dubbo序列化过程源码分析:
2018-02-02 00:00
399 查看
先看下dubbo在serialize层的类设计方案
序列化方案的入口,是接口Serialization的实现类。
目前dubbo的spi实现有:

具体看下DubboSerialization类和Hessian2Serialization类:
可以看到具体序列化实例是内聚到接口实现里的。
以DubboSerialization为例,看下具体实例的类层次结构。
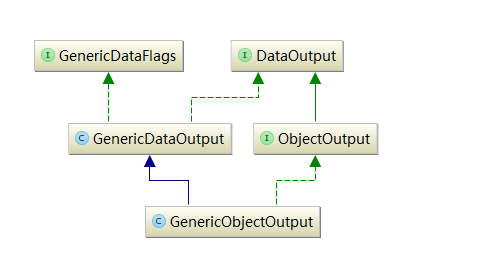
GenericObjectOutput类继承关系如下图:
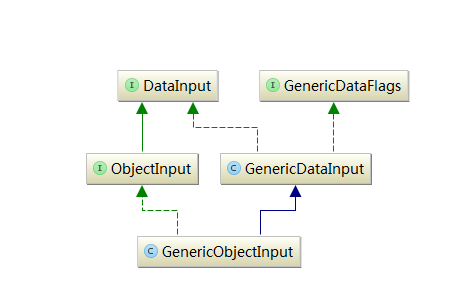
GenericObjectInput类继承关系如下图:
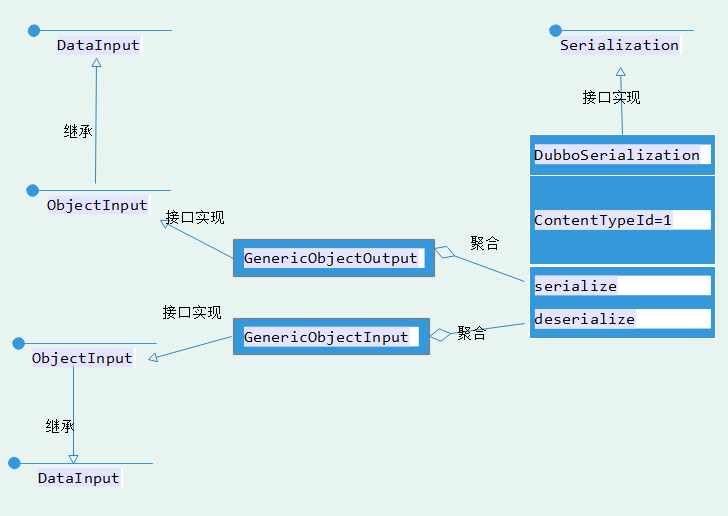
所以可以用个二维继承图来表示DubboSerialization的类层次图:
其他Serialization扩展实现也有类似的继承关系类图,这样就很好的把接口和实现做了分离,方便spi扩展。
值得一提的是,hession2序列化是dubbo内置了开源的hession序列化实现。hession序列化由于是二进制的所以序列化结果较小。不过Dubbo框架自己也写了一个序列化工具方案,从他们提供的测试类来看,dubbo自己实现的方案序列化结果更小。这里很乐意研究下,dubbo自己实现的序列化方案.
