RCNN,SPP-NET,FAST_RCNN,FASTER-RCNN结构及训练方法总结
2018-01-24 14:45
351 查看
To be done:
1,Fig.1 需要补充图片说明
2, SVD 相关
3,roi 到 feature map 的映射该怎样确定?即 feature map 上的一个点对应的是 原图中的一块区域。
4,faster-rcnn部分总结有待完善。
通常做 detection 的流程是:
1,确定 ROI(即很多粗略的 bounding-boxes)
2,对每个 ROI 进行分类
3,利用每个 ROI 所属类别所对应的 bounding-box regressor 对相应 ROI 的区域进行微调。
4,non-maximum suppression 决定最终的 bounding-box 类别
所以在这个过程中我们就需要:
1,产生 roi区域
2,训练一个 classifier
3,训练一个 class-specific bounding-box regressor来对roi区域进行微调
RