TensorFlow Wide And Deep 模型详解与应用(二)
2018-02-01 15:27
661 查看
转处:http://geek.csdn.net/news/detail/235471
作者简介:汪剑,现在在出门问问负责推荐与个性化。曾在微软雅虎工作,从事过搜索和推荐相关工作。
责编:何永灿(heyc@csdn.net)
本文首发于CSDN,未经允许不得转载。
TensorFlow Wide And Deep 模型详解与应用(一)
前面讲了模型输入的特征,下面谈谈模型本身。关于 wide and deep 模型官方教程中有一段描述:The wide models and deep models are combined by summing up their final output log odds as the prediction, then feeding the prediction to a logistic loss function。从这里大概看出,线性模型与
DNN 模型进行结合的方式是对两者的预测结果进行相加,然后把相加过后的值拿去计算分类的 loss。下面我们在源代码级别把上面这段描述展开,详细分析 wide 端模型和 deep 端模型是如何实现结合的。
由于我们运用的只是分类模型,所以就不对回归模型进行分析。
DNNLinearCombinedClassifier 类继承于类 Estimator,Estimator 类继承于类 BaseEstimator。BaseEstimator 是一个抽象类,定义了通用的模型训练以及评测的函数接口 (train_model, evaluate_model, infer_model),Estimator 类中用一个统一函数 call_model_fn 来实现 train_model, evaluate_model, infer_model。
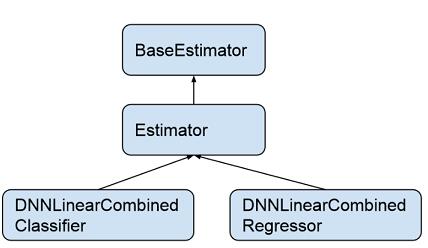
图 7 estimator 的类关系图
为了更好了解整个过程,我们看看内部函数的调用过程(代码可以参见 estimator/estimator.py):
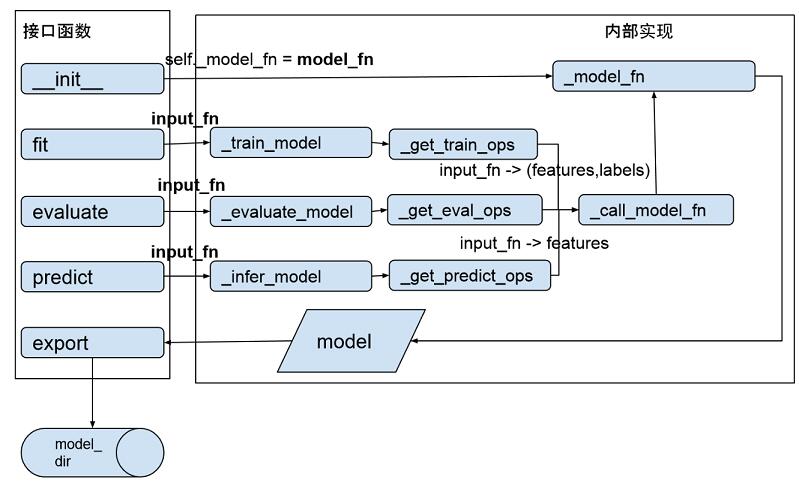
图 8 Estmiator 类的函数调用图
模型训练通过调用 BaseEstimator 的 fit() 接口开始,其调用栈是:fit -> _train_model -> _get_train_ops ->_call_model_fn(ModelKeys.TRAIN) -> _model_fn,最终_model_fn() 产生模型并通过 export 函数将模型输出到 model_dir 对应目录中。
我们把训练模型的调用过程在代码级别展开,标出关键的几个函数和数据结构,省略不关键的代码,希望能让读者看到训练模型的大致过程:
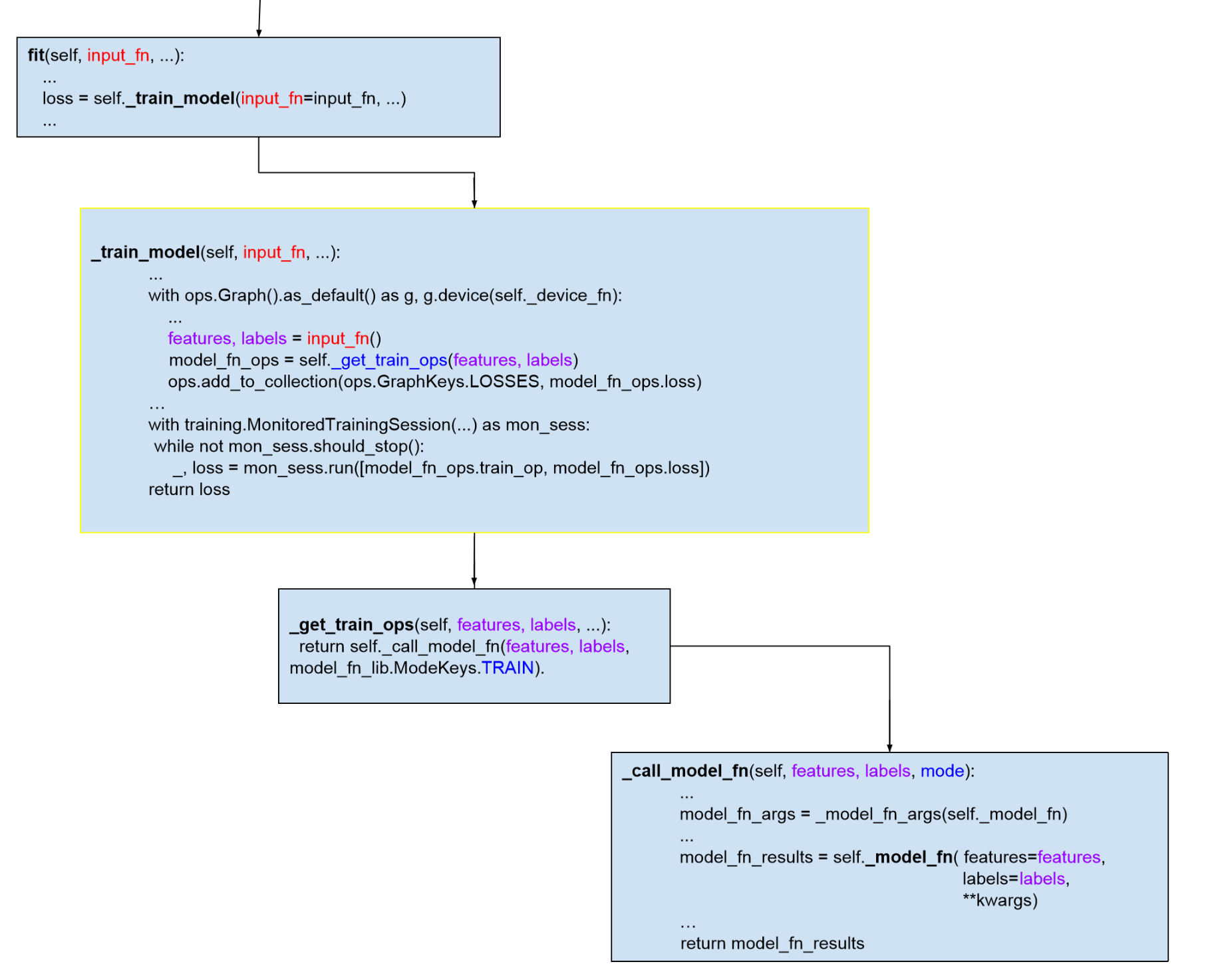
图 9 模型训练的调用栈
评测(evaluate)和预测(predict)的过程与训练(train)大致相同,读者可以通过源代码文件找到对应函数了解。可以看出,整个函数调用栈中最关键的 2 个函数是: input_fn 和 model_fn。input_fn 从输入数据中生成 features 和 labels,features 是一个 Tensor 或者是一个从特征名到 Tensor 的字典,如果 features 是一个 Tensor,程序会给这个 Tensor 一个空字符串的键值,转换成特征名到 Tensor 的字典。labels
是样本的 label 构成的 tensor。input_fn 由应用程序调用者提供实现,返回(features, labels)二元组,要求 tf.get_shape(features)[0] == tf.get_shape(labels)[0],也就是两个 tensor 的行数目得保持一致。model_fn 定义训练和评测模型的具体逻辑,如模型训练产生的误差 (model_fn_ops.loss) 以及训练算子(model_fn_ops.train_op)通过封装在 EstmiatorSpec 的对象中由
training 的 Session 进行调用。每个具体模型需要实现的是自定义的 model_fn。
DNNLinearCombinedClassifier 是如何实现自己的 model_fn 的呢?本文开头我们给出了它的初始化函数原型,进入初始化函数的实现中我们定位到代码行 model_fn=_dnn_linear_combined_model_fn。
这个就是 DNNLinearCombinedClassifier 的 model_fn。这个函数的定义如下:
features 和 labels 大家都已经知道,mode 指定 model_fn 的操作模式,目前支持 3 个值:训练模型 (model_fn.ModeKeys.TRAIN),对模型进行评测 (model_fn.ModeKeys.EVAL),根据输入特征进行预测 (model_fn.ModeKeys.PREDICT),mode 的定义可参见文件 estimator/model_fn.py。params 和 config 参数分别定义模型训练的参数以及模型运行的配置。
模型训练的整个过程可以分为如下若干步:
(1)从 params 获取参数,定义模型优化函数
(2)构建 DNN 模型
首先从 dnn_feature_columns 构造 DNN 模型输入层:
这里的 features 是 feature column key 到 tensor 的 dict,在本文前面我们对每个特征都谈了它的 insert_transformed_feature(columns_to_tensors),在构建 DNN 模型输入层之前会调用每个 FeatureColumn 的 insert_transformed_feature 函数生成一个浮点数类型的 tensor 作为 DNN 输入层的一部分。
构建完输入层后,然后至底向上进行隐藏层构建,每层的隐藏单元的个数在参数
从最后一层隐藏层到输出层建立一个全连接就完成 DNN 模型的构建了, dnn_logits 是模型输出,它是一个分类数个数的 Tensor,Tensor 的每个元素对应 1 个分类的线性激活值(linear activation: w * net + bias):
从 dnn feature columns 中构建 DNN 输入层的工作主要由函数 layers._input_from_feature_columns 完成,每个训练样本上的 dnn feature column 的值拼接成一个 dense tensor 作为 DNN 的输入。
该函数的定义如下:
举一个例子说明下拼接的结果吧,假设该批次有 2 个训练实例,real_val_col 对应一个 real_valued_column,deep_emb_col 对应一个 embedding_column,real_val_col 和 deep_emb_col 的第一个元素分别对应第一个训练实例上的 feature column 的 tensor,第二个元素对应第二个训练实例上的 feature column 的 tensor,可以参看以下演示代码的执行结果:
(3)构建线性模型
线性模型的公式是:y = W * x + b,x 从 linear_feature_columns 中构建,W 是各个特征的权重,b 是模型的偏置。每个分类的预测值存储在 linear_logits 变量中。
