AlexNet论文--ImageNet Classification with Deep Convolutional Neural Networks+个人理解
2018-02-01 15:29
721 查看

摘要
我们的大型CNN网络模型能把ImageNet LSVRC-2010测试集上120万的高分辨率图片分到1000个不同的类别中。在top-1和top-5错误率上达到了37.5%和17.0%,比原来的 state-of-the-art好多了。本神经网络有6000万个参数和650000个神经元,由五个卷积层组成,他们中的一部分后面跟着池化层,最后是全连接层,输出是一个1000类的softmax。
为了加快训练速度,我们用非饱和线性激活函数,卷积操作的高效率GPU实现。
为了减少过拟合,对全连接层,使用最近发展的正则化方法:dropout。
top-1:分类结果不是概率最大的那个,即猜一次没有猜中
top-5:分类结果不是概率最大的五个,即猜五次没有猜中
state-of-the-art:当前的最佳算法
Introduction
提高物体识别的准确率,可以收集更大的数据集,学习更有效地模型,进一步减小过拟合的风险。学习一个大规模的图片集,我们肯定要建一个大学习容量的模型。而识别任务的高复杂度意味着即使大如ImageNet数据集也不能完全囊括这个问题的答案,因此我们必须要加上自己的先验知识来补偿没有设计到的数据。CNNs就是这样一个模型,其容量是由其宽度和深度决定的,对自然图片(统计的平稳,像素相关性的局部性),它具有很高的正确性。因此,和拥有相同层数的标准前馈神经网络相比,CNNs有更少的连接数和参数,因此它也更容易训练,虽然它理论上的最佳性能可能会差一点点。
不看CNNs的高质量和本地架构的高效,其实训练一个针对高分辨率图片的CNN还是消耗很大的。但现在的GPU搭配上2D卷积的高度优化的实现,足够有效的训练一个大型CNN了,加上最近的大规模有标签的数据集,也能保证训练的模型不会过拟合。
本论文贡献如下:
(1)用ImageNet的子集ILSVRC-2010 和 ILSVRC-2012数据集训练了一个大型CNN,实现了迄今为止最好的结果。