Builder<T> 本身是个泛型抽象类,提供了三个待实现抽象方法:
根据设计原理,每种要序列化的类型,都要有对应的Builder实现类。Builder类本身
内置了8种基本类型,以及String,HashMap,ArrayList,Date等12中常用数据类型和集合类的Builder实现。
而对于自定义的pojo对象序列化,则是利用javasssit技术动态生成Builder实现类,
在设计上应该是基于一个假设,即复杂的pojo对象也都是由上述常用的类型字段构造的。
pojo的序列化操作,实际就是对对象字段的序列化操作,这样就可以用上述内置的类型Builder分别对各类型字段序列化。上面说到,dubbo自身实现的序列化结果较小,也是因为它为每种类型,特别常用的内置类型都定制化了序列化方案,比如做空间压缩。
比如Integer类型Builder实现:
还有ArrayList类型的Builder实现:
可以看到每种类型的序列化,反序列化都是对应的。这样就不会数据混乱了。
再看下自己定义的pojo类型,dubbo处理方式是,利用javassit动态生成对应的Builder实现,以Phone为例:
javassit动态生成的Builder实现代码反编译后,这样的:
这个类实现了Builder内部一个抽象类:
实现了它3个抽象方法。这样上层方法调用writeTo()方法和parseFrom()方法就可以做序列化操作了。其他像数组类型和枚举类型的动态Builder<T>也都差不多这个思路。
以上做的主要目的就是把复杂类型的序列化,转为对基本类型的序列化和反序列化。
由GenericObjectInput类和GenericObjectOutput的继承关系图可知,
基本类型的序列化在GenericDataOutput类里,反序列化在GenericDataInput类里,具体代码,抽取一个分析下。
这里看下int值的序列化,writeVarint32(int v)方法:
可以对照下int的反序列化:
序列化方案的入口,是接口Serialization的实现类。
/**
* Serialization. (SPI, Singleton, ThreadSafe)
* 默认扩展方案是 hessian2 也是dubbo协议默认序列化实现
* @author ding.lid
* @author william.liangf
*/
@SPI("hessian2")
public interface Serialization {
/**
* get content type id
* 序列化标识 具体每个spi扩展方案指定一个固定值
* @return content type id
*/
byte getContentTypeId();
/**
* get content type
*
* @return content type
*/
String getContentType();
/**
* create serializer
* 获取一个具体序列化实现实例
* @param url
* @param output
* @return serializer
* @throws IOException
*/
@Adaptive
ObjectOutput serialize(URL url, OutputStream output) throws IOException;
/**
* create deserializer
* 获取一个具体反序列化实现实例
* @param url
* @param input
* @return deserializer
* @throws IOException
*/
@Adaptive
ObjectInput deserialize(URL url, InputStream input) throws IOException;
}目前dubbo的spi实现有:
具体看下DubboSerialization类和Hessian2Serialization类:
public class DubboSerialization implements Serialization {
/****\
* 固定值 1
* @return
*/
public byte getContentTypeId() {
return 1;
}
/***
* 固定值 x-application/dubbo
* @return
*/
public String getContentType() {
return "x-application/dubbo";
}
/***
* 具体序列化实现实例是GenericObjectOutput
* @param url
* @param out
* @return
* @throws IOException
*/
public ObjectOutput serialize(URL url, OutputStream out) throws IOException {
return new GenericObjectOutput(out);
}
/***
* 具体反序列化实现实例是GenericObjectInput
* @param url
* @param is
* @return
* @throws IOException
*/
public ObjectInput deserialize(URL url, InputStream is) throws IOException {
return new GenericObjectInput(is);
}
}
public class Hessian2Serialization implements Serialization {
public static final byte ID = 2;
public byte getContentTypeId() {
return ID;
}
public String getContentType() {
return "x-application/hessian2";
}
public ObjectOutput serialize(URL url, OutputStream out) throws IOException {
return new Hessian2ObjectOutput(out);
}
public ObjectInput deserialize(URL url, InputStream is) throws IOException {
return new Hessian2ObjectInput(is);
}
}可以看到具体序列化实例是内聚到接口实现里的。
以DubboSerialization为例,看下具体实例的类层次结构。
GenericObjectOutput类继承关系如下图:
GenericObjectInput类继承关系如下图:
所以可以用个二维继承图来表示DubboSerialization的类层次图:
其他Serialization扩展实现也有类似的继承关系类图,这样就很好的把接口和实现做了分离,方便spi扩展。
值得一提的是,hession2序列化是dubbo内置了开源的hession序列化实现。hession序列化由于是二进制的所以序列化结果较小。不过Dubbo框架自己也写了一个序列化工具方案,从他们提供的测试类来看,dubbo自己实现的方案序列化结果更小。这里很乐意研究下,dubbo自己实现的序列化方案.