weighted_sum_feature_columns() 函数执行过程同构建 DNN 输入层的_input_from_feature_columns 函数执行过程比较相似,以下是它的源代码:
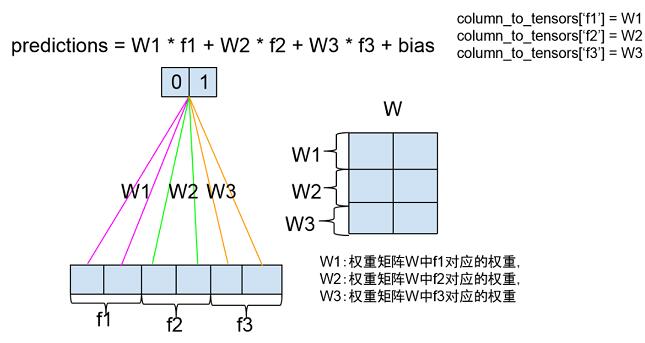
图 10 线性模型训练
(4)combine
接下来将两个模型结合成一个模型:
在原论文中给了 logistic regression 二分类情况下融合模型的预测公式:P(Y = 1|x) = σ(w^T * wide[x, φ(x)] + w『 ^T * deep[final activation] + b),其中 w^T * wide[x, φ(x)] + b 对应 linear_logits,w『 ^T * deep[final activation] 对应 dnn_logits, logits 是 wide 和 deep 模型预测结果的叠加。σ函数将模型预测结果进行变换生成各个分类的概率。
模型产生的误差分别反馈给 DNN 和线性模型进行参数更新:
head.create_model_fn_ops 完成模型算子的定义,包括损失函数计算,每个分类概率的计算,模型评测指标的计算等。DNNLinearCombinedClassifier 在初始化时根据分类个数创建 head 成员变量,如果是二分类,创建_BinaryLogisticHead 对象,如果是多分类,创建_MultiClassHead 对象。head 变量的类型定义可参考源代码文件:head.py。
我们看看二分类的_BinaryLogisticHead 类如何生成 model_fn:
二分类默认使用 sigmoid cross entropy 计算损失函数,cross entropy 乘以训练样本的权重得到训练样本的损失函数值。在批次训练中,一批训练样本的损失函数值定义为:weighted_loss = ( sum { weight[i] * loss[i]} ) / N,N 是该批训练样本的个数。
_logits_to_predictions 函数根据 PredictionKey 计算每个分类的概率或者输出最大概率的分类,logits 是模型未经变换的输出:
最终构建模型训练算子
_train_op 函数生成 training 的算子,如果 centered_bias 没有定义 (enable_centered_bias=False),返回 train_op_fn 创建的 training op; 如果定义了 centered_bias,为 centered_bias 创建 training op,并与 train_op_fn 创建的 training_op 通过 control_flow_ops.group 组成组合算子返回。centered_bias 的 training op 采用
AdagradOptimizer 作为优化函数。下图描述了 enable_centered_bias=True 的情况下 training op 的创建过程:

图 11 enable_centered_bias 情况下训练算子创建
模型的评价指标的计算在 metrics_fn 函数中完成,在 BinaryLogisticHead 中 metrics_fn 对应_metrics 函数:
到此 wide and deep 分类模型的具体细节已讲述完毕。下图将 wide and deep 模型的训练过程进行简单总结,希望对大家理解整个训练过程有所帮助。

图 12 模型训练总结
接下来考虑将模型应用到产品具体场景。我们通过 DNNLinearCombinedClassifier 构建二分类模型以最大化用户下载应用的概率。
训练和测试数据来自于半年中用户的行为日志,包括下载,使用和删除等操作行为,每条操作中记录用户 ID,应用 ID,操作行为标识,操作时间等参数,我们在用户行为基础上基于应用的标签和类别属性构建用户画像,用户的行为日志最终分别通过用户 ID 和应用 ID 关联用户画像和应用属性生成训练的输入数据:

图 13 模型构建过程
准备好输入数据后,下一步定义每条数据的标记,特征以及权重。用户下载了应用标记为 1(action = click),用户浏览了应用但是没有下载行为,则标记为 0(action = skip)。标记为 0 的训练实例的权重设定为 1.0,标记为 1 的实例权重通过计算用户下载该应用后的使用时间以及用户后来是否删除该应用来获取:1.0 + min(2, log(使用时间) * exp(-用户是否删除了该应用))。特征部分主要使用三种类型的特征:用户特征,应用特征以及用户和应用的交互特征。如论文中建议,我们将 embedding
特征和连续型特征作为 DNN 的输入,将交叉特征作为线性模型的输入。下表中列举了我们使用的部分特征:

每条训练实例中的应用与用户历史操作过的应用集合进行交叉构建交叉特征,包括:
(训练实例中用户看到的应用)交叉(用户之前的历史下载应用)
(训练实例中用户看到的应用)交叉(用户之前的历史删除应用)
在构建交叉特征时,原论文中提到的是 user impressioned app 同 user installed app 进行交叉,实际中我们需要的是将用户下载历史中的多个 app 与 impressioned app 一一进行交叉,通过一个 crossed column 是无法完成的,我们采取的方式是将用户下载历史中的应用按照下载时间排序,取最近下载的 20 个应用,标记为 1 到 20,然后用每个应用的 ID 构造一个 sparse integerized feature column,与用户的 impressioned
app ID 创建的 sparse integerized feature column 进行交叉,生成 20 个 crossed feature column:
输入到 DNN 的连续型特征我们通过定义 real valued feature column 的 normalizer 进行 L2 归一化,normalizer 定义和使用方式如下:
同时为用户下载和删除历史中的每一个应用单独构建一个 embedding column 作为 DNN 输入。
标记和特征构建好后,下一步是切分训练和测试数据集,我们按照事件的时间戳对数据按照 7:3 的比例切分成训练和测试集,并且从测试集中去掉所有在训练集中出现过的(用户,应用)对。在训练之前我们还做了 3 件事情:(1)在训练集上对部分特征做了相关性分析,看特征之间是否存在比较强的线性相关性;(2)统计训练数据上的正负样本比例,通过对正样本进行 repeated boostrap sampling 增加正样本比例。
最终模型训练中我们还尝试了:(1)enable centered bias;(2)enable layer batch normalization;(3)尝试 DNN 的其他优化函数。在我们的测试集合上模型的 AUC 如下:

可以看到: 结合模型比单个模型有一定提高,但是相对 wide 模型提高不大,主要是 DNN 模型的预测能力相比不是特别理想,分析原因可能是由于:1)训练数据量不够;2)需要为 DNN 挖掘更多更有区分能力的特征。
模型训练评测后下一步准备上线,模型需要 export 后才能被 tensorflow serving 加载使用。目前我们没有使用上 TensorFlow1.0 以后的 export_savedmodel,仍然使用的是 export 函数:
export 中通过 signature_fn 定义模型的输入和输出,signature_fn 我们是仿照 estimator.classification_signature_fn_with_prob 进行定义的,不同点是我们增加了对 named_graph_sigatures 的定义:
线上的模型服务我们启动时需要传入参数–use_saved_model=false
,这样 tensorflow serving 做 prediction 时会使用 SessionBundlePredict,输入从』input』字段获取,输出从』output』字段获取,具体可看 TensorflowPredictor 的代码。业务服务用 C++编写 client 构造 PredictRequest 来访问模型服务:
以上是关于 wide and deep 模型我们的分享,随着 TensorFlow 的逐渐演进,模型代码有可能会发生比较大的改变,希望借这个分享让各位读者对 TensorFlow wide and deep 模型本身的思想和 TensorFlow 的编程方式有一定了解。
以下是 wide and deep 模型的参考资料:
[1] wide and deep 模型的原论文:https://arxiv.org/pdf/1606.07792.pdf
[2] wide and deep 模型的 tutorial: https://www.tensorflow.org/tutorials/wide_and_deep
作者简介:汪剑,现在在出门问问负责推荐与个性化。曾在微软雅虎工作,从事过搜索和推荐相关工作。
责编:何永灿(heyc@csdn.net)
本文首发于CSDN,未经允许不得转载。
TensorFlow Wide And Deep 模型详解与应用(一)
前面讲了模型输入的特征,下面谈谈模型本身。关于 wide and deep 模型官方教程中有一段描述:The wide models and deep models are combined by summing up their final output log odds as the prediction, then feeding the prediction to a logistic loss function。从这里大概看出,线性模型与
DNN 模型进行结合的方式是对两者的预测结果进行相加,然后把相加过后的值拿去计算分类的 loss。下面我们在源代码级别把上面这段描述展开,详细分析 wide 端模型和 deep 端模型是如何实现结合的。
由于我们运用的只是分类模型,所以就不对回归模型进行分析。
DNNLinearCombinedClassifier 类继承于类 Estimator,Estimator 类继承于类 BaseEstimator。BaseEstimator 是一个抽象类,定义了通用的模型训练以及评测的函数接口 (train_model, evaluate_model, infer_model),Estimator 类中用一个统一函数 call_model_fn 来实现 train_model, evaluate_model, infer_model。
图 7 estimator 的类关系图
为了更好了解整个过程,我们看看内部函数的调用过程(代码可以参见 estimator/estimator.py):
图 8 Estmiator 类的函数调用图
模型训练通过调用 BaseEstimator 的 fit() 接口开始,其调用栈是:fit -> _train_model -> _get_train_ops ->_call_model_fn(ModelKeys.TRAIN) -> _model_fn,最终_model_fn() 产生模型并通过 export 函数将模型输出到 model_dir 对应目录中。
我们把训练模型的调用过程在代码级别展开,标出关键的几个函数和数据结构,省略不关键的代码,希望能让读者看到训练模型的大致过程:
图 9 模型训练的调用栈
评测(evaluate)和预测(predict)的过程与训练(train)大致相同,读者可以通过源代码文件找到对应函数了解。可以看出,整个函数调用栈中最关键的 2 个函数是: input_fn 和 model_fn。input_fn 从输入数据中生成 features 和 labels,features 是一个 Tensor 或者是一个从特征名到 Tensor 的字典,如果 features 是一个 Tensor,程序会给这个 Tensor 一个空字符串的键值,转换成特征名到 Tensor 的字典。labels
是样本的 label 构成的 tensor。input_fn 由应用程序调用者提供实现,返回(features, labels)二元组,要求 tf.get_shape(features)[0] == tf.get_shape(labels)[0],也就是两个 tensor 的行数目得保持一致。model_fn 定义训练和评测模型的具体逻辑,如模型训练产生的误差 (model_fn_ops.loss) 以及训练算子(model_fn_ops.train_op)通过封装在 EstmiatorSpec 的对象中由
training 的 Session 进行调用。每个具体模型需要实现的是自定义的 model_fn。
DNNLinearCombinedClassifier 是如何实现自己的 model_fn 的呢?本文开头我们给出了它的初始化函数原型,进入初始化函数的实现中我们定位到代码行 model_fn=_dnn_linear_combined_model_fn。
这个就是 DNNLinearCombinedClassifier 的 model_fn。这个函数的定义如下:
def _dnn_linear_combined_model_fn(features, labels, mode, params, config= None)
features 和 labels 大家都已经知道,mode 指定 model_fn 的操作模式,目前支持 3 个值:训练模型 (model_fn.ModeKeys.TRAIN),对模型进行评测 (model_fn.ModeKeys.EVAL),根据输入特征进行预测 (model_fn.ModeKeys.PREDICT),mode 的定义可参见文件 estimator/model_fn.py。params 和 config 参数分别定义模型训练的参数以及模型运行的配置。
模型训练的整个过程可以分为如下若干步:
(1)从 params 获取参数,定义模型优化函数
// 将输入的特征统一为字符串到 tensor 的 dict
features = _get_feature_dict(features)
// 定义线性模型的优化函数
linear_optimizer = params.get("linear_optimizer") or "Ftrl"
linear_optimizer = _get_optimizer(linear_optimizer)
// 定义 DNN 模型的优化函数
dnn_optimizer = params.get("dnn_optimizer") or "Adagrad"
dnn_optimizer = _get_optimizer(dnn_optimizer)(2)构建 DNN 模型
首先从 dnn_feature_columns 构造 DNN 模型输入层:
dnn_feature_columns = params.get("dnn_feature_columns")
// dnn_feature_columns 中包括 DNN 模型需要的所有连续特征和 embedding 特征
net = layers.input_from_feature_columns(columns_to_tensors=features,