(2)实现了GPU的高效卷积操作。
(3)我们的网络包括很多不寻常的特征,大大提高了性能并减少了训练时间,具体见Section3.
(4)即使有1200000张图片,面对我们网络的大规模,也是很有可能过拟合的。在Section4描述了一些减小过拟合风险的技术。
(5)网络有五个卷积层和三个全连接层,这个深度非常重要,我们测试过,移除任意一个卷积层都会导致性能的下降,虽然他们每层只有不到百分之一的模型参数。
Dataset
ImageNet有22000类的150万张图片。ILSVRC是前者的子集,共有120万张训练图,5万张验证图,15万张测试图。ImageNet数据集由不同分辨率的图片组成,而我们的系统需要固定大小的输入。因此我们下采样图片到固定分辨率256×256.如果图像是一个举行,我们把图像缩放,把短边缩成256,然后裁剪出中央部分地256×256大小的图片。除了每个像素都要减去训练集的平均像素,我们不对图片进行任何预处理。所以说,我们是在图像的原始RGB值得基础上训练我们的网络。
Architecture
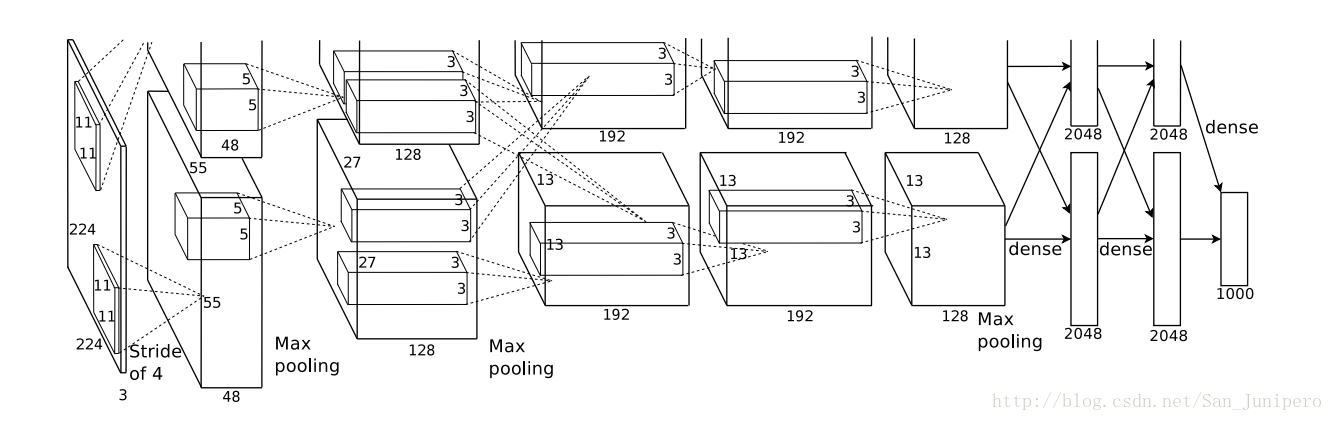
以下3.1-3.4按重要性先后描述,最重要的在前面
ReLU非线性激活函数
现在的标准激活函数是tanh和sigmoid。从梯度下降的时间来看,这些饱和非线性函数是远远慢于非饱和非线性函数的。用ReLU(修正线性单元)的深度卷积神经网络要比用tanh单元的网络快上好几倍。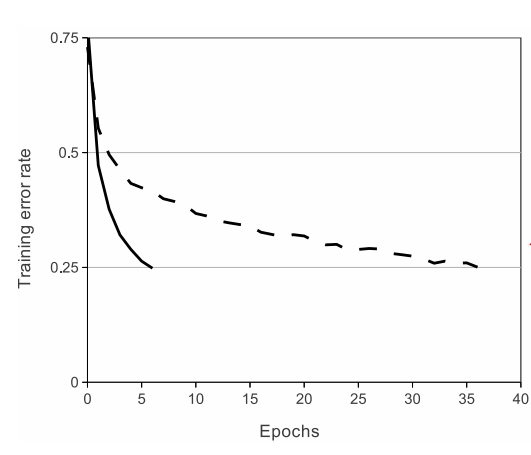
这张图表明,如果我们用饱和非线性函数,我们不能训练太大的神经网络。
多GPU上训练
单块GTX580只有3G内存,限制了所能训练的最大网络的规模。而对于我们120万张训练集对一块GPU来说实在太多了。所以我们现在把它扩展到了两块GPU上。当前的GPU已经能够达到直接从一块GPU写到另一块,或者直接从另一块里面读取,而不需要经过主机内存。在并行调度上,每块GPU放一半的核。另一个,GPU只在某些层里进行交互,第三层能从第二层任意一个GPU上读数据,第四层只能从第三层相应GPU上读数据。选择不同的连接模式对交叉验证是一个不小的挑战,但这也恰恰允许我们通过微调通信量,来使计算量达到一个可以接受的状态。局部响应归一化
