机器学习中样本的样本量的估计(VC维)
2018-02-06 10:31
274 查看
转自:http://blog.csdn.net/uestc_c2_403/article/details/72859021
在机器学习中,如果样本量不足,我们利用模型学习到的结果就有可能是错误的,因为样本不足的情况下,规则会有很多。也就是我们如果用f表示真是的规则,用g表示利用模型学习到的规则。那么我们希望g和f越接近越好,可是我们并不知道f到底是什么?如果样本不足,机器是没法学习的。
例如:
给你123,输出为246。有人会说那就是对应元素乘以2,这是一种规则。还有别的规则,第一个数字是原来数的第二位,后面两位分别是原来数字后两位乘以2.还有很多别的规则,规则不唯一,学习就会失效,我们可以利用hoeffding inequality不等式来估计一下学习到的g和f很接近的概率有多大。
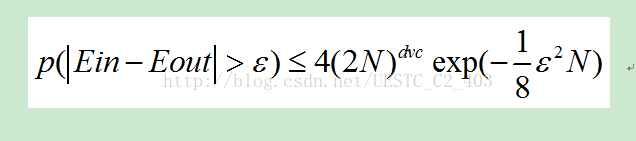
Ein就是采用g假设时候误差,Eout就是采用f时候的误差。从这个不等式可以知道,样本越大,得到g和f接近的概率就越大,样本越小,就越小。可以用这个公式大概计算一下样本的数量。dvc也是一个重要的参数,也不能太大,如果太大,样本就需要更多。
一般情况下,样本数量大约等于10dvc就可以了,但是上面的公式计算的结果就会大很多。
dvc就是表示VC dimension。感知机算法的dvc等于d+1,d就是数据的维度。
对于神经网络,其VC维的公式为:
dvc = O(VD),其中V表示神经网络中神经元的个数,D表示weight的个数,也就是神经元之间连接的数目。(注意:此式是一个较粗略的估计,深度神经网络目前没有明确的vc bound)
举例来说,一个普通的三层全连接神经网络:输入是1000维,隐藏层有1000个nodes,输出为1个node,则它的VC维大约为O(1000*1000*1000)。
可以看到,神经网络的VC维相对较高,因而它的表达能力非常强,可以用来处理任何复杂的分类问题。根据上一节的结论,要充分训练该神经网络,所需样 本量为10倍的VC维。如此大的训练数据量,是不可能达到的。所以在20世纪,复杂神经网络模型在out of sample的表现不是很好,容易overfit。
但现在为什么深度学习的表现越来越好。原因是多方面的,主要体现在:
通过修改神经网络模型的结构,以及提出新的regularization方法,使得神经网络模型的VC维相对减小了。例如卷积神经网络,通过修改 模型结构(局部感受野和权值共享),减少了参数个数,降低了VC维。2012年的AlexNet,8层网络,参数个数只有60M;而2014年的GoogLeNet,22层网络,参数个数只有7M。再例如dropout,drop
connect,denosing等regularization方法的提出,也一定程度上增加了神经网络的泛化能力。
训练数据变多了。随着互联网的越来越普及,相比于以前,训练数据的获取容易程度以及量和质都大大提升了。训练数据越多,Ein越容易接近于 Eout。而且目前训练神经网络,还会用到很多data augmentation方法,例如在图像上,剪裁,平移,旋转,调亮度,调饱和度,调对比度等都使用上了。
除此外,pre-training方法的提出,都促进了深度学习。
但即便这样,深度学习的VC维和VC Bound依旧很大,其泛化控制方法依然没有强理论支撑。但是实践又一次次证明,深度学习是好用的。所以VC维对深度学习的指导意义,目前不好表述,有一 种思想建议,深度学习应该抛弃对VC维之类概念的迷信,尝试从其他方面来解释其可学习型,例如使用泛函空间(如Banach Space)中的概率论。
参考:http://www.thebigdata.cn/JiShuBoKe/14027.html
在机器学习中,如果样本量不足,我们利用模型学习到的结果就有可能是错误的,因为样本不足的情况下,规则会有很多。也就是我们如果用f表示真是的规则,用g表示利用模型学习到的规则。那么我们希望g和f越接近越好,可是我们并不知道f到底是什么?如果样本不足,机器是没法学习的。
例如:
给你123,输出为246。有人会说那就是对应元素乘以2,这是一种规则。还有别的规则,第一个数字是原来数的第二位,后面两位分别是原来数字后两位乘以2.还有很多别的规则,规则不唯一,学习就会失效,我们可以利用hoeffding inequality不等式来估计一下学习到的g和f很接近的概率有多大。
Ein就是采用g假设时候误差,Eout就是采用f时候的误差。从这个不等式可以知道,样本越大,得到g和f接近的概率就越大,样本越小,就越小。可以用这个公式大概计算一下样本的数量。dvc也是一个重要的参数,也不能太大,如果太大,样本就需要更多。
一般情况下,样本数量大约等于10dvc就可以了,但是上面的公式计算的结果就会大很多。
dvc就是表示VC dimension。感知机算法的dvc等于d+1,d就是数据的维度。
深度学习与VC维
对于神经网络,其VC维的公式为:dvc = O(VD),其中V表示神经网络中神经元的个数,D表示weight的个数,也就是神经元之间连接的数目。(注意:此式是一个较粗略的估计,深度神经网络目前没有明确的vc bound)
举例来说,一个普通的三层全连接神经网络:输入是1000维,隐藏层有1000个nodes,输出为1个node,则它的VC维大约为O(1000*1000*1000)。
可以看到,神经网络的VC维相对较高,因而它的表达能力非常强,可以用来处理任何复杂的分类问题。根据上一节的结论,要充分训练该神经网络,所需样 本量为10倍的VC维。如此大的训练数据量,是不可能达到的。所以在20世纪,复杂神经网络模型在out of sample的表现不是很好,容易overfit。
但现在为什么深度学习的表现越来越好。原因是多方面的,主要体现在:
通过修改神经网络模型的结构,以及提出新的regularization方法,使得神经网络模型的VC维相对减小了。例如卷积神经网络,通过修改 模型结构(局部感受野和权值共享),减少了参数个数,降低了VC维。2012年的AlexNet,8层网络,参数个数只有60M;而2014年的GoogLeNet,22层网络,参数个数只有7M。再例如dropout,drop
connect,denosing等regularization方法的提出,也一定程度上增加了神经网络的泛化能力。
训练数据变多了。随着互联网的越来越普及,相比于以前,训练数据的获取容易程度以及量和质都大大提升了。训练数据越多,Ein越容易接近于 Eout。而且目前训练神经网络,还会用到很多data augmentation方法,例如在图像上,剪裁,平移,旋转,调亮度,调饱和度,调对比度等都使用上了。
除此外,pre-training方法的提出,都促进了深度学习。
但即便这样,深度学习的VC维和VC Bound依旧很大,其泛化控制方法依然没有强理论支撑。但是实践又一次次证明,深度学习是好用的。所以VC维对深度学习的指导意义,目前不好表述,有一 种思想建议,深度学习应该抛弃对VC维之类概念的迷信,尝试从其他方面来解释其可学习型,例如使用泛函空间(如Banach Space)中的概率论。
参考:http://www.thebigdata.cn/JiShuBoKe/14027.html

相关文章推荐
- 机器学习中样本的样本量的估计
- 【机器学习基础】VC维与模型复杂度、样本复杂度
- 【机器学习基础】VC维与模型复杂度、样本复杂度
- 机器学习笔记(四)——最大似然估计
- 随机样本选择——快速求解机器学习中的优化问题
- 机器学习:最大似然估计与最大后验概率估计
- 样本估计
- 机器学习 —— 基础整理(三)生成式模型的非参数方法: Parzen窗估计、k近邻估计;k近邻分类器
- 机器学习基础--最大似然估计
- 小样本学习遇上机器学习--------随笔记录
- 机器学习之从极大似然估计到最大熵原理以及EM算法详解
- 机器学习中的概率模型和概率密度估计方法及VAE生成式模型详解之一(内容简介)
- 机器学习(5)——回归算法:有偏估计回归方法(ridge regression & Lasso Regressio)
- 样本概率密度(pdf)估计的Matlab实现%用来画网络延时数据
- 机器学习-10:MachineLN之样本不均衡
- 机器学习 - 极大似然估计
- 机器学习笔记(二)矩估计,极大似然估计
- 机器学习(二)概率密度分布之参数估计
- 【机器学习数学基础之概率论与统计04】非参数估计
- 机器学习数学|大数定理中心极限定理矩估计