feature_columns=dnn_feature_columns,
weight_collections=[dnn_parent_scope],
scope=dnn_input_scope)这里的 features 是 feature column key 到 tensor 的 dict,在本文前面我们对每个特征都谈了它的 insert_transformed_feature(columns_to_tensors),在构建 DNN 模型输入层之前会调用每个 FeatureColumn 的 insert_transformed_feature 函数生成一个浮点数类型的 tensor 作为 DNN 输入层的一部分。
构建完输入层后,然后至底向上进行隐藏层构建,每层的隐藏单元的个数在参数
dnn_hidden_units 中定义:
dnn_hidden_units = params.get("dnn_hidden_units")
for layer_id, num_hidden_units in enumerate(dnn_hidden_units):
// 从输入层或者是下面一层隐藏层构建新的隐藏层
// dnn_activation_fn 定义隐藏层的激活函数,默认使用 RELU
dnn_activation_fn = params.get("dnn_activation_fn") or nn.relu。
net = layers.fully_connected(net,num_hidden_units,activation_fn=dnn_activation_fn,
variables_collections=[dnn_parent_scope], scope=dnn_hidden_layer_scope)
// 模型训练中对隐藏层进行 drop-out
// dnn_dropout 是舍弃隐藏单元输出的概率
dnn_dropout = params.get("dnn_dropout")
if dnn_dropout is not None and mode == model_fn.ModeKeys.TRAIN:
net = layers.dropout(net, keep_prob=(1.0 - dnn_dropout))从最后一层隐藏层到输出层建立一个全连接就完成 DNN 模型的构建了, dnn_logits 是模型输出,它是一个分类数个数的 Tensor,Tensor 的每个元素对应 1 个分类的线性激活值(linear activation: w * net + bias):
with variable_scope.variable_scope( "logits", values=(net,)) as dnn_logits_scope: dnn_logits = layers.fully_connected( net, head.logits_dimension, // 分类个数 activation_fn=None, // 输出层不做非线性变换 variables_collections=[dnn_parent_scope], scope=dnn_logits_scope)
从 dnn feature columns 中构建 DNN 输入层的工作主要由函数 layers._input_from_feature_columns 完成,每个训练样本上的 dnn feature column 的值拼接成一个 dense tensor 作为 DNN 的输入。
该函数的定义如下:
def _input_from_feature_columns( columns_to_tensors, feature_columns, weight_collections, trainable, scope, output_rank, default_name) transformer = _Transformer(columns_to_tensors) for column in sorted(set(feature_columns), key=lambda x: x.key): // 调用 feature column 的特征变换函数 insert_transformed_feature() // 返回 feature column 变换后的 tensor: columns_to_tensors[column]。 transformed_tensor = transformer.transform(column) try: // 构建_EmbeddingColumn 的 embedding arguments = column._deep_embedding_lookup_arguments(transformed_tensor) output_tensors.append(_embeddings_from_arguments(column, arguments, weight_collections, trainable, output_rank=output_rank)) except NotImplementedError as ee: // 构建_RealValuedColumn 的 tensor try: output_tensors.append(column._to_dnn_input_layer(transformed_tensor,weight_collections, trainable,output_rank=output_rank)) except ValueError as e: // output_tensors 数组每个元素对应一个 feature column 在该批次训练数据中每个训练实例上生成的 tensor, // 根据 output_rank - 1 对 output_tensor 中的每个 tensor 在指定维度上进行拼接 return array_ops.concat(output_tensors, output_rank - 1)
举一个例子说明下拼接的结果吧,假设该批次有 2 个训练实例,real_val_col 对应一个 real_valued_column,deep_emb_col 对应一个 embedding_column,real_val_col 和 deep_emb_col 的第一个元素分别对应第一个训练实例上的 feature column 的 tensor,第二个元素对应第二个训练实例上的 feature column 的 tensor,可以参看以下演示代码的执行结果:
real_val_col = [[0.1,0.2], [0.3,0.4]] deep_emb_col = [[0.01,0.02,0.03], [0.04,0.05,0.06]] output_tensors = [] output_tensors.append(real_val_col) output_tensors.append(deep_emb_col) output_rank = 2 dnn_input = array_ops.concat(output_tensors,output_rank - 1) tf.InteractiveSession().run(c) array([ [ 0.1 , 0.2, 0.01, 0.02, 0.03], [ 0.30000001, 0.40000001, 0.04, 0.05,0.06]], dtype=float32) 可以看到最终拼接的结果是 [ [real_val_col[0], deep_emb_col[0]] [real_val_col[1], deep_emb_col[1]] ]
(3)构建线性模型