dubbo自己实现的序列化方案
它设计结构,就是围绕序列化对象构建Builder,由Builder来驱动对象序列化和反序列化Builder<T> 本身是个泛型抽象类,提供了三个待实现抽象方法:
/*** * 对象序列化方法 待实现 * @param obj * @param out * @throws IOException */ abstract public void writeTo(T obj, GenericObjectOutput out) throws IOException; /*** * 对象反序列化方法 待实现 * @param in * @return * @throws IOException */ abstract public T parseFrom(GenericObjectInput in) throws IOException; /*** * 返回 序列化 类型 class * @return */ abstract public Class<T> getType();
根据设计原理,每种要序列化的类型,都要有对应的Builder实现类。Builder类本身
内置了8种基本类型,以及String,HashMap,ArrayList,Date等12中常用数据类型和集合类的Builder实现。
而对于自定义的pojo对象序列化,则是利用javasssit技术动态生成Builder实现类,
在设计上应该是基于一个假设,即复杂的pojo对象也都是由上述常用的类型字段构造的。
pojo的序列化操作,实际就是对对象字段的序列化操作,这样就可以用上述内置的类型Builder分别对各类型字段序列化。上面说到,dubbo自身实现的序列化结果较小,也是因为它为每种类型,特别常用的内置类型都定制化了序列化方案,比如做空间压缩。
比如Integer类型Builder实现:
new Builder<Integer>() {
@Override
public Class<Integer> getType() {
return Integer.class;
}
//序列化方法
@Override
public void writeTo(Integer obj, GenericObjectOutput out) throws IOException {
if (obj == null) {//等于null,就存代表null的标识
out.write0(OBJECT_NULL);
} else {//否则,按规则,现存一字节,代表有值的标识,接下来存具体值
out.write0(OBJECT_VALUE);
out.writeInt(obj.intValue());
}
}
//反序列化方法
@Override
public Integer parseFrom(GenericObjectInput in) throws IOException {
byte b = in.read0();
if (b == OBJECT_NULL)//是空标识,返回null
return null;
if (b != OBJECT_VALUE)
throw new IOException("Input format error, expect OBJECT_NULL|OBJECT_VALUE, get " + b + ".");
//否则,返回反序列化后值
return Integer.valueOf(in.readInt());
}
}还有ArrayList类型的Builder实现:
new Builder<ArrayList>() {
@Override
public Class<ArrayList> getType() {
return ArrayList.class;
}
@Override
public void writeTo(ArrayList obj, GenericObjectOutput out) throws IOException {
if (obj == null) {//null值
out.write0(OBJECT_NULL);
} else {//
out.write0(OBJECT_VALUES);//存一个多值的标识
out.writeUInt(obj.size());//存值个数
for (Object item : obj)
out.writeObject(item);//具体循环序列化每个字
}
}
@Override
public ArrayList parseFrom(GenericObjectInput in) throws IOException {
byte b = in.read0();
if (b == OBJECT_NULL)//null值
return null;
if (b != OBJECT_VALUES)
throw new IOException("Input format error, expect OBJECT_NULL|OBJECT_VALUES, get " + b + ".");
int len = in.readUInt();//先读取值个数
ArrayList ret = new ArrayList(len);//根据大小构造容器
for (int i = 0; i < len; i++)//遍历读取值个数,放序列化
ret.add(in.readObject());
return ret;
}
}可以看到每种类型的序列化,反序列化都是对应的。这样就不会数据混乱了。
再看下自己定义的pojo类型,dubbo处理方式是,利用javassit动态生成对应的Builder实现,以Phone为例:
public class Phone implements Serializable {
private static final long serialVersionUID = 4399060521859707703L;
private String country;
private String area;
private String number;
private String extensionNumber;
//getter,setter 省略
}javassit动态生成的Builder实现代码反编译后,这样的:
public class Phone$bc0 extends Builder.AbstractObjectBuilder
implements ClassGenerator.DC
{
public static Field[] fields;
public static Builder[] builders;
public Class getType()
{
return Phone.class;
}
//具体序列化方法
protected void writeObject(Object paramObject, GenericObjectOutput paramGenericObjectOutput)
throws IOException
{
Phone localPhone = (Phone)paramObject;
paramGenericObjectOutput.writeInt(fields.length);
//由于Phone的4个字段都是String类型,所以这里builders的元素其实都是Builder<String>实例,具体是String的序列化方法
//同理,反序列化类似。
