Spark中groupBy groupByKey reduceByKey的区别
2018-01-26 17:52
591 查看
groupBy
和SQL中groupby一样,只是后面必须结合聚合函数使用才可以。
例如:
groupByKey
对Key-Value形式的RDD的操作。
例如(取自link):
reduceByKey
与groupByKey功能一样,只是实现不一样。本函数会先在每个分区聚合然后再进行总的统计,如图:
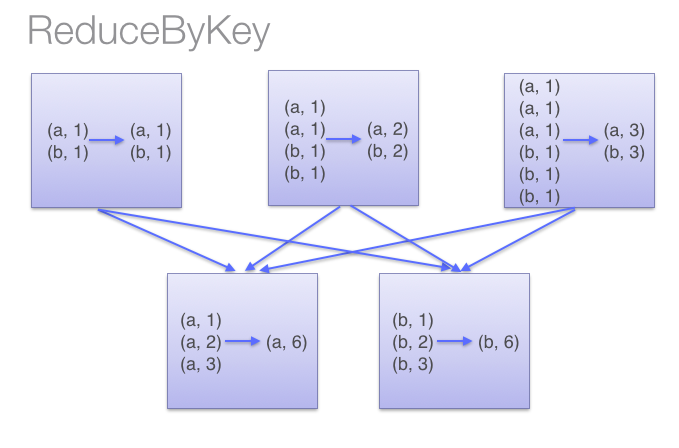
而groupByKey则是
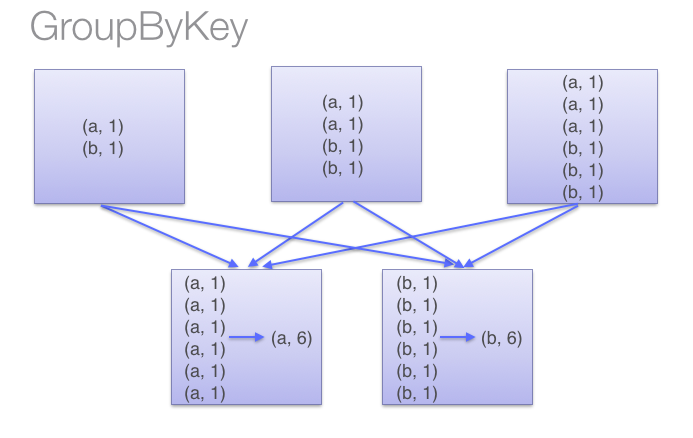
因此,本函数比groupByKey节省了传播的开销,尽量少用groupByKey
参考
https://www.iteblog.com/archives/1357.html
http://blog.csdn.net/guotong1988/article/details/50556871
http://blog.cheyo.net/178.html
和SQL中groupby一样,只是后面必须结合聚合函数使用才可以。
例如:
hour.filter($"version".isin(version: _*)).groupBy($"version").agg(countDistinct($"id"), count($"id")).show()
groupByKey
对Key-Value形式的RDD的操作。
例如(取自link):
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "spider", "eagle"), 2)
val b = a.keyBy(_.length)//给value加上key,key为对应string的长度
b.groupByKey.collect
//结果 Array((4,ArrayBuffer(lion)), (6,ArrayBuffer(spider)), (3,ArrayBuffer(dog, cat)), (5,ArrayBuffer(tiger, eagle)))reduceByKey
与groupByKey功能一样,只是实现不一样。本函数会先在每个分区聚合然后再进行总的统计,如图:
而groupByKey则是
因此,本函数比groupByKey节省了传播的开销,尽量少用groupByKey
参考
https://www.iteblog.com/archives/1357.html
http://blog.csdn.net/guotong1988/article/details/50556871
http://blog.cheyo.net/178.html

相关文章推荐
- 【Spark系列2】reduceByKey和groupByKey区别与用法
- Spark groupByKey,reduceByKey,sortByKey算子的区别
- 【Spark系列2】reduceByKey和groupByKey区别与用法
- 【转载】Spark中:reduceByKey和groupByKey区别与用法
- 在Spark中关于groupByKey与reduceByKey的区别
- Spark中groupByKey与reduceByKey算子之间的区别
- Spark算子:RDD键值转换操作(3)–groupByKey、reduceByKey、reduceByKeyLocally
- groupByKey 和reduceByKey 的区别:
- spark新能优化之reduceBykey和groupBykey的使用
- Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、look
- Spark API编程动手实战-04-以在Spark 1.2版本实现对union、groupByKey、join、reduce、lookup等操作实践
- Spark API编程动手实战-04-以在Spark 1.2版本实现对union、groupByKey、join、reduce、lookup等操作实践
- Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、lookup(一)
- Spark算子:RDD键值转换操作(3)–groupBy、keyBy、groupByKey、reduceByKey、reduceByKeyLocally
- Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
- 大数据Spark “蘑菇云”行动第40课:Spark编程实战之aggregateByKey、reduceByKey、groupByKey、sortByKey深度解密
- reduceByKey和groupByKey区别与用法
- Spark中 groupBy() 与groupByKey()的区别
- sparkrdd自动转换能用pairfun(否则无法用reducebykey,groupbykey)
- 请教Spark 中 combinebyKey 和 reduceByKey的传入函数参数的区别?