局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),响应比较大的值变得更大,抑制其他反馈比较小的神经元,增强了模型的泛化能力。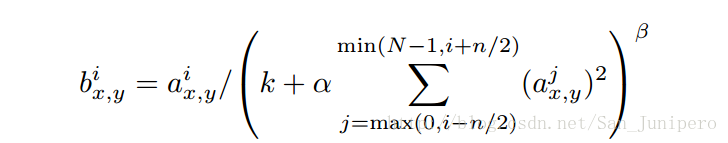
a是把第i个核用在(x,y)位置,b是归一化以后的值。
上述公式中的和Σ是n个相邻的核映射到同一个地方的值之和。
N是在这一层的核的总个数。
核映射的顺序是随意的并且是在训练前就确定的。
常数k,n,α,β是超参数,用验证集得到的。
重叠池化
CNNs中的池化层概括了在同一内核映射中,相邻神经元组的输出。一般来说,相邻池单元汇总的区域不重叠。池化层可以看做由一些相隔s个像素的池化单元组成的。每一个池化单元都概括了以该单元为中心的z×z规模大小的内容。如果我们令z=s,就是传统池化;s总体概括
网络最后的优化目标是最大化平均multinomial logistic regression。网络第2,4,5卷积层只连接到对应前一层的GPU,第3层可以和前一层任一GPU相连。响应归一化层在第1,2层卷积层后面。最大池化层在两个响应归一化层以及第5卷积层后面。ReLU用在每个卷积层和全连接层的输出上。
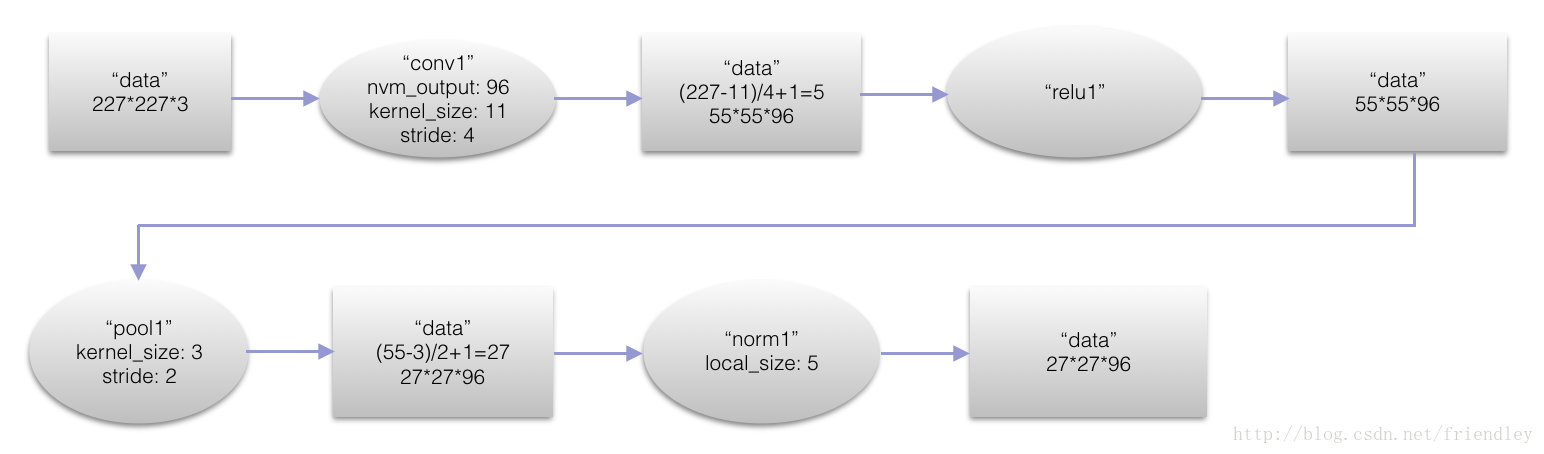
第一层卷积层(conv1)
本层的神经元数目为224*224*3=150528个,本层结束后,map的数量为96个,map的大小为55*55*96=290400。
采用96个11*11*3的kernel。在stride为4的情况下对于224*224*3的图像进行了滤波。换句话说,就是采用了11*11的卷积模版在三个通道上,间隔为4个像素的采样频率上对图像进行卷积操作。
最初的输入神经元的个数为224*224*3=150528个