线性模型的公式是:y = W * x + b,x 从 linear_feature_columns 中构建,W 是各个特征的权重,b 是模型的偏置。每个分类的预测值存储在 linear_logits 变量中。
linear_logits, _, _ = layers.weighted_sum_from_feature_columns(columns_to_tensors=features, feature_columns=linear_feature_columns, num_outputs=head.logits_dimension, // 分类数 weight_collections=[linear_parent_scope], scope=scope)
weighted_sum_feature_columns() 函数执行过程同构建 DNN 输入层的_input_from_feature_columns 函数执行过程比较相似,以下是它的源代码:
// 每个特征与权重矩阵相乘得到每个分类上该特征的预测分数,将每个分类上特征的预测分数累加后加上偏置得到
// 对每个分类的最终预测值,如图 10
for column in sorted(set(feature_columns), key=lambda x: x.key):
transformed_tensor = transformer.transform(column)
try:
// 线性模型使用_wide_embedding_lookup_arguments 返回的 LinearEmbeddingArguments 构建权重矩阵
// SparsColumn, WeightedSparseColumn 或 Crossed Column 定义了 wide_embedding_lookup_arguments
embedding_lookup_arguments = column._wide_embedding_lookup_arguments( transformed_tensor)
// create_embedding_lookup() 的实现同 embedding_lookup_arguments() 比较类似,variable 中返回权重矩
// 阵 W,predictions 返回 W * X
variable, predictions = _create_embedding_lookup(column, columns_to_tensors,
embedding_lookup_arguments, num_outputs,
trainable, weight_collections)
except NotImplementedError:
// 其他特征直接作为线性模型的输入
// 如果输入是 Sparse tensor,需要转换为 dense tensor。
tensor = column._to_dense_tensor(transformed_tensor)
// 展开成二维数组 [batch_size, dimension of feature column]
tensor = _maybe_reshape_input_tensor( tensor, column.name, output_rank=2)
// variable 定义线性模型的权重 W
// W 是二维矩阵,行是特征的取值个数,列是分类个数
// W 初始化为零矩阵
// 设置 trainable=True, W 加入 GraphKeys.TRAINABLE_VARIABLES
variable = [ contrib_variables.model_variable(name='weight',
shape=[tensor.get_shape()[1], num_outputs],
initializer=init_ops.zeros_initializer(),
trainable=trainable,
collections=weight_collections)]
// y』 = W * x
predictions = math_ops.matmul(tensor, variable[0], name='matmul')
output_tensors.append(array_ops.reshape(predictions, shape=(-1, num_outputs)))
column_to_variable[column] = variable
//在每个分类上,将所有 feature column 对该分类的预测值相加
predictions_no_bias = math_ops.add_n(output_tensors)
// bias 是模型的偏置项,是一个一维向量,向量大小是输出分类的个数,初始化为 0
// 设置 Trainable=True, bias 加入 GraphKeys.TRAINABLE_VARIABLES
bias = contrib_variables.model_variable('bias_weight',shape=[num_outputs],
initializer=init_ops.zeros_initializer(),trainable=trainable,
collections=_add_variable_collection(weight_collections))
// predictions: W*x+b
predictions = nn_ops.bias_add(predictions_no_bias, bias)
return predictions, column_to_variable, bias图 10 线性模型训练
(4)combine
接下来将两个模型结合成一个模型:
if dnn_logits is not None and linear_logits is not None: logits = dnn_logits + linear_logits
在原论文中给了 logistic regression 二分类情况下融合模型的预测公式:P(Y = 1|x) = σ(w^T * wide[x, φ(x)] + w『 ^T * deep[final activation] + b),其中 w^T * wide[x, φ(x)] + b 对应 linear_logits,w『 ^T * deep[final activation] 对应 dnn_logits, logits 是 wide 和 deep 模型预测结果的叠加。σ函数将模型预测结果进行变换生成各个分类的概率。
模型产生的误差分别反馈给 DNN 和线性模型进行参数更新:
def _make_training_op(training_loss): … // training_loss 反馈到 DNN 模型 // DNNLinearCombinedClassifier 中定义的 dnn_optimizer 用在这里 if dnn_logits is not None: train_ops.append( optimizers.optimize_loss( loss=training_loss,learning_rate=_DNN_LEARNING_RATE, optimizer=dnn_optimizer, …) // training_loss 反馈到线性模型,DNNLinearCombinedClassifier 中定义的 linear_optimizer 用在这 if linear_logits is not None: train_ops.append( optimizers.optimize_loss( loss=training_loss, learning_rate=_linear_learning_rate(len(linear_feature_columns)), optimizer=linear_optimizer, ... ) return head.create_model_fn_ops(features=features,mode=mode,labels=labels, train_op_fn=_make_training_op, logits=logits)
