Python scrapy使用入门,爬取拉勾网上万条职位信息(上)
2018-01-24 17:51
711 查看
使用python实现爬虫的方式很多,典型的有urllib配合BeatifulSoup,代码也很简单,不过威力有限只适合入门尝鲜,想要真正收集大量有用数据拿来做数据分析就略感力不从心,这时不得不提scrapy了,一个专业的爬虫框架。看了网上很多的入门教程,很多都难以跑通,毕竟链接变化很快,如果不系统了解其原理,很难更正回来。所以本篇还是从一个成功的案例记录下,方便爱学习的你我他。
(一)首先要确定安装好了相应环境
安装scrapy,建议命令安装,pip install scrapy
确定环境安装好了,随意新建一个文件夹,按shift和鼠标右键,在当前位置打开命令行,输入scrapy,如果有帮助提示,则说明环境安装成功,如图:

(二)环境安装好了之后,新建工程:
我在D盘下spider目录里新建了个文件夹作为我们的新工程,取名Lagou,当然名字随便起,然后进去,在当前位置打开命令行后,输入:
这时会生成一堆文件,先不管都是干什么的,已创建了名为First的爬虫工程。
根据命令提示,cd进到First文件夹,继续输入:
这句命令会帮助我们生成需要的写代码的文件,也是爬虫文件,我们主要在这个里面写代码,这句命令生成了一个爬虫,名为second。后面的lagou是需要爬取的域名信息,可以暂时随意填,待会进入代码还要修改,不用纠结。
(三)打开IDE,我用的是pyCharm,不用多说,界面高端大气上档次,直接点击左上角文件->open->选择工程目录lagou下的First文件夹,点确定,即可将工程导入到IDE。
(四)先修改Item.py文件,我们需要在这个文件里定义我们需要爬取的字段:
这里我们定义了两个字段,工作类型jobClass,和该类型的超链接jobUrl
然后进入spider目录下的second.py,开始写我们的代码之前,我们需要先分析网页实际情况,看下我们感兴趣的字段在什么位置,打开Google浏览器,输入拉钩的网址:
http://www.lagou.com
按F12打开开发者模式,点击左上角的鼠标箭头,可以跟踪页面中的元素。

然后找到字段所在位置,方法吧,就是一个个展开那些个标签,

可以看到到了dd标签,我们需要的东西都出现了。
代码如何写呢,这时我们要通过response的xpath方法中的表达式来获取到这个位置,
完整代码如下:
至此为止,我们的爬虫已具雏形了。可以马上运行感受一下。scrapy的爬虫应用运行方式不同于python。需要在命令行里执行如下代码:
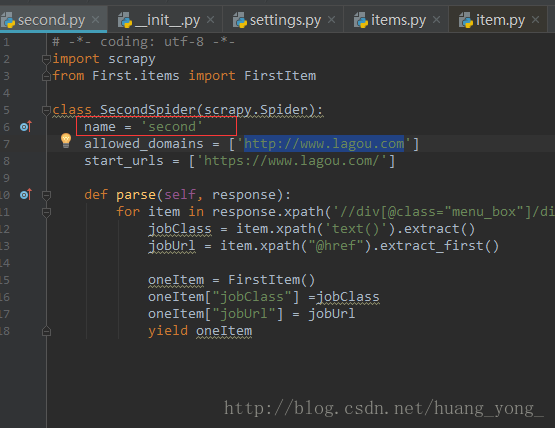
需要注意的是,这里的second是我们定义的爬虫的名字,在代码中如图位置:
刚开始我按照别人的例子敲,总是遇到找不到工程的错误,后来发现这个地方很容易忽略。切记切记。
可以看到,已经显示出了爬取的结果:
这时会在当前目录下生成一个文件,打开看到我们的数据都导出来了,可是,很明显编码未处理,以至于都是英文字符。

通过阅读源码知道,在scrapy.exporters 的 JsonLinesItemExporter类中,对数据进行了编码。所以我们可以在spiders文件夹的同级目录下创建一个文件夹,名字随意,比如我新建了recode,在该文件夹中创建一个init.py文件,在里面写一个类继承JsonLinesItemExporter,并且设置不要任何编码,如果你是pyCharm,会在新建python package时自动生成init.py文件,在文件中添加如下代码:
再次运行刚才的命令导出文件:

