Python 开发简单爬虫 - 基础框架
2018-01-26 16:34
495 查看
Python 开发简单爬虫 - 基础框架
1. 目标:开发轻量级爬虫(不包括需登陆的 和 Javascript异步加载的)不需要登陆的静态网页抓取
2. 内容:
2.1 爬虫简介
2.2 简单爬虫架构
2.3 URL管理器
2.4 网页下载器(urllib2)
2.5 网页解析器(BeautifulSoup)
2.6 完整实例:爬取百度百科Python词条相关的1000个页面数据
3. 爬虫简介:一段自动抓取互联网信息的程序
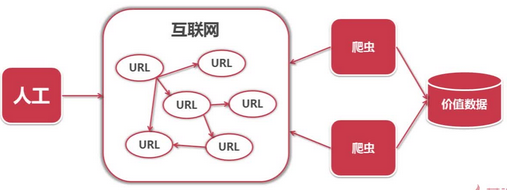
爬虫价值:互联网数据,为我所用。
4. 简单爬虫架构:
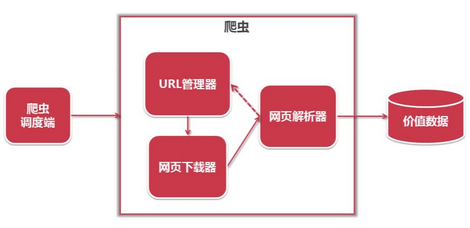
运行流程:

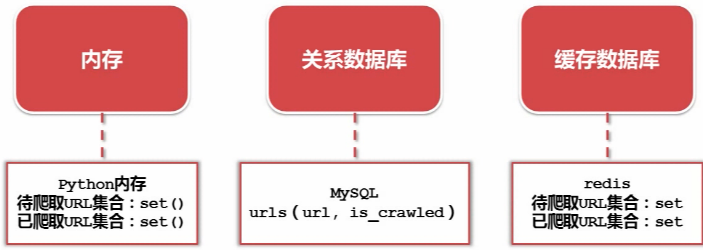
5. URL管理器:管理待抓取URL集合 和 已抓取URL集合
- 防止重复抓取、防止循环抓取
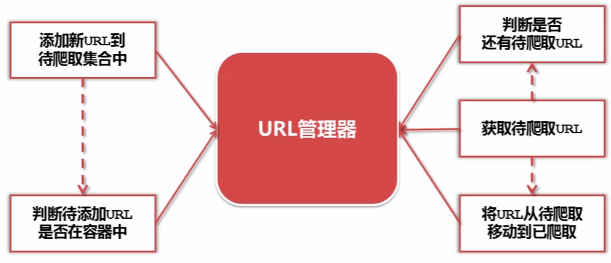
- 实现方式:
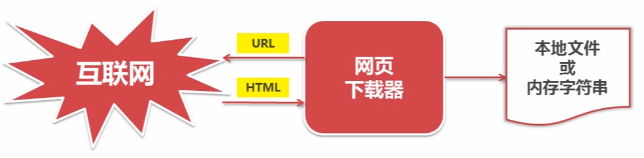
6. 网页下载器:将互联网URL对应的网页下载到本地的工具
- 分类:
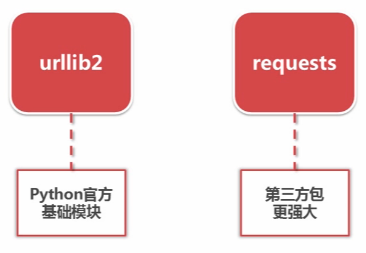
- urllib2 下载网页的方法:
1. 最简洁方法: url ===> urllib2.urlopen(url)