head.create_model_fn_ops 完成模型算子的定义,包括损失函数计算,每个分类概率的计算,模型评测指标的计算等。DNNLinearCombinedClassifier 在初始化时根据分类个数创建 head 成员变量,如果是二分类,创建_BinaryLogisticHead 对象,如果是多分类,创建_MultiClassHead 对象。head 变量的类型定义可参考源代码文件:head.py。
head = head_lib.multi_class_head( n_classes=n_classes,weight_column_name=weight_column_name, enable_centered_bias=enable_centered_bias)
我们看看二分类的_BinaryLogisticHead 类如何生成 model_fn:
def create_model_fn_ops(self, features,mode,labels=None, train_op_fn=None,logits=None,logits_input=None, scope=None): with variable_scope.variable_scope(scope, default_name=self.head_name or "binary_logistic_head", values=(tuple(six.itervalues(features)) + (labels, logits, logits_input))): // 生成 label tensor,维度是 1 个 batch 中训练样本的个数,每个元素是一个样本的标注 labels = self._transform_labels(mode=mode, labels=labels) // 生成 logits tensor,维度与 label tensor 保持一致,每个元素是一个训练样本的模型输出值 logits = _logits(logits_input, logits, self.logits_dimension) // 构建模型训练算子 return _create_model_fn_ops(features=features, mode=mode, loss_fn=self._loss_fn, // 损失函数,默认使用交叉熵损失 (_log_loss_with_two_classes) logits_to_predictions_fn = self._logits_to_predictions, // 计算每个分类的概率,对应上面提到的σ函数 metrics_fn=self._metrics, // 模型指标计算,包括 AUC,accuracy 等,见 MetricKey 的定义 ... labels=labels, train_op_fn=train_op_fn, // 根据训练误差进行模型参数的更新函数 logits=logits, // 模型的预测值 ...)
二分类默认使用 sigmoid cross entropy 计算损失函数,cross entropy 乘以训练样本的权重得到训练样本的损失函数值。在批次训练中,一批训练样本的损失函数值定义为:weighted_loss = ( sum { weight[i] * loss[i]} ) / N,N 是该批训练样本的个数。
def _log_loss_with_two_classes(labels, logits, weights=None): with ops.name_scope(None, "log_loss_with_two_classes", (logits, labels)) as name: logits = ops.convert_to_tensor(logits) labels = math_ops.to_float(labels) // label 转换为 float 类型的数组 ... loss = nn.sigmoid_cross_entropy_with_logits(labels=labels, logits=logits, name=name) return _compute_weighted_loss(loss, weights)
_logits_to_predictions 函数根据 PredictionKey 计算每个分类的概率或者输出最大概率的分类,logits 是模型未经变换的输出:
def _logits_to_predictions(self, logits):
with ops.name_scope(None, "predictions", (logits,)):
two_class_logits = _one_class_to_two_class_logits(logits)
return {
// LOGITS:直接输出模型对每个分类的预测值
prediction_key.PredictionKey.LOGITS: logits,
// LOGISITC: simgoid 变换
prediction_key.PredictionKey.LOGISTIC:
math_ops.sigmoid(logits, name=prediction_key.PredictionKey.LOGISTIC),
// SOFTMAX: softmax 变换
prediction_key.PredictionKey.PROBABILITIES:
nn.softmax( two_class_logits, name=prediction_key.PredictionKey.PROBABILITIES),
// CLASSES: 预测值最大的类别
prediction_key.PredictionKey.CLASSES:
math_ops.argmax( two_class_logits, 1, name=prediction_key.PredictionKey.CLASSES)
}最终构建模型训练算子
def _create_model_fn_ops(features, mode, loss_fn, logits_to_predictions_fn, metrics_fn,
create_output_alternatives_fn, labels=None, train_op_fn=None,
logits=None, logits_dimension=None, head_name=None,
weight_column_name=None,enable_centered_bias=False):
// 源代码中对 enable_centered_bias 的解释:
// enable_centered_bias: A bool. If True, estimator will learn a centered bias variable for each class. Rest of
// the model structure learns the residual after centered bias.
