【python】机器学习实战KNN算法之约会网站
2018-02-03 14:20
555 查看
一、算法流程:

二、约会网站实例流程:


三、代码详解:
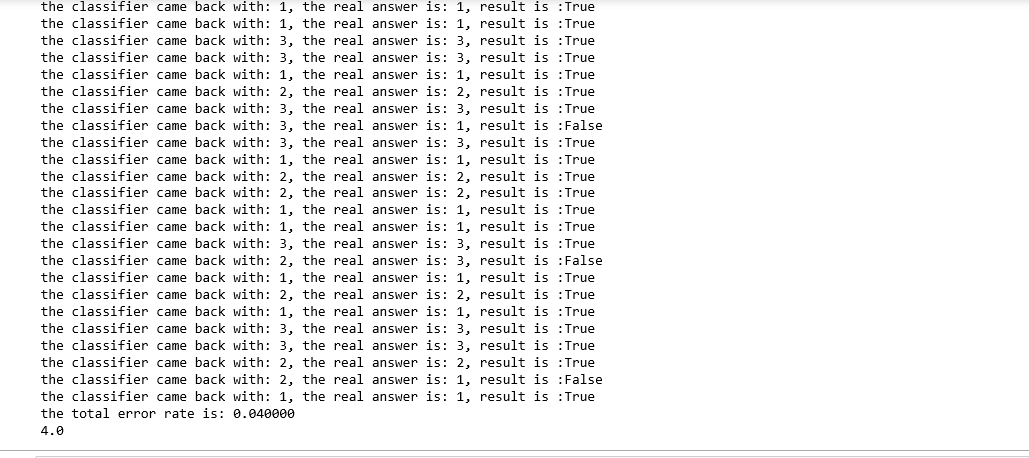
结果:选取K=4,正确率为96%100
二、约会网站实例流程:
三、代码详解:
import numpy as np
import operator
import matplotlib.pyplot as plt
def classify(inX, dataset, labels, k):
"""
inX 是输入的测试样本,是一个[x, y]样式的
dataset 是训练样本集
labels 是训练样本标签
k 是top k最相近的
"""
# shape返回矩阵的[行数,列数],
# 那么shape[0]获取数据集的行数,
# 行数就是样本的数量
dataSetSize = dataset.shape[0]
"""
下面的求距离过程就是按照欧氏距离的公式计算的。
即 根号(x^2+y^2)
"""
# tile属于numpy模块下边的函数
# tile(A, reps)返回一个shape=reps的矩阵,矩阵的每个元素是A
# 比如 A=[0,1,2] 那么,tile(A, 2)= [0, 1, 2, 0, 1, 2]
# tile(A,(2,2)) = [[0, 1, 2, 0, 1, 2],
# [0, 1, 2, 0, 1, 2]]
# tile(A,(2,1,2)) = [[[0, 1, 2, 0, 1, 2]],
# [[0, 1, 2, 0, 1, 2]]]
# 上边那个结果的分开理解就是:
# 最外层是2个元素,即最外边的[]中包含2个元素,类似于[C,D],而此处的C=D,因为是复制出来的
# 然后C包含1个元素,即C=[E],同理D=[E]
# 最后E包含2个元素,即E=[F,G],此处F=G,因为是复制出来的
# F就是A了,基础元素
# 综合起来就是(2,1,2)= [C, C] = [[E], [E]] = [[[F, F]], [[F, F]]] = [[[A, A]], [[A, A]]]
# 这个地方就是为了把输入的测试样本扩展为和dataset的shape一样,然后就可以直接做矩阵减法了。
# 比如,dataset有4个样本,就是4*2的矩阵,输入测试样本肯定是一个了,就是1*2,为了计算输入样本与训练样本的距离
# 那么,需要对这个数据进行作差。这是一次比较,因为训练样本有n个,那么就要进行n次比较;
# 为了方便计算,把输入样本复制n次,然后直接与训练样本作矩阵差运算,就可以一次性比较了n个样本。
# 比如inX = [0,1],dataset就用函数返回的结果,那么
# tile(inX, (4,1))= [[ 0.0, 1.0],
# [ 0.0, 1.0],
# [ 0.0, 1.0],
# [ 0.0, 1.0]]
# 作差之后
# diffMat = [[-1.0,-0.1],
# [-1.0, 0.0],
# [ 0.0, 1.0],
# [ 0.0, 0.9]]
diffMat =np. tile(inX, (dataSetSize, 1)) - dataset
# diffMat就是输入样本与每个训练样本的差值,然后对其每个x和y的差值进行平方运算。
# diffMat是一个矩阵,矩阵**2表示对矩阵中的每个元素进行**2操作,即平方。
# sqDiffMat = [[1.0, 0.01],
# [1.0, 0.0 ],
# [0.0, 1.0 ],
# [0.0, 0.81]]
sqDiffMat = diffMat ** 2
# axis=1表示按照横轴,sum表示累加,即按照行进行累加。
# sqDistance = [[1.01],
# [1.0 ],
# [1.0 ],
# [0.81]]
sqDistance = sqDiffMat.sum(axis=1)
# 对平方和进行开根号
distance = sqDistance ** 0.5
# 按照升序进行快速排序,返回的是原数组的下标。
# 比如,x = [30, 10, 20, 40]
# 升序排序后应该是[10,20,30,40],他们的原下标是[1,2,0,3]
# 那么,numpy.argsort(x) = [1, 2, 0, 3]
sortedDistIndicies = distance.argsort()
# 存放最终的分类结果及相应的结果投票数
classCount = {}
# 投票过程,就是统计前k个最近的样本所属类别包含的样本个数
for i in range(k):
# index = sortedDistIndicies[i]是第i个最相近的样本下标
# voteIlabel = labels[index]是样本index对应的分类结果('A' or 'B')
voteIlabel = labels[sortedDistIndicies[i]]
# classCount.get(voteIlabel, 0)返回voteIlabel的值,如果不存在,则返回0
# 然后将票数增1
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# 把分类结果进行排序,然后返回得票数最多的分类结果
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def file2matrix(filename):
"""
从文件中读入训练数据,并存储为矩阵
"""
fr = open(filename)
arrayOlines = fr.readlines()
numberOfLines = len(arrayOlines) #获取 n=样本的行数
returnMat = np.zeros((numberOfLines,3)) #创建一个2维矩阵用于存放训练样本数据,一共有n行,每一行存放3个数据
classLabelVector = [] #创建一个1维数组用于存放训练样本标签。
#print(returnMat)
index = 0
for line in arrayOlines:
# 把回车符号给去掉
line = line.strip()
# 把每一行数据用\t分割
listFromLine = line.split('\t')
# 把分割好的数据放至数据集,其中index是该样本数据的下标,就是放到第几行
returnMat[index,:] = listFromLine[0:3]
# 把该样本对应的标签放至标签集,顺序与样本集对应。
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
def autoNorm(dataSet):
"""
训练数据归一化
"""
# 获取数据集中每一列的最小数值
# 以createDataSet()中的数据为例,group.min(0)=[0,0]
minVals = dataSet.min(0)
# 获取数据集中每一列的最大数值
# group.max(0)=[1, 1.1]
maxVals = dataSet.max(0)
# 最大值与最小的差值
ranges = maxVals - minVals
# 创建一个与dataSet同shape的全0矩阵,用于存放归一化后的数据
normDataSet = np.zeros(np.shape(dataSet))
m = dataSet.shape[0]
# 把最小值扩充为与dataSet同shape,然后作差,具体tile请翻看 第三节 代码中的tile
normDataSet = dataSet - np.tile(minVals, (m,1))
# 把最大最小差值扩充为dataSet同shape,然后作商,是指对应元素进行除法运算,而不是矩阵除法。
# 矩阵除法在numpy中要用linalg.solve(A,B)
normDataSet = normDataSet/np.tile(ranges, (m,1))
return normDataSet, ranges, minVals
def datingClassTest():
# 将数据集中10%的数据留作测试用,其余的90%用于训练
hoRatio = 0.10
datingDataMat,datingLabels = file2matrix('C:\\Users\\蓝月亮\\Desktop\\机器学习实战源代码\\machinelearninginaction\\Ch02\\datingTestSet2.txt') #load data setfrom file
#print(datingDataMat)
#print(datingLabels)
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
print(m)
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],4)
#print(classifierResult)
print("the classifier came back with: %d, the real answer is: %d, result is :%s" % (classifierResult, datingLabels[i],classifierResult==datingLabels[i]))
if(classifierResult != datingLabels[i]):
errorCount+= 1.0
print("the total error rate is: %f" % (errorCount/float(numTestVecs)))
print(errorCount)结果:选取K=4,正确率为96%100