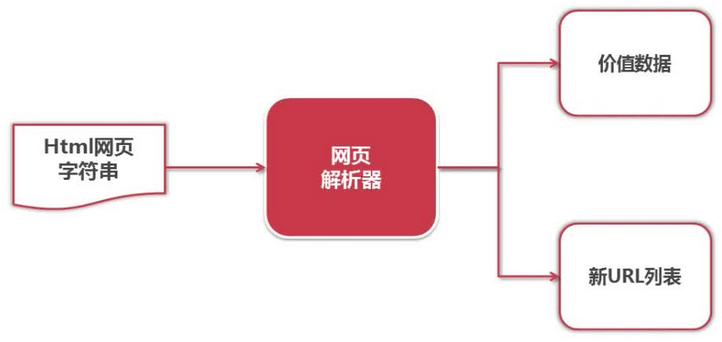
python 的网页解析器:
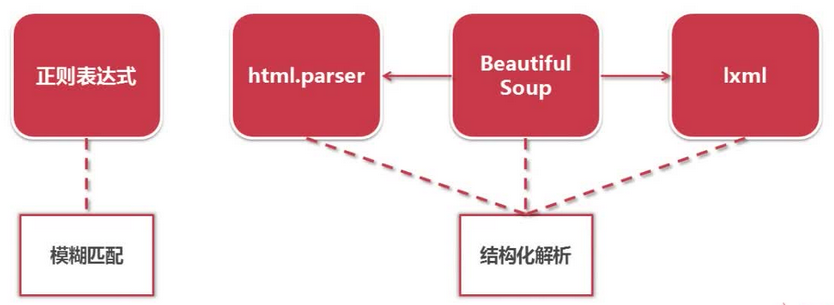
结构化解析 - DOM ( Document Object Model) 树:

9. 网页解析器 - Beautiful Soup
9.1 Beautiful Soup
- Python 第三方库,用于从HTML或XML中提取数据
- 官网:http://www.crummy.com/software/BeautifulSoup
9.2 安装并测试 beautifulsoup4
- 安装:pip install beautifulsoup4
- 测试:import bs4
9.3 Beautiful Soup语法
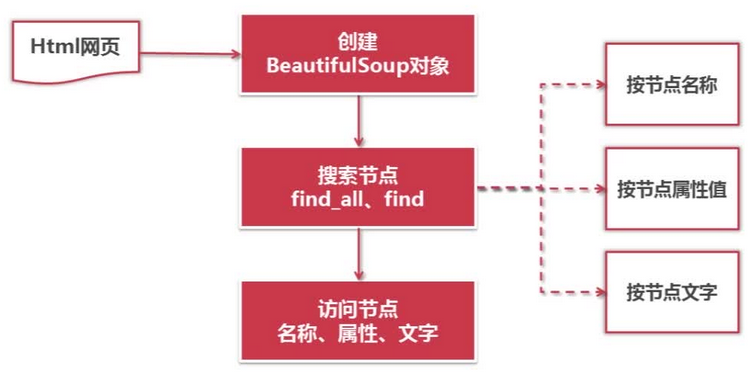

9.4 创建 BeautifulSoup 对象

相关文章推荐
- Python 开发简单爬虫 - 基础框架
- 基础爬虫框架及运行(选自范传辉Python爬虫开发与项目实战)
- Python爬虫基础(一)--简单的url请求
- Python开发简单爬虫
- Python开发简单爬虫(二)
- Python开发简单爬虫(笔记)
- python基础入门之简单爬虫编写
- 使用Python的Scrapy框架编写web爬虫的简单示例
- Python开发简单爬虫学习笔记(1)
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- Python的Scrapy爬虫框架简单学习笔记
- 零基础写python爬虫之使用Scrapy框架编写爬虫
- python基础学习-7(简单爬虫)
- Python开发简单爬虫学习笔记(2)
- Python爬虫开发(一):零基础入门
- 零基础写python爬虫之爬虫框架Scrapy安装配置
- Python爬虫-scrapy框架简单应用
- Python爬虫开发(一):零基础入门
- Python爬虫基础(一)--简单的url请求
- Python开发简单爬虫