拉链法解决哈希冲突的方式和几种常见的散列函数
2018-01-24 16:10
495 查看
本文探讨拉链表解决哈希冲突的方式和几种常见的散列函数。
首先,什么是散列表?
对于一个数组,我们在O(1)时间复杂度完成可以完成其索引的查找,现在我们想要存储一个key value的键值对,我们可以根据key生成一个数组的索引,然后在索引存储这个key value键值对。我们把根据key生成索引这个函数叫做散列函数。显而易见,不同的key有可能产生相同的索引,这就叫做哈希碰撞,也叫哈希冲突。一个优秀的哈希函数应该尽可能避免哈希碰撞。
而对于本文就将介绍如何拉链法解决哈希冲突的方法,以及常用的哈希函数。
拉链法
这种方
4000
法的关键是把同一个散列槽(在我们这里就是数组的每一个槽)中的所有元素放到一个链表中。
我们拿到一个索引首先计算其在散列函数作用下映射出来的索引,如果索引没有元素,直接插入;如果有元素,但是key值和我们要插入的数据不一样,我们就把key value键值对插入链表头;如果存在和我们要插入数据相同key的键值对,我们就把value进行更换。
我们画一张图来表示拉链法put时候发生的情况:
1、没有发生哈希碰撞的时候

2、发生哈希碰撞但是key值不同

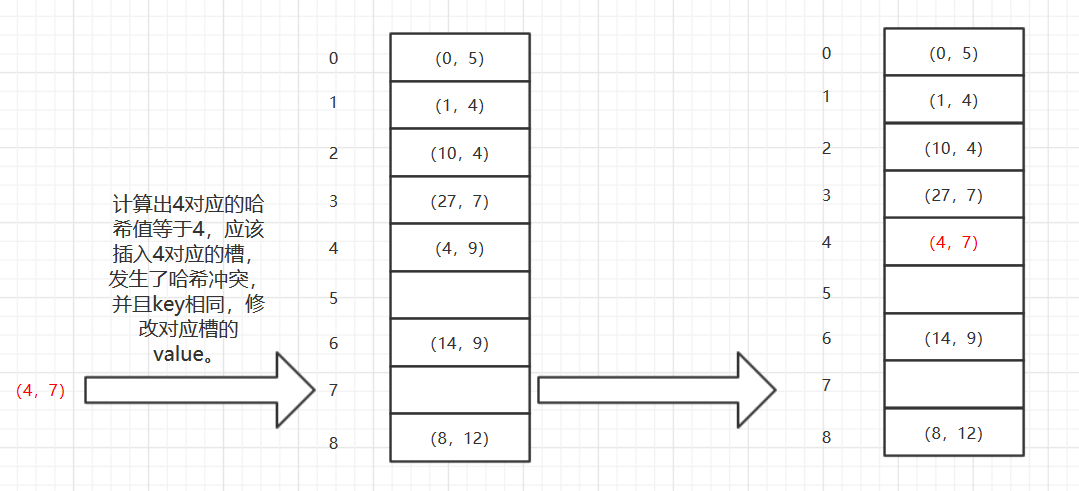
3、发生哈希碰撞并且key值相同
下面我们使用一个不会动态开辟新空间的静态哈希表来做一个简单示范,使用的是Java代码:
实际上实现起来也很简单,但是请注意一些细节:
①、首先对于一个散列表,这里我们可以自己传入一个哈希函数来完成我们的映射,但是Java不提供函数指针怎么办?《Effective Java》一书说到过这个问题,我们可以使用一个宿主类来包含这个我们想要传递的方法,通过传递宿主类来起来传递方法的作用,也就是我们代码中的接口HashFunctionHost的实现类。
②、在遍历数组中的链表的时候,我们不要使用for循环加上链表的get()方法,而是使用Iterator。看底层源码我们就可以发现get()方法实际上会从头遍历一遍链表,直到找到对应元素,也就是说我们会做很多的无用遍历,这是我们不能接受的。相反Iterator就不是这样,对于访问Iterator下一个元素的复杂度是O(1)。
③、我们在put的时候有三种情况,分别是没有哈希冲突,直接插入;有哈希冲突,但是没有相同的key,插入到链表头部;有哈希冲突,而且存在相同key,我们就需要修改那个key对应的value。
④、在比较key的时候使用equals而不是==,这个不用多说了,equals比较的应该是值,==比较的是内存地址。如果我们想要在key值相等的时候就对value做出替换,那么我们可能要用的是equals而不能用==,并且要对存入散列表的对象的equals方法进行重写。
散列函数
上面的哈希表实现过程我们就看到了我们实现了一个默认的散列函数,我们下面来讨论其他的散列函数。
首先我们需要思考一个好的散列函数需要有的特点:每个关键字都尽量等可能地散列到m个槽中地任何一个,并且和其他关键的散列无关。
下面我们就来介绍常用的几种散列函数。因为我们使用的是Java,因此我们先声明一个接口,表示散列函数的宿主类需要实现这个接口:
1、除法散列法
这种方法是我们上面哈希表的默认哈希函数,也是jdk中HashMap和HashTable的哈希函数。
现在我们有一个关键字k和散列槽的个数m,我们可以通过取k除以m的余数来将关键字映射到m个槽,用数学公式表示就是:
h(k) = k mod m
这个方法运算很快,比较只是以此模运算。然而在m的选择上有一些技巧,我们应该选择不太靠近2的整数次幂的素数m,这个时候哈希碰撞会很少。我们使用Java代码来实现这种散列函数:
由于一些对象的hashCode可能会出现负值,所以我加上了一个绝对值。
2、乘法散列法
乘法散列函数的计算分为几个步骤,用关键字k乘以一个常数A,提取kA的小数部分,然后用槽的个数m乘以这个值,最后向下取整。
这种散列函数对m选择不是很关键,但是常数A对其影响较大,一般我们认为黄金分割率(美妙的大自然),也就是(√5 - 1)/2,大约是0.6180339887是一个很理想的值。
下面是我的实现代码:
3、全域散列法
我觉得这种算法更像是一种散列函数的综合。当一个使用者恶意地把n个关键字放入一个槽中的时候,复杂度会变成O(n),这不是我们想看到的,因此衍生出了这种思路。
