Hive 窗口函数、分析函数
2018-01-31 09:52
471 查看
网址:https://www.cnblogs.com/skyEva/p/5730531.html
语法是:
ntile (num) over ([partition_clause] order_by_clause) as your_bucket_num
然后可以根据桶号,选取前或后 n分之几的数据。
给了用户和每个用户对应的消费信息表, 计算花费前50%的用户的平均消费;
SQL很熟悉的3个组内排序函数了。语法一样:
R() over (partion by col1... order by col2... desc/asc)
如上图所示,rank 会对相同数值,输出相同的序号,而且下一个序号不间断;
dense_rank 会对相同数值,输出相同的序号,但下一个序号,间断
row_number 会对所有数值输出不同的序号,序号唯一连续;
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值, 与LAG相反
-- 组内排序后,向后或向前偏移-- 如果省略掉第三个参数,默认为NULL,否则补上。
-- 组内排序后,向后或向前偏移-- 如果省略掉第三个参数,默认为NULL,否则补上。
first_value: 取分组内排序后,截止到当前行,第一个值
last_value: 取分组内排序后,截止到当前行,最后一个值

1 分析函数:用于等级、百分点、n分片等
Ntile 是Hive很强大的一个分析函数。
可以看成是:它把有序的数据集合 平均分配 到 指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。语法是:
ntile (num) over ([partition_clause] order_by_clause) as your_bucket_num
然后可以根据桶号,选取前或后 n分之几的数据。
例子:
给了用户和每个用户对应的消费信息表, 计算花费前50%的用户的平均消费;-- 把用户和消费表,按消费下降顺序平均分成2份 drop table if exists test_by_payment_ntile; create table test_by_payment_ntile as select nick, payment , NTILE(2) OVER(ORDER BY payment desc) AS rn from test_nick_payment; -- 分别对每一份计算平均值,就可以得到消费靠前50%和后50%的平均消费 select 'avg_payment' as inf, t1.avg_payment_up_50 as avg_payment_up_50, t2.avg_payment_down_50 as avg_payment_down_50 from (select avg(payment) as avg_payment_up_50 from test_by_payment_ntile where rn=1 )t1 join (select avg(payment) as avg_payment_down_50 from test_by_payment_ntile where rn=2 )t2 on (t1.dp_id=t2.dp_id);
Rank,Dense_Rank, Row_Number
SQL很熟悉的3个组内排序函数了。语法一样:R() over (partion by col1... order by col2... desc/asc)
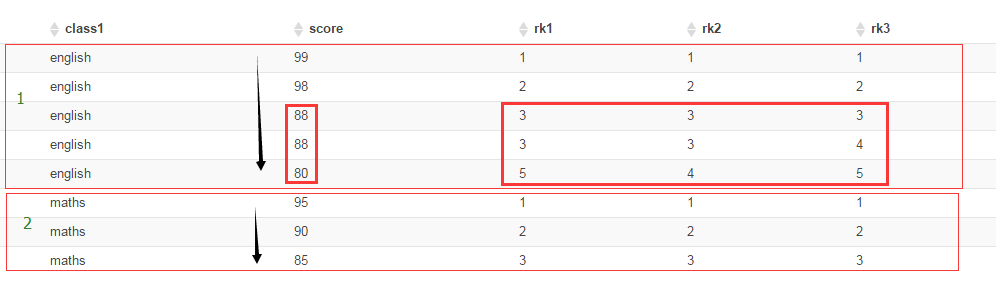
select class1, score, rank() over(partition by class1 order by score desc) rk1, dense_rank() over(partition by class1 order by score desc) rk2, row_number() over(partition by class1 order by score desc) rk3 from zyy_test1;