// 融合模型中,centered bias 相当于在每个分类的输出中加上 bias variable:
// logits = (dnn_logits + linear_logits) + centered_bias,
// 分别为 (dnn_logits+linear_logits) 以及 centered_bias 计算 loss 生成 training op
if enable_centered_bias:
centered_bias = _centered_bias(logits_dimension, head_name)
{
// centered_bias 的第一个维度是分类个数,初始化为 0,trainable 设置为 True
centered_bias = variable_scope.variable(name="centered_bias_weight",
initial_value=array_ops.zeros(shape=(logits_dimension,)), trainable=True)
return centered_bias
}
logits = nn.bias_add(logits, centered_bias)
predictions = logits_to_predictions_fn(logits)
// 计算模型的损失
if (mode != model_fn.ModeKeys.INFER) and (labels is not None):
// input_fn 返回的 features dictionary 中 weight_column_name 列对应的是 weight tensor
weight_tensor = _weight_tensor(features, weight_column_name)
// logits 对应 dnn_logits + linear_logits + centered_bias
loss, weighted_average_loss = loss_fn(labels, logits, weight_tensor)
//根据 loss 进行参数更新,计算评测指标
if mode == model_fn.ModeKeys.TRAIN:
batch_size = array_ops.shape(logits)[0]
// 生成 training op
train_op = _train_op(loss, labels, train_op_fn, centered_bias, batch_size, loss_fn, weight_tensor)
// 生成 metric op
eval_metric_ops = metrics_fn(weighted_average_loss, predictions, labels, weight_tensor)
// 返回模型算子
return model_fn.ModelFnOps( mode=mode, predictions=predictions, // 分类预测值
loss=loss, // 模型的误差损失
train_op=train_op, // 模型训练算子,定义模型参数的更新函数,包括 DNN 和线
// 性模型的参数以及 centered_bias 参数
eval_metric_ops=eval_metric_ops, // 模型指标评测算子
output_alternatives=create_output_alternatives_fn(predictions))
}_train_op 函数生成 training 的算子,如果 centered_bias 没有定义 (enable_centered_bias=False),返回 train_op_fn 创建的 training op; 如果定义了 centered_bias,为 centered_bias 创建 training op,并与 train_op_fn 创建的 training_op 通过 control_flow_ops.group 组成组合算子返回。centered_bias 的 training op 采用
AdagradOptimizer 作为优化函数。下图描述了 enable_centered_bias=True 的情况下 training op 的创建过程:
图 11 enable_centered_bias 情况下训练算子创建
def _train_op(loss, labels, train_op_fn, centered_bias, batch_size, loss_fn, weights)
{
if centered_bias is not None:
centered_bias_step = _centered_bias_step(centered_bias=centered_bias, batch_size=batch_size,
labels=labels, loss_fn=loss_fn, weights=weights)
else:
centered_bias_step = None
with ops.name_scope(None, "train_op", (loss, labels)):
train_op = train_op_fn(loss)
if centered_bias_step is not None:
train_op = control_flow_ops.group(train_op, centered_bias_step)
return train_op
}
def _centered_bias_step(centered_bias, batch_size, labels, loss_fn, weights):
"""Creates and returns training op for centered bias."""
with ops.name_scope(None, "centered_bias_step", (labels,)) as name:
logits_dimension = array_ops.shape(centered_bias)[0]
// logits 是 [batch_size,num of output classes] 的二维数组,数组中每个元素的值是 centered_bias
logits = array_ops.reshape(array_ops.tile(centered_bias, (batch_size,)),(batch_size, logits_dimension))
with ops.name_scope(None, "centered_bias", (labels, logits)):
// 对 centered bias variable 计算 loss,centered_bias_loss 是一个 batch 中 loss 的平均值
centered_bias_loss = math_ops.reduce_mean(loss_fn(labels, logits, weights), name="training_loss")
# Learn central bias by an optimizer. 0.1 is a convervative learning rate for a single variable.
// centered_bias_loss 是 centered_bias 同 label 比较后产生的 loss,同 training 模型产生的 loss 是独立的
return training.AdagradOptimizer(0.1).minimize(centered_bias_loss, var_list=(centered_bias,),
name=name)
}模型的评价指标的计算在 metrics_fn 函数中完成,在 BinaryLogisticHead 中 metrics_fn 对应_metrics 函数:
// eval_loss: _compute_weighted_loss() 返回一个 batch 中 per example loss 的平均值
// prediction: _logits_to_prediction() 返回一个 batch 中 per example 的 prediction
// labels: 样本标注,weights: 样本权重
def _metrics(self, eval_loss, predictions, labels, weights):
"""Returns a dict of metrics keyed by name."""
with ops.name_scope("metrics", values=([eval_loss, labels, weights] + list(six.itervalues(predictions)))):
classes = predictions[prediction_key.PredictionKey.CLASSES]
logistic = predictions[prediction_key.PredictionKey.LOGISTIC]
metrics = {_summary_key(self.head_name, mkey.LOSS): metrics_lib.streaming_mean(eval_loss)}
metrics[_summary_key(self.head_name, mkey.ACCURACY)] =
(metrics_lib.streaming_accuracy(classes, labels, weights))
metrics[_summary_key(self.head_name, mkey.AUC)] = ( _streaming_auc(logistic, labels, weights))
metrics[_summary_key(self.head_name, mkey.AUC_PR)] = ( _streaming_auc(logistic, labels, weights,
curve="PR"))
return metrics到此 wide and deep 分类模型的具体细节已讲述完毕。下图将 wide and deep 模型的训练过程进行简单总结,希望对大家理解整个训练过程有所帮助。
图 12 模型训练总结
Wide And Deep 模型应用
接下来考虑将模型应用到产品具体场景。我们通过 DNNLinearCombinedClassifier 构建二分类模型以最大化用户下载应用的概率。训练和测试数据来自于半年中用户的行为日志,包括下载,使用和删除等操作行为,每条操作中记录用户 ID,应用 ID,操作行为标识,操作时间等参数,我们在用户行为基础上基于应用的标签和类别属性构建用户画像,用户的行为日志最终分别通过用户 ID 和应用 ID 关联用户画像和应用属性生成训练的输入数据:
图 13 模型构建过程
准备好输入数据后,下一步定义每条数据的标记,特征以及权重。用户下载了应用标记为 1(action = click),用户浏览了应用但是没有下载行为,则标记为 0(action = skip)。标记为 0 的训练实例的权重设定为 1.0,标记为 1 的实例权重通过计算用户下载该应用后的使用时间以及用户后来是否删除该应用来获取:1.0 + min(2, log(使用时间) * exp(-用户是否删除了该应用))。特征部分主要使用三种类型的特征:用户特征,应用特征以及用户和应用的交互特征。如论文中建议,我们将 embedding
特征和连续型特征作为 DNN 的输入,将交叉特征作为线性模型的输入。下表中列举了我们使用的部分特征:
每条训练实例中的应用与用户历史操作过的应用集合进行交叉构建交叉特征,包括:
(训练实例中用户看到的应用)交叉(用户之前的历史下载应用)