我们随机选择散列函数,使得关键字k和关键字l不相等的时候,发生哈希碰撞的概率不大于1/m,用户不能控制关键字与槽的映射,从而使得平均性能很好。毕竟我都random了,你如何确定关键字k与槽的映射。
这更像是一种散列函数的综合的思想,我就不给出代码实现了。
以上,有问题或者对我观点不认同欢迎评论。
首先,什么是散列表?
对于一个数组,我们在O(1)时间复杂度完成可以完成其索引的查找,现在我们想要存储一个key value的键值对,我们可以根据key生成一个数组的索引,然后在索引存储这个key value键值对。我们把根据key生成索引这个函数叫做散列函数。显而易见,不同的key有可能产生相同的索引,这就叫做哈希碰撞,也叫哈希冲突。一个优秀的哈希函数应该尽可能避免哈希碰撞。
而对于本文就将介绍如何拉链法解决哈希冲突的方法,以及常用的哈希函数。
拉链法
这种方
4000
法的关键是把同一个散列槽(在我们这里就是数组的每一个槽)中的所有元素放到一个链表中。
我们拿到一个索引首先计算其在散列函数作用下映射出来的索引,如果索引没有元素,直接插入;如果有元素,但是key值和我们要插入的数据不一样,我们就把key value键值对插入链表头;如果存在和我们要插入数据相同key的键值对,我们就把value进行更换。
我们画一张图来表示拉链法put时候发生的情况:
1、没有发生哈希碰撞的时候
2、发生哈希碰撞但是key值不同
3、发生哈希碰撞并且key值相同
下面我们使用一个不会动态开辟新空间的静态哈希表来做一个简单示范,使用的是Java代码:
import java.util.Iterator;
import java.util.LinkedList;
interface HashFunctionHost {
//接口约定根据index确定的hash值
public <K,V> double hashFunction(HashTable<K,V> hashTable,K x);
}
public class HashTable<K, V> {
public static class Entry<K, V>{
private K key;
private V value;
public Entry(K key, V value){
this.key = key;
this.value = value;
}
public K getKey(){
return key;
}
public V getValue(){
return value;
}
}
private LinkedList<Entry<K,V>>[] elements;
private HashFunctionHost hashFunctionHost;
private int capacity;
public static final int DEFAULT_SIZE = 10;
public static final HashFunctionHost DEFAULT_HASH_FUNCTION_HOST = new DivisionHashFunctionHost();
@SuppressWarnings("unchecked")
public HashTable(int size, HashFunctionHost hashFunctionHost){
elements = new LinkedList[size];
for(int i = 0 ; i < size ; i++)
elements[i] = new LinkedList<Entry<K,V>>();
this.hashFunctionHost = hashFunctionHost;
capacity = 0;
}
public HashTable() {
this(DEFAULT_SIZE, DEFAULT_HASH_FUNCTION_HOST);
}
private Entry<K,V> getEntry(K key){
int index = (int) hashFunctionHost.hashFunction(this, key);
Iterator<Entry<K, V>> iterator = elements[index].iterator();
while(iterator.hasNext()){
//找到了重复的key则直接修改entry中key对应的value
