进行搜索取出特定URL地址字符串,保存成列表,并使用每个url下载图片,并保存到硬盘上,使用bs4,beautifulsoup模块
- Python---对html文件内容进行搜索取出特定URL地址字符串,保存成列表,并使用每个url下载图片,并保存到硬盘上,使用正则re
- 怎么实现NPOI导出excel保存到服务器上,然后返回文件地址下载?
- 【搜片APP】自制搜索电影下载资源的搜片器
- EL表达式查询出来的数据,下载成excel表格,很实用的
- Python 2.7_Second_try_爬取阳光电影网_获取电影下载地址并写入文件 20161207
- EXCEL教程下载地址
- 使用POI生成Excel并进行流下载(不需在服务器上保存)
- 下载对话框消失导致Excel无法正常保存的故障
- 网络地址下载文件,浏览器提示保存
- 用python来爬某电影网站的下载地址
- C#开发的高性能EXCEL导入、导出工具DataPie(支持MSSQL、ORACLE、ACCESS,附源码下载地址)
- 电脑公司特别版8.5操作系统出来了;下载地址
- asp.net 生成 excel导出保存时, 解决迅雷下载aspx页面问题
- AS3中 用JPEGEncoder保存 摄像头拍的照片 (另有JPEGEncoder类的下载地址)
- java 中 excel生成并文件下载保存到本地(三)
- mfc到处数据到excel类下载地址
- 如何找到网页图片地址并下载到本地保存?
- openSUSE-12.3出来了,下载地址(种子)
- java多线程-爬电影天堂上的电影下载地址