得到基本的卷积数据后,先进行一次ReLU(relu1)以及Norm(norm1)变换,然后进行pooling(pool1),作为输出传递到下一层。
论文是224 * 224 * 3,实现是227 * 227 * 3。
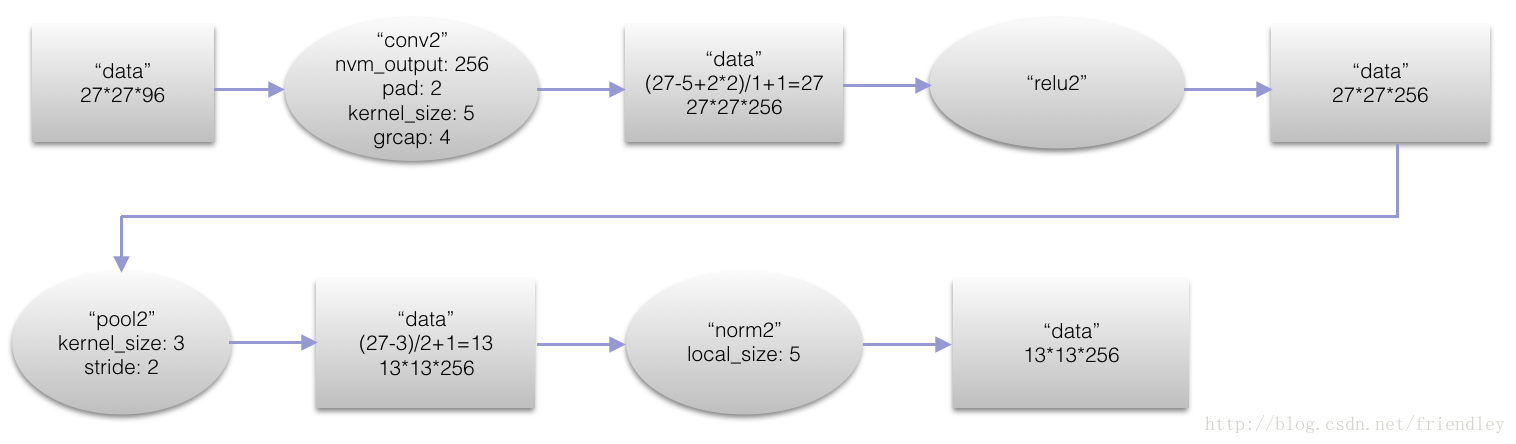
第二层卷积层(con2)
本层卷积模版(kernel)的大小是5*5*256
本层的神经元数目为27*27*96=69984个,本层结束后,map数量为256个。map的大小为13*13*256=43264。
第三层卷积层(conv3)
本层卷积模版(kernel)的大小是3*3*384
本层的神经元数目是13*13*256=43264个,本层结束后,map的数量是384个,map的大小是13*13*384=64896

第四层卷积层(conv4)
本层卷积模版(kernel)的大小是3*3*384
本层的神经元数目是13*13*384=43264个,本层结束后,map的数量是13*13*384=64896

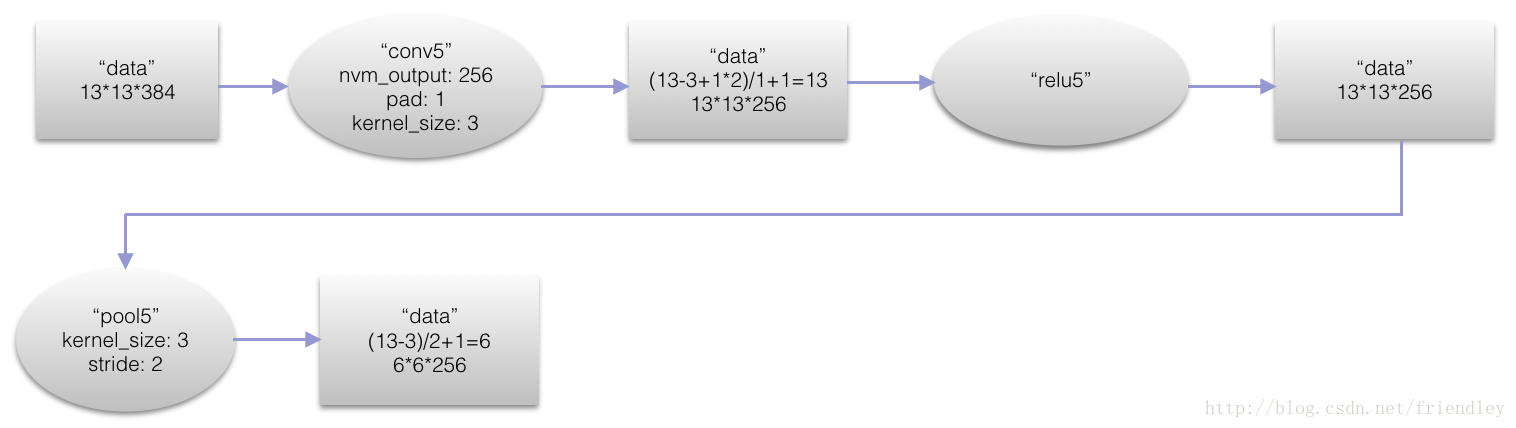
第五层卷基层(conv5)
本层卷积模版(kernel)的大小是3*3*256
本层的神经元数目是13*13*384=64896个,本层结束后,map的数量是256个,map的大小是6*6*256=43264
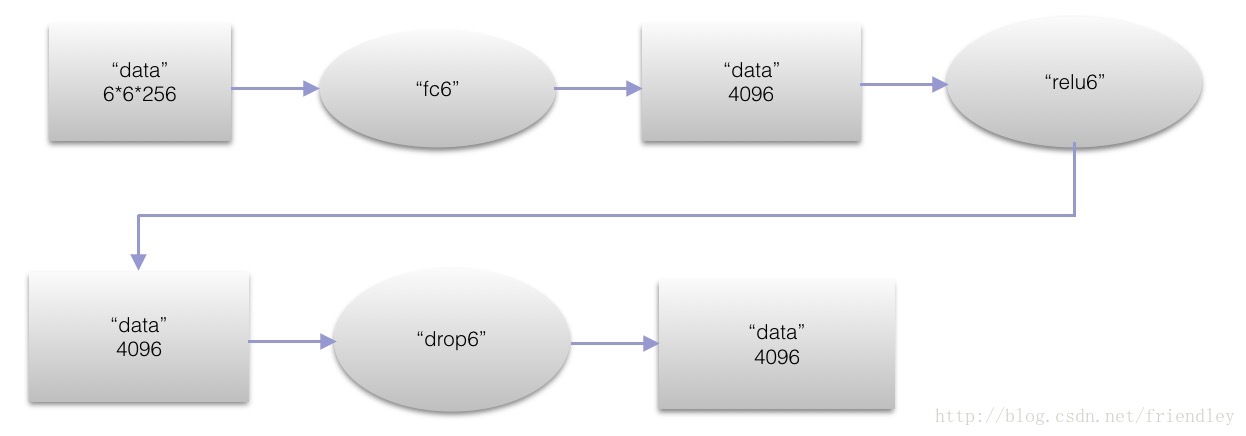
第六层全连接层(fc6)
本层输入的大小是6*6*256,然后全连接后到4096个节点,本层最终的节点为4096个。
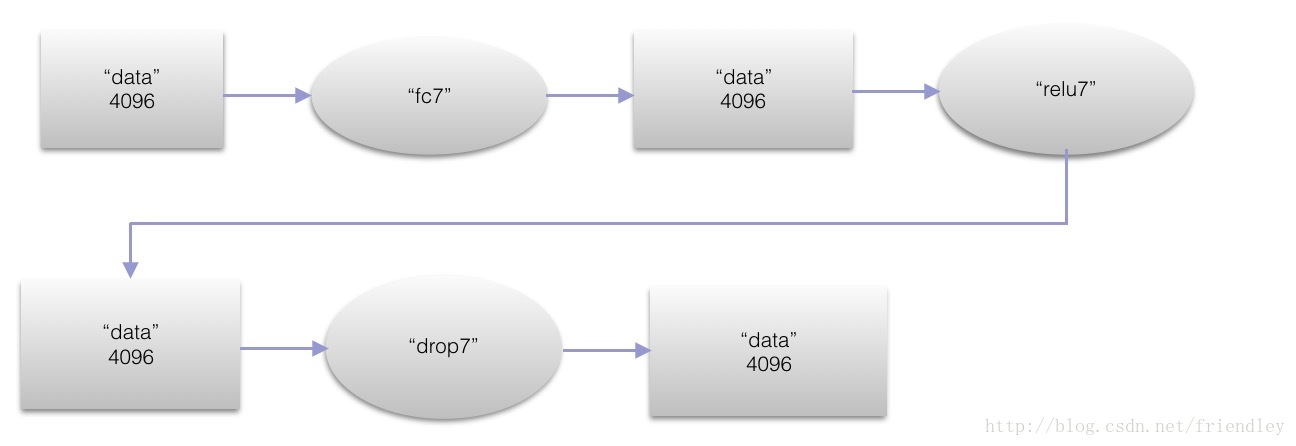
第七层全连接层(fc7)
本层输入的大小是4096,输出也是4096
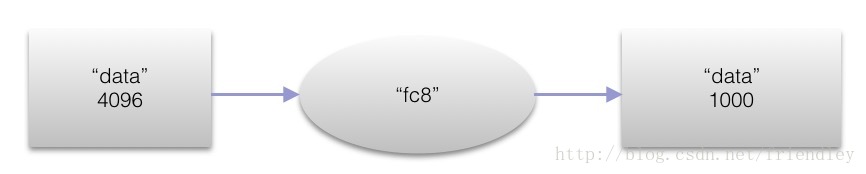
第八层全连接层(fc8)
本层输入层的大小是4096, 融合label的softmax loss输出为1000
结构图文转自:http://blog.csdn.net/friendley/article/details/78003246