相关文章推荐
- 基于KNN算法的约会网站配对效果 python3.2
- 《机器学习实战》学习笔记——K-近邻算法(KNN)(二)海伦约会网站匹配实战
- 学习笔记——《机器学习实战》KNN算法实现 约会网站测试,手写数字识别,代码,注释,错误修改
- 基于KNN算法的约会网站配对效果 python3.2
- 使用KNN算法改进约会网站的配对效果
- 《机器学习实战》第二章 2.2用k-近邻算法改进约会网站的配对效果
- 机器学习 & python 使用k-近邻算法改进约会网站的配对效果
- k-近邻算法(KNN)--2改进约会网站的配对效果---by香蕉麦乐迪
- 机器学习实战(第二篇)-k-近邻算法改进约会网站配对结果
- 读懂《机器学习实战》代码—K-近邻算法改进约会网站配对效果
- kNN近邻算法改善约会网站配对效果案例
- k-近邻算法1(kNN)使用kNN算法改进约会网站的配对效果
- <机器学习实战 >KNN算法 改进约会网站的配对效果
- 使用KNN算法改进约会网站的配对效果
- 『机器学习实战』使用 k-近邻算法改进约会网站的配对效果
- KNN算法Python实现(代码来自机器学习实战)及注释
- 【机器学习实战-kNN:约会网站约友分类】python3实现-书本知识【2】
- 《机器学习实战》之k-近邻算法(改进约会网站的配对效果)
- 【python】机器学习实战KNN算法之手写数字识别
- kNN算法改进约会网站的配对效果