builders[0].writeTo(localPhone.getArea(), paramGenericObjectOutput);
builders[1].writeTo(localPhone.getCountry(), paramGenericObjectOutput);
builders[2].writeTo(localPhone.getExtensionNumber(), paramGenericObjectOutput);
builders[3].writeTo(localPhone.getNumber(), paramGenericObjectOutput);
}
//反序列化方法
protected void readObject(Object paramObject, GenericObjectInput paramGenericObjectInput)
throws IOException
{
int i = paramGenericObjectInput.readInt();
if (i != 4)
throw new IllegalStateException("Deserialize Class [com.alibaba.dubbo.common.model.person.Phone], field count not matched. Expect 4 but get " + i + ".");
Phone localPhone = (Phone)paramObject;
if (i == 0)
return;
localPhone.setArea((String)builders[0].parseFrom(paramGenericObjectInput));
if (i == 1)
return;
localPhone.setCountry((String)builders[1].parseFrom(paramGenericObjectInput));
if (i == 2)
return;
localPhone.setExtensionNumber((String)builders[2].parseFrom(paramGenericObjectInput));
if (i == 3)
return;
localPhone.setNumber((String)builders[3].parseFrom(paramGenericObjectInput));
for (int j = 4; j < i; j++)
paramGenericObjectInput.skipAny();
}
protected Object newInstance(GenericObjectInput paramGenericObjectInput)
{
return new Phone();
}
}这个类实现了Builder内部一个抽象类:
public static abstract class AbstractObjectBuilder<T> extends Builder<T> {
abstract public Class<T> getType();
public void writeTo(T obj, GenericObjectOutput out) throws IOException {
if (obj == null) {
out.write0(OBJECT_NULL);
} else {
int ref = out.getRef(obj);
if (ref < 0) {
out.addRef(obj);
out.write0(OBJECT);
writeObject(obj, out);
} else {
out.write0(OBJECT_REF);
out.writeUInt(ref);
}
}
}
public T parseFrom(GenericObjectInput in) throws IOException {
byte b = in.read0();
switch (b) {
case OBJECT: {
T ret = newInstance(in);
in.addRef(ret);
readObject(ret, in);
return ret;
}
case OBJECT_REF:
return (T) in.getRef(in.readUInt());
case OBJECT_NULL:
return null;
default:
throw new IOException("Input format error, expect OBJECT|OBJECT_REF|OBJECT_NULL, get " + b);
}
}
abstract protected void writeObject(T obj, GenericObjectOutput out) throws IOException;
abstract protected T newInstance(GenericObjectInput in) throws IOException;
abstract protected void readObject(T ret, GenericObjectInput in) throws IOException;
}实现了它3个抽象方法。这样上层方法调用writeTo()方法和parseFrom()方法就可以做序列化操作了。其他像数组类型和枚举类型的动态Builder<T>也都差不多这个思路。
以上做的主要目的就是把复杂类型的序列化,转为对基本类型的序列化和反序列化。
由GenericObjectInput类和GenericObjectOutput的继承关系图可知,
基本类型的序列化在GenericDataOutput类里,反序列化在GenericDataInput类里,具体代码,抽取一个分析下。
这里看下int值的序列化,writeVarint32(int v)方法:
/***
* 对int数据的序列化 -15到31值,留作特殊标识,序列化时
* 固定依次存10到56(为什么选这47位数,不太理解????谁来醍醐灌顶)
* @param v
* @throws IOException
*/
private void writeVarint32(int v) throws IOException {
switch (v) {
case -15:
write0(VARINT_NF);
break;
case -14:
write0(VARINT_NE);
break;
case -13:
write0(VARINT_ND);
break;
case -12:
write0(VARINT_NC);
break;
case -11:
write0(VARINT_NB);
break;
case -10:
write0(VARINT_NA);
break;
case -9:
write0(VARINT_N9);
break;
case -8:
write0(VARINT_N8);
break;
case -7:
write0(VARINT_N7);
break;
case -6:
write0(VARINT_N6);
break;
case -5:
write0(VARINT_N5);
break;
case -4:
write0(VARINT_N4);
break;
case -3:
write0(VARINT_N3);
break;
case -2:
write0(VARINT_N2);
break;
case -1:
write0(VARINT_N1);
break;
case 0:
write0(VARINT_0);
break;
case 1:
write0(VARINT_1);
break;
case 2:
write0(VARINT_2);
break;
case 3:
write0(VARINT_3);
break;
case 4:
write0(VARINT_4);
break;
case 5:
write0(VARINT_5);
break;
case 6:
write0(VARINT_6);
break;
case 7:
write0(VARINT_7);
break;
case 8:
write0(VARINT_8);
break;
case 9:
write0(VARINT_9);
break;
case 10:
write0(VARINT_A);
break;
case 11:
write0(VARINT_B);
break;
case 12:
write0(VARINT_C);
break;
case 13:
write0(VARINT_D);
break;
case 14:
write0(VARINT_E);
break;
case 15:
write0(VARINT_F);
break;
case 16:
write0(VARINT_10);
break;
case 17:
write0(VARINT_11);
break;
case 18:
write0(VARINT_12);
break;
case 19:
write0(VARINT_13);
break;
case 20:
write0(VARINT_14);
break;
case 21:
write0(VARINT_15);
break;
case 22:
write0(VARINT_16);
break;
case 23:
write0(VARINT_17);
break;
case 24:
write0(VARINT_18);
break;
case 25:
write0(VARINT_19);
break;
case 26:
write0(VARINT_1A);
break;
case 27:
write0(VARINT_1B);
break;
case 28:
write0(VARINT_1C);
break;
case 29:
write0(VARINT_1D);
break;
case 30:
write0(VARINT_1E);
break;
case 31:
write0(VARINT_1F);
break;
default:
//其他值的存放规则是,
//第一字节,后续有几个有效字节,
//后面是具体的有效字节
int t = v, ix = 0;
byte[] b = mTemp;
//把字节由低到高放入字节数组b[1],b[2]
while (true) {
b[++ix] = (byte) (v & 0xff);
if ((v >>>= 8) == 0)
break;
}
if (t > 0) {//是正数
// [ 0a e2 => 0a e2 00 ] [ 92 => 92 00 ]
if (b[ix] < 0)//最高字节,最高位为1 这样比较,就是负数
b[++ix] = 0;//补0,防止误解析为负数
} else {//是负数,存的是补码(是它相反数的各位取反,末尾加1) 这里做压缩bit位,//有点绕
// [ 01 ff ff ff => 01 ff ] [ e0 ff ff ff => e0 ] [ 01 e0 ff ff ff => 01 e0 ] 1110
while (b[ix] == (byte) 0xff && b[ix - 1] < 0)
ix--;
}
b[0] = (byte) (VARINT + ix - 1);//存一个标识为,代表有效字节数(0 代表1个字节,1:代表2个字节,2,代表3个字节)
write0(b, 0, ix + 1);//所以这里写ix+1个字节
}
}可以对照下int的反序列化:
private int readVarint32() throws IOException {
byte b = read0();//第一个字节是标识字节
switch (b) {
case VARINT8://0代表接下来,1个有效字节
return read0();
case VARINT16: {//1代表接下来,2个有效字节
byte b1 = read0(), b2 = read0();
return (short) ((b1 & 0xff) | ((b2 & 0xff) << 8));
}
case VARINT24: {
byte b1 = read0(), b2 = read0(), b3 = read0();
int ret = (b1 & 0xff) | ((b2 & 0xff) << 8) | ((b3 & 0xff) << 16);
if (b3 < 0)
return ret | 0xff000000;
return ret;
}
case VARINT32: {
byte b1 = read0()
7ff0
, b2 = read0(), b3 = read0(), b4 = read0();
return ((b1 & 0xff) |
((b2 & 0xff) << 8) |
((b3 & 0xff) << 16) |
((b4 & 0xff) << 24));
}
//其他特殊值硬编码
case VARINT_NF:
return -15;
case VARINT_NE:
return -14;
case VARINT_ND:
return -13;
case VARINT_NC:
return -12;
case VARINT_NB:
return -11;
case VARINT_NA:
return -10;
case VARINT_N9:
return -9;
case VARINT_N8:
return -8;
case VARINT_N7:
return -7;
case VARINT_N6:
return -6;
case VARINT_N5:
return -5;
case VARINT_N4:
return -4;
case VARINT_N3:
return -3;
case VARINT_N2:
return -2;
case VARINT_N1:
return -1;
case VARINT_0:
return 0;
case VARINT_1:
return 1;
case VARINT_2:
return 2;
case VARINT_3:
return 3;
case VARINT_4:
return 4;
case VARINT_5:
return 5;
case VARINT_6:
return 6;
case VARINT_7:
return 7;
case VARINT_8:
return 8;
case VARINT_9:
return 9;
case VARINT_A:
return 10;
case VARINT_B:
return 11;
case VARINT_C:
return 12;
case VARINT_D:
return 13;
case VARINT_E:
return 14;
case VARINT_F:
return 15;
case VARINT_10:
return 16;
case VARINT_11:
return 17;
case VARINT_12:
return 18;
case VARINT_13:
return 19;
case VARINT_14:
return 20;
case VARINT_15:
return 21;
case VARINT_16:
return 22;
case VARINT_17:
return 23;
case VARINT_18:
return 24;
case VARINT_19:
return 25;
case VARINT_1A:
return 26;
case VARINT_1B:
return 27;
case VARINT_1C:
return 28;
case VARINT_1D:
return 29;
case VARINT_1E:
return 30;
case VARINT_1F:
return 31;
default:
throw new IOException("Tag error, expect VARINT, but get " + b);
}
}//看64位long型的序列化,体现出节约空间的操作
private void writeVarint64(long v) throws IOException {
int i = (int) v;
//如果int能放下long ,就用int存,尽量减少不必要的空间浪费
if (v == i) {
writeVarint32(i);
} else {
long t = v;
int ix = 0;
byte[] b = mTemp;
while (true) {
b[++ix] = (byte) (v & 0xff);
if ((v >>>= 8) == 0)
break;
}
if (t > 0) {
// [ 0a e2 => 0a e2 00 ] [ 92 => 92 00 ]
if (b[ix] < 0)
b[++ix] = 0;
} else {
// [ 01 ff ff ff => 01 ff ] [ e0 ff ff ff => e0 ]
while (b[ix] == (byte) 0xff && b[ix - 1] < 0)
ix--;
}
b[0] = (byte) (VARINT + ix - 1);
write0(b, 0, ix + 1);
}
}
//有意思的是,对String的序列化,其实是做utf8编码
/*** 处理字符串是,取每个字符
* 循环处理,每次最多处理256个字符,
* 具体,把字符通过String的getChars方法放入字符数组,再把字符转为字节,同时做utf8编码
* 具体可以看看,utf8编码规则,要不然不好懂。
* 对字符串的序列化由于用了utf8编码,相对unicode其实是放大了存储空间
*/
public void writeUTF(String v) throws IOException {
if (v == null) {
write0(OBJECT_NULL);
} else {
int len = v.length();
if (len == 0) {
write0(OBJECT_DUMMY);
} else {
write0(OBJECT_BYTES);
writeUInt(len);
int off = 0, limit = mLimit - 3, size;
char[] buf = mCharBuf;//256
do {
//最大256
size = Math.min(len - off, CHAR_BUF_SIZE);
//把char字符放入buf
v.getChars(off, off + size, buf, 0);
for (int i = 0; i < size; i++) {
char c = buf[i];
if (mPosition > limit) {//还剩2字节缓冲区
if (c < 0x80) {//如果一字节能表示,就用一字节 1000,0000
write0((byte) c);
} else if (c < 0x800) { //0000 1000,0000,0000
write0((byte) (0xC0 | ((c >> 6) & 0x1F)));//取高5位,前面补110
write0((byte) (0x80 | (c & 0x3F)));//取低六位前面补10
} else {
write0((byte) (0xE0 | ((c >> 12) & 0x0F)));//取高4位,前面补1110
write0((byte) (0x80 | ((c >> 6) & 0x3F)));//取中6位,前面补10
write0((byte) (0x80 | (c & 0x3F)));//取末尾6位,前面补10
}
} else {//还剩3个以上字节缓冲区,直接放缓冲区
if (c < 0x80) {
mBuffer[mPosition++] = (byte) c;
} else if (c < 0x800) {
mBuffer[mPosition++] = (byte) (0xC0 | ((c >> 6) & 0x1F));
mBuffer[mPosition++] = (byte) (0x80 | (c & 0x3F));
} else {
mBuffer[mPosition++] = (byte) (0xE0 | ((c >> 12) & 0x0F));
mBuffer[mPosition++] = (byte) (0x80 | ((c >> 6) & 0x3F));
mBuffer[mPosition++] = (byte) (0x80 | (c & 0x3F));
}
}
}
off += size;//取下一字节段
}
while (off < len);
}
}
}

相关文章推荐
- dubbo源码分析-client执行过程
- RPC框架(八)dubbo源码分析--dubbo调用过程分析
- Android 数据Parcel序列化过程源码分析
- dubbo服务暴露过程源码分析
- Linux内核源码分析--内核启动命令行的传递过程(Linux-3.0 ARMv7)
- android 4.04的应用程序启动过程及与Zygote的交互(基于静态源码分析)
- dubbo作为消费者注册过程分析
- 源码分析Activity启动过程
- zookeeper源码分析之一启动过程
- springmvc源码分析----入门看springmvc的加载过程
- 【知识库】--Dubbo ReferenceBean获取 -- router路由服务 源码过程(255)
- Android 4.0 Launcher2源码分析——启动过程分析
- spark内核揭秘-13-Worker中Executor启动过程源码分析
- quartz2.x源码分析——启动过程
- docker1.9源码分析(三):daemon启动过程
- Nginx源码分析 - HTTP模块篇 - ngx_http_wait_request_handler函数和HTTP Request解析过程
- nginx源码分析(10)-启动过程分析
- Redis第一个版本源码分析-启动过程分析1
- ARM Linux启动过程源码分析
- Dubbo 源码学习(四)初始化过程细节:解析服务