好啦,任务完成,下课休息十分钟。十分钟后继续开始下篇
参考文章:http://blog.csdn.net/dangsh_/article/details/78587729
(一)首先要确定安装好了相应环境
安装scrapy,建议命令安装,pip install scrapy
确定环境安装好了,随意新建一个文件夹,按shift和鼠标右键,在当前位置打开命令行,输入scrapy,如果有帮助提示,则说明环境安装成功,如图:
(二)环境安装好了之后,新建工程:
我在D盘下spider目录里新建了个文件夹作为我们的新工程,取名Lagou,当然名字随便起,然后进去,在当前位置打开命令行后,输入:
scrapy startproject First
这时会生成一堆文件,先不管都是干什么的,已创建了名为First的爬虫工程。
根据命令提示,cd进到First文件夹,继续输入:
scrapy genspider second lagou
这句命令会帮助我们生成需要的写代码的文件,也是爬虫文件,我们主要在这个里面写代码,这句命令生成了一个爬虫,名为second。后面的lagou是需要爬取的域名信息,可以暂时随意填,待会进入代码还要修改,不用纠结。
(三)打开IDE,我用的是pyCharm,不用多说,界面高端大气上档次,直接点击左上角文件->open->选择工程目录lagou下的First文件夹,点确定,即可将工程导入到IDE。
(四)先修改Item.py文件,我们需要在这个文件里定义我们需要爬取的字段:
import scrapy class FirstItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() jobClass = scrapy.Field() jobUrl = scrapy.Field()
这里我们定义了两个字段,工作类型jobClass,和该类型的超链接jobUrl
然后进入spider目录下的second.py,开始写我们的代码之前,我们需要先分析网页实际情况,看下我们感兴趣的字段在什么位置,打开Google浏览器,输入拉钩的网址:
http://www.lagou.com
按F12打开开发者模式,点击左上角的鼠标箭头,可以跟踪页面中的元素。
然后找到字段所在位置,方法吧,就是一个个展开那些个标签,
可以看到到了dd标签,我们需要的东西都出现了。
代码如何写呢,这时我们要通过response的xpath方法中的表达式来获取到这个位置,
for item in response.xpath(‘//div[@class=”menu_box”]/div/dl/dd/a’):
完整代码如下:
# -*- coding: utf-8 -*-
import scrapy
from First.items import FirstItem
class SecondSpider(scrapy.Spider):
name = 'second'
allowed_domains = ['http://www.lagou.com']
start_urls = ['https://www.lagou.com/']
def parse(self, response):
for item in response.xpath('//div[@class="menu_box"]/div/dl/dd/a'):
jobClass = item.xpath('text()').extract()#提取文本内容
jobUrl = item.xpath("@href").extract_first()#提取链接内容
oneItem = FirstItem()#实例化一个item对象,将获取到的数据存入
oneItem["jobClass"] =jobClass
oneItem["jobUrl"] = jobUrl
yield oneItem#输出item至此为止,我们的爬虫已具雏形了。可以马上运行感受一下。scrapy的爬虫应用运行方式不同于python。需要在命令行里执行如下代码:
scrapy crawl second
需要注意的是,这里的second是我们定义的爬虫的名字,在代码中如图位置:
刚开始我按照别人的例子敲,总是遇到找不到工程的错误,后来发现这个地方很容易忽略。切记切记。