Entry<K, V> temp = iterator.next();
if(key.equals(temp.getKey())){
return temp;
}
}
return null;
}
public void put(K key ,V value){
int index = (int) hashFunctionHost.hashFunction(this,key);
Entry<K, V> newEntry = new Entry<K,V>(key,value);
//没有哈希冲突
if(elements[index].size()==0){
elements[index].add(newEntry);
capacity++;
}
//发生了哈希碰撞则需要遍历链表判断k值是不是已经存在了
else{
Entry<K,V> entry = getEntry(key);
if(entry != null){
entry.value = value;
return;
}
//执行到这里说明没有发现重复的key 插在链表头部
elements[index].addFirst(newEntry);
}
}
public boolean delete(K key){
int index = (int) hashFunctionHost.hashFunction(this, key);
Iterator<Entry<K, V>> iterator = elements[index].iterator();
while(iterator.hasNext()){
Entry<K, V> entry = iterator.next();
if(entry.getKey()==key){
iterator.remove();
return true;
}
}
return false;
}
public V get(K key){
Entry<K, V> entry = getEntry(key);
if(entry == null)
return null;
return entry.getValue();
}
public int bucketNum(){
return elements.length;
}
public int size(){
return capacity;
}
}实际上实现起来也很简单,但是请注意一些细节:
①、首先对于一个散列表,这里我们可以自己传入一个哈希函数来完成我们的映射,但是Java不提供函数指针怎么办?《Effective Java》一书说到过这个问题,我们可以使用一个宿主类来包含这个我们想要传递的方法,通过传递宿主类来起来传递方法的作用,也就是我们代码中的接口HashFunctionHost的实现类。
②、在遍历数组中的链表的时候,我们不要使用for循环加上链表的get()方法,而是使用Iterator。看底层源码我们就可以发现get()方法实际上会从头遍历一遍链表,直到找到对应元素,也就是说我们会做很多的无用遍历,这是我们不能接受的。相反Iterator就不是这样,对于访问Iterator下一个元素的复杂度是O(1)。
③、我们在put的时候有三种情况,分别是没有哈希冲突,直接插入;有哈希冲突,但是没有相同的key,插入到链表头部;有哈希冲突,而且存在相同key,我们就需要修改那个key对应的value。
④、在比较key的时候使用equals而不是==,这个不用多说了,equals比较的应该是值,==比较的是内存地址。如果我们想要在key值相等的时候就对value做出替换,那么我们可能要用的是equals而不能用==,并且要对存入散列表的对象的equals方法进行重写。
散列函数
上面的哈希表实现过程我们就看到了我们实现了一个默认的散列函数,我们下面来讨论其他的散列函数。
首先我们需要思考一个好的散列函数需要有的特点:每个关键字都尽量等可能地散列到m个槽中地任何一个,并且和其他关键的散列无关。
下面我们就来介绍常用的几种散列函数。因为我们使用的是Java,因此我们先声明一个接口,表示散列函数的宿主类需要实现这个接口:
interface HashFunctionHost {
//接口约定根据index确定的hash值
public <K,V> double hashFunction(HashTable<K,V> hashTable,K x);
}1、除法散列法