(训练实例中用户看到的应用)交叉(用户之前的历史删除应用)
在构建交叉特征时,原论文中提到的是 user impressioned app 同 user installed app 进行交叉,实际中我们需要的是将用户下载历史中的多个 app 与 impressioned app 一一进行交叉,通过一个 crossed column 是无法完成的,我们采取的方式是将用户下载历史中的应用按照下载时间排序,取最近下载的 20 个应用,标记为 1 到 20,然后用每个应用的 ID 构造一个 sparse integerized feature column,与用户的 impressioned
app ID 创建的 sparse integerized feature column 进行交叉,生成 20 个 crossed feature column:
impress_col = sparse_integerized_feat_column(impressioned_app.ID) for i in (1,20): wide_col = sparse_integerized_feat_column(download_app[i].ID) cross_col = crossed_column(impress_col, wide_col)
输入到 DNN 的连续型特征我们通过定义 real valued feature column 的 normalizer 进行 L2 归一化,normalizer 定义和使用方式如下:
def l2_real_val_col_normalizer(x)
return tf.nn.l2_normalize(x, 0)
real_valued_col = tf.contrib.layers.real_valued_column("real_feat_col", normalizer = l2_real_val_col_normalizer)
L1 归一化可以定义如下 normalizer:
def l1_real_val_col_normalizer(x)
sum = math_ops.reduce_sum(math_ops.abs(x), 0, keep_dims=True)
inv_norm = 1.0 / (math_ops.maximum(sum, epsilon))
return math_ops.multiply(x, inv_norm)同时为用户下载和删除历史中的每一个应用单独构建一个 embedding column 作为 DNN 输入。
标记和特征构建好后,下一步是切分训练和测试数据集,我们按照事件的时间戳对数据按照 7:3 的比例切分成训练和测试集,并且从测试集中去掉所有在训练集中出现过的(用户,应用)对。在训练之前我们还做了 3 件事情:(1)在训练集上对部分特征做了相关性分析,看特征之间是否存在比较强的线性相关性;(2)统计训练数据上的正负样本比例,通过对正样本进行 repeated boostrap sampling 增加正样本比例。
最终模型训练中我们还尝试了:(1)enable centered bias;(2)enable layer batch normalization;(3)尝试 DNN 的其他优化函数。在我们的测试集合上模型的 AUC 如下:
可以看到: 结合模型比单个模型有一定提高,但是相对 wide 模型提高不大,主要是 DNN 模型的预测能力相比不是特别理想,分析原因可能是由于:1)训练数据量不够;2)需要为 DNN 挖掘更多更有区分能力的特征。
模型训练评测后下一步准备上线,模型需要 export 后才能被 tensorflow serving 加载使用。目前我们没有使用上 TensorFlow1.0 以后的 export_savedmodel,仍然使用的是 export 函数:
m.export(export_dir=export_dir, use_deprecated_input_fn=True,signature_fn=signature_fn, exports_to_keep=3)
export 中通过 signature_fn 定义模型的输入和输出,signature_fn 我们是仿照 estimator.classification_signature_fn_with_prob 进行定义的,不同点是我们增加了对 named_graph_sigatures 的定义:
def signature_fn(examples, unused_features, predictions):
if isinstance(predictions, dict):
default_signature = exporter.classification_signature( examples, scores_tensor=predictions['probabilities'])
named_graph_signatures = {
'inputs': exporter.generic_signature({'values': examples}),
'outputs': exporter.generic_signature({'preds': predictions['probabilities']})}
else:
default_signature = exporter.classification_signature( examples, scores_tensor=predictions)
named_graph_signatures = {
'inputs': exporter.generic_signature({'values': examples}),
'outputs': exporter.generic_signature({'preds': predictions})}
return default_signature, named_graph_signatures线上的模型服务我们启动时需要传入参数–use_saved_model=false
,这样 tensorflow serving 做 prediction 时会使用 SessionBundlePredict,输入从』input』字段获取,输出从』output』字段获取,具体可看 TensorflowPredictor 的代码。业务服务用 C++编写 client 构造 PredictRequest 来访问模型服务:
using tensorflow::DataType; using tensorflow::Example; using tensorflow::Feature; using tensorflow::TensorProto; using tensorflow::serving::PredictRequest; using tensorflow::serving::PredictResponse; using tensorflow::serving::PredictionService; Example example; google::protobuf::Map<string, Feature>& feature = *example.mutable_features()->mutable_feature(); Feature feature; feature.mutable_float_list()->add_value(1.0); feature[“key”] = feature; string serialized_example; example.SerializeToString(&serialized_example); TensorProto tensor_proto; tensor_proto.set_dtype(DataType::DT_STRING); tensor_proto.add_string_val(serialized_example); tensor_proto.mutable_tensor_shape()->add_dim()->set_size(1); PredictRequest request; request.mutable_model_spec()->set_name(FLAGS_model_spec); (*request.mutable_inputs())["values"] = tensor_proto; PredictResponse resp; client.Predict(request, &resp);
以上是关于 wide and deep 模型我们的分享,随着 TensorFlow 的逐渐演进,模型代码有可能会发生比较大的改变,希望借这个分享让各位读者对 TensorFlow wide and deep 模型本身的思想和 TensorFlow 的编程方式有一定了解。
以下是 wide and deep 模型的参考资料:
[1] wide and deep 模型的原论文:https://arxiv.org/pdf/1606.07792.pdf
[2] wide and deep 模型的 tutorial: https://www.tensorflow.org/tutorials/wide_and_deep

相关文章推荐
- TensorFlow Wide And Deep 模型详解与应用(一)
- TensorFlow Wide And Deep 模型详解与应用 TensorFlow Wide-And-Deep 阅读344 作者简介:汪剑,现在在出门问问负责推荐与个性化。曾在微软雅虎工作,
- TensorFlow Wide And Deep 模型详解与应用
- TensorFlow and deep learning without a PhD
- TensorFlow学习笔记9----TensorFlow Wide & Deep Learning Tutorial
- TensorFlow and deep learning,without a PhD
- 翻译 | Keras : Deep Learning library for Tensorflow and Theano
- TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)
- The Wide and Deep Learning Model(译文+Tensorlfow源码解析) 原创 2017年11月03日 22:14:47 标签: 深度学习 / 谷歌 / tensorf
- 笔记——TensorFlow and deep learning, without a PhD
- 深度学习教程 TensorFlow and Deep Learning Tutorials
- Tensorflow and deep learning, without a PhD实现过程中遇到的问题及解决方法
- TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)
- DeepLearnToolbox代码详解——SAE,DAE模型
- TensorFlow 从入门到精通(六):tensorflow.nn 详解
- [置顶] 罗斯基白话:TensorFlow+实战系列(一)之详解Tensor与Flow
- 解决PyCharm ImportError: No module named tensorflow 详解
- tensorflow object_detection 用自己的数据训练目标检测模型Mobilenet
- android NDK 神经网络API——是给tensorflow lite调用的底层API,应用开发者使用tensorflow lite即可
- Machine Learning with Scikit-Learn and Tensorflow 6.4 CART算法