Reducing Overfitting
Data Augmentation
用两种不同形式的数据扩充,都可以通过一点点计算就让原始图片发生转换,而转换的图片并不需要保存在硬盘上。我们是当GPU在训练上一批图片的时候,在CPU中用python代码生成被转换的图片。Dropout
引:http://blog.csdn.net/u011974639/article/details/76146822#4-%E5%87%8F%E5%B0%91%E8%BF%87%E6%8B%9F%E5%90%88
相关文章推荐
- 论文笔记ImageNet Classification with Deep Convolutional Neural Networks(AlexNet)
- 经典网络结构AlexNet《ImageNet Classification with Deep Convolutional Neural Networks》
- AlexNet卷积神经网络学习参考论文《ImageNet Classification with Deep Convolutional Neural NetWorks》
- 论文:ImageNet Classification with Deep Convolutional Neural Networks
- AlexNet- ImageNet Classification with Deep Convolutional Neural Networks
- AlexNet-ImageNet Classification with Deep Convolutional Neural Networks
- 论文阅读(1)——ImageNet Classification with Deep Convolutional Neural Networks
- 经典计算机视觉论文笔记——《ImageNet Classification with Deep Convolutional Neural Networks》
- Deep learning论文笔记一:ImageNet Classification with Deep Convolutional Neural Networks
- 论文笔记:ImageNet Classification with Deep Convolutional Neural Networks
- ImageNet Classification with Deep Convolutional Neural Networks (AlexNet)翻译
- 【AlexNet解读】ImageNet Classification withDeep Convolutional Neural Networks
- (占坑专用)AlexNet —— ImageNet Classification with Deep Convolutional Neural Networks
- [深度学习论文笔记][Image Classification] ImageNet Classification with Deep Convolutional Neural Networks
- AlexNet : ImageNet Classification with Deep Convolutional Neural Networks
- 经典网络结构AlexNet《ImageNet Classification with Deep Convolutional Neural Networks》
- AlexNet 《ImageNet Classification with Deep Convolutional Neural Networks》学习笔记
- AlexNet--ImageNet Classification with Deep Convolutional Neural Networks
- ImageNet Classification with Deep Convolutional Neural Networks
- 《ImageNet Classification with Deep Convolutional Neural Networks》论文阅读