这种方法是我们上面哈希表的默认哈希函数,也是jdk中HashMap和HashTable的哈希函数。
现在我们有一个关键字k和散列槽的个数m,我们可以通过取k除以m的余数来将关键字映射到m个槽,用数学公式表示就是:
h(k) = k mod m
这个方法运算很快,比较只是以此模运算。然而在m的选择上有一些技巧,我们应该选择不太靠近2的整数次幂的素数m,这个时候哈希碰撞会很少。我们使用Java代码来实现这种散列函数:
public class DivisionHashFunctionHost implements HashFunctionHost {
@Override
public <K,V> double hashFunction(HashTable<K,V> hashTable, K x) {
return Math.abs(x.hashCode())%hashTable.bucketNum();
}
}由于一些对象的hashCode可能会出现负值,所以我加上了一个绝对值。
2、乘法散列法
乘法散列函数的计算分为几个步骤,用关键字k乘以一个常数A,提取kA的小数部分,然后用槽的个数m乘以这个值,最后向下取整。
这种散列函数对m选择不是很关键,但是常数A对其影响较大,一般我们认为黄金分割率(美妙的大自然),也就是(√5 - 1)/2,大约是0.6180339887是一个很理想的值。
下面是我的实现代码:
public class MultiplicationHashFunctionHost implements HashFunctionHost {
private double constant;
public static final double DEFAULT_CONSTANT = 0.6180339887;
public MultiplicationHashFunctionHost(double constant) {
if(constant<=0 || constant>=1)
throw new IllegalArgumentException("非法参数constant:没有位于(0,1)区间");
this.constant = constant;
}
public MultiplicationHashFunctionHost() {
this(DEFAULT_CONSTANT);
}
@Override
public <K, V> double hashFunction(HashTable<K, V> hashTable, K x) {
return (int)((constant*x.hashCode()-(int)(constant*x.hashCode()))*hashTable.size());
}
}3、全域散列法
我觉得这种算法更像是一种散列函数的综合。当一个使用者恶意地把n个关键字放入一个槽中的时候,复杂度会变成O(n),这不是我们想看到的,因此衍生出了这种思路。
我们随机选择散列函数,使得关键字k和关键字l不相等的时候,发生哈希碰撞的概率不大于1/m,用户不能控制关键字与槽的映射,从而使得平均性能很好。毕竟我都random了,你如何确定关键字k与槽的映射。
这更像是一种散列函数的综合的思想,我就不给出代码实现了。
以上,有问题或者对我观点不认同欢迎评论。

相关文章推荐
- maven web项目的几种部署方式和常见的出错方式的解决
- 解决哈希冲突的几种方法
- 有没有人告诉我 如果使用GIT时,两个人同时修改了同一文件 这种冲突一般有哪几种解决方式?
- 常见哈希冲突解决
- 常见哈希冲突解决办法:
- DDOS几种常见攻击方式的原理及解决办法
- 有没有人告诉我 如果使用GIT时,两个人同时修改了同一文件 这种冲突一般有哪几种解决方式?
- WEB网站常见受攻击方式及解决办法
- 求项目中遇到的jquery 和 prototype 冲突解决方式??在线等待·····
- 常见的几种 CSS 水平垂直居中解决办法
- [Android开发常见问题-7] 多线程开发的几种方式和子线程操作UI线程控件的问题
- 如何解决哈希冲突
- PHP常见的几种攻击方式
- iOS开发中几种常见的存储方式
- 解决哈希(HASH)冲突的主要方法
- WEB网站常见受攻击方式及解决办法
- 前端加密的几种常见方式
- java上传文件常见几种方式
- 前端布局常见IE6 bug的解决方法,清除浮动的几种方法以及各自的优缺点