当然还有一种方式,可以使其在IDE中运行,控制台输出结果。
在工程顶级目录下新建一个python文件名字随意,比如runmyProgram.py 输入如下命令: from scrapy.cmdline import execute execute(['scrapy','crawl','second']) 然后右键,运行此文件即可。
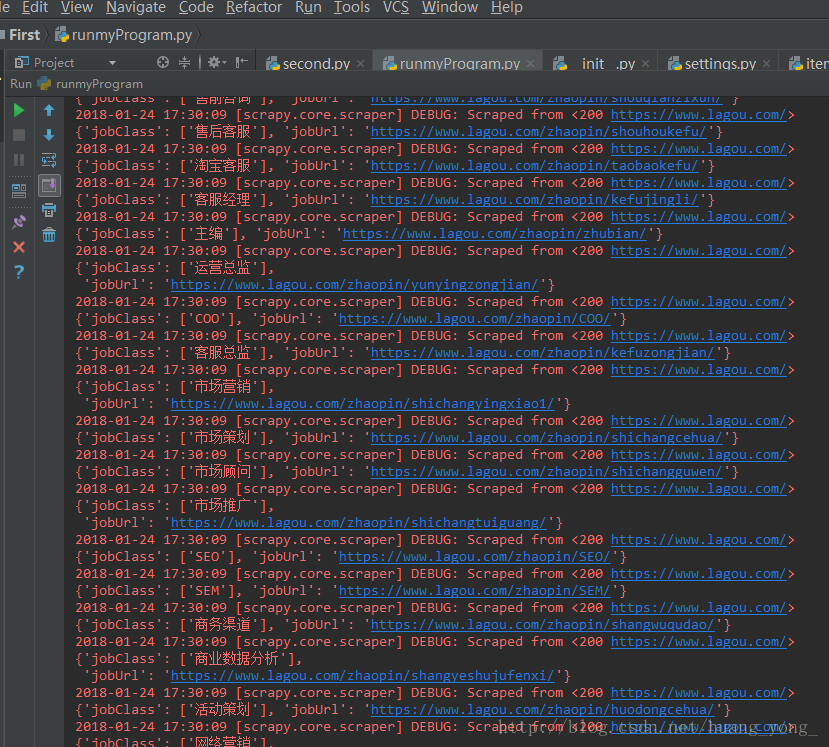
可以看到,已经显示出了爬取的结果:
第一部分告一段落,现在开始第二部分。
回到刚刚的命令行窗口,再输入命令将其导出到文件(IDE里修改runmyProgram.py中的命令亦可):scrapy crawl second -o shujv.json
这时会在当前目录下生成一个文件,打开看到我们的数据都导出来了,可是,很明显编码未处理,以至于都是英文字符。
通过阅读源码知道,在scrapy.exporters 的 JsonLinesItemExporter类中,对数据进行了编码。所以我们可以在spiders文件夹的同级目录下创建一个文件夹,名字随意,比如我新建了recode,在该文件夹中创建一个init.py文件,在里面写一个类继承JsonLinesItemExporter,并且设置不要任何编码,如果你是pyCharm,会在新建python package时自动生成init.py文件,在文件中添加如下代码:
from scrapy.exporters import JsonLinesItemExporter
class recodes(JsonLinesItemExporter):
def __init__(self, file, **kwargs):
super(recodes,self).__init__(file, ensure_ascii = None)
然后打开settings.py文件,在其中添加配置:
FEED_EXPORTERS_BASE = {
'json': 'First.recode.recodes',#这个位置注意是文件索引,根据你实际情况修改。
'jsonlines' : 'scrapy.contrib.exporter.JsonLinesItemExporter'再次运行刚才的命令导出文件:
好啦,任务完成,下课休息十分钟。十分钟后继续开始下篇
参考文章:http://blog.csdn.net/dangsh_/article/details/78587729

相关文章推荐
- [置顶] python3 scrapy 入门级爬虫 爬取数万条拉勾网职位信息
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息
- #python学习笔记#使用python爬取拉勾网职位信息(二):爬取数据
- 使用scrapy爬取拉勾网职位信息
- 【python爬虫02】使用Scrapy框架爬取拉勾网招聘信息
- 【python日常一】使用python抓取拉勾网职位信息并做简单统计分析
- Python使用scrapy抓取网站sitemap信息的方法
- 使用nodejs爬取拉勾苏州和上海的.NET职位信息
- [爬虫入门]Python中使用scrapy框架实现图片爬取
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
- 使用python scrapy爬取知乎提问信息
- [Python]第三方库-Scrapy入门使用
- Scrapy框架学习 - 爬取Boss直聘网Python职位信息
- Python3网络爬虫:Scrapy入门之使用ImagesPipline下载图片
- Python Scrapy爬虫入门 - 使用Crontab实现Scrapy爬虫的定时执行
- Python使用Scrapy保存控制台信息到文本解析
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息
- Python 小技巧:使用 scrapy.selector 从 XML 中提取信息
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息
- #python学习笔记#使用python爬取拉勾网职位信息(一):环境配置及库安装