如上图所示,rank 会对相同数值,输出相同的序号,而且下一个序号不间断;
dense_rank 会对相同数值,输出相同的序号,但下一个序号,间断
row_number 会对所有数值输出不同的序号,序号唯一连续;
2. 窗口函数 Lag, Lead, First_value,Last_value
Lag, Lead
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值, 与LAG相反
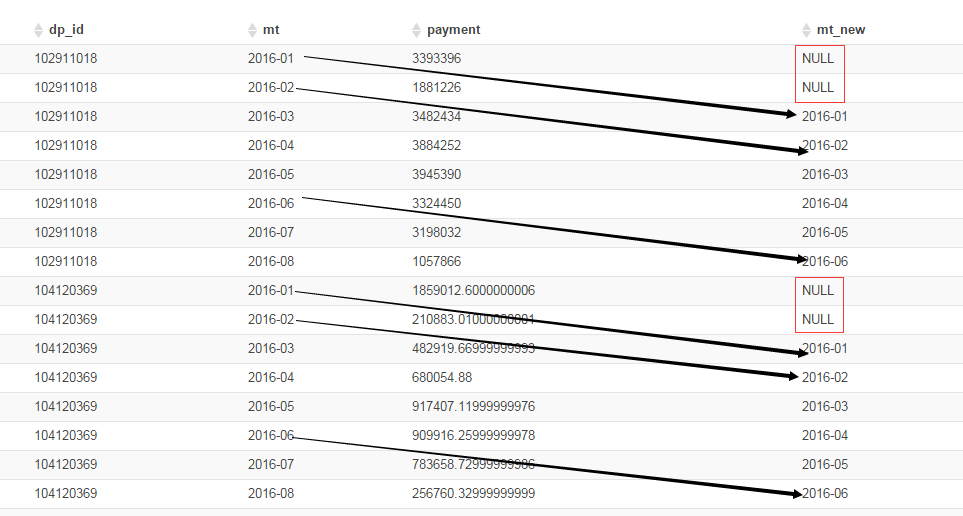
-- 组内排序后,向后或向前偏移-- 如果省略掉第三个参数,默认为NULL,否则补上。
select dp_id, mt, payment, LAG(mt,2) over(partition by dp_id order by mt) mt_new from test2;
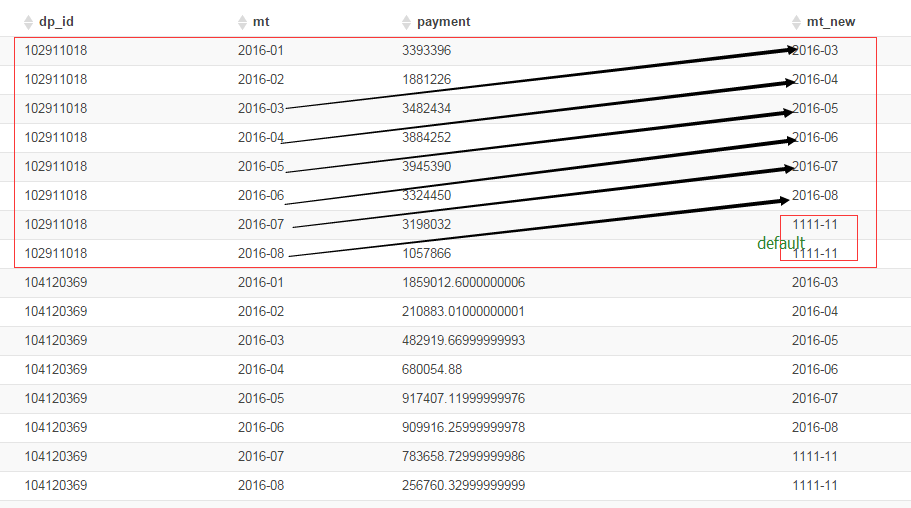
-- 组内排序后,向后或向前偏移-- 如果省略掉第三个参数,默认为NULL,否则补上。
select dp_id, mt, payment, LEAD(mt,2,'1111-11') over(partition by dp_id order by mt) mt_new from test2;
FIRST_VALUE, LAST_VALUE
first_value: 取分组内排序后,截止到当前行,第一个值last_value: 取分组内排序后,截止到当前行,最后一个值
-- FIRST_VALUE 获得组内当前行往前的首个值 -- LAST_VALUE 获得组内当前行往前的最后一个值 -- FIRST_VALUE(DESC) 获得组内全局的最后一个值 select dp_id, mt, payment, FIRST_VALUE(payment) over(partition by dp_id order by mt) payment_g_first, LAST_VALUE(payment) over(partition by dp_id order by mt) payment_g_last, FIRST_VALUE(payment) over(partition by dp_id order by mt desc) payment_g_last_global from test2 ORDER BY dp_id,mt;

相关文章推荐
- 函数分类,HIVE CLI命令,简单函数,聚合函数,集合函数,特殊函数(窗口函数,分析函数,混合函数,UDTF),常用函数Demo
- Hive常用函数大全(二)(窗口函数、分析函数、增强group)
- Hive 窗口函数、分析函数
- hive内置函数详解(分析函数、窗口函数)
- Hive 窗口函数、分析函数
- hive内置函数详解(分析函数、窗口函数)
- Hive 窗口函数、分析函数
- [Hive]窗口函数与分析函数
- Hive SQL 一些窗口函数,分析函数的使用小例子
- Hive 窗口函数、分析函数
- Hive分析窗口函数(二) NTILE,ROW_NUMBER,RANK,DENSE_RANK
- Hive分析函数之LAG、LEAD、FIRST_VALUE、LAST_VALUE学习
- Oracle 分析函数/窗口函数
- Hive分析窗口函数(三) CUME_DIST,PERCENT_RANK
- Hive分析窗口函数(五) GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
- Hive分析窗口函数(三) CUME_DIST,PERCENT_RANK
- Hive窗口和分析函数[RANK()、DENSE_RANK()、ROW_NUMBER()]
- hive中使用自定义函数(UDF)实现分析函数row_number的功能
- Hive UDF实现分析函数row_number
- Hive分析窗口函数(四) LAG,LEAD,FIRST_VALUE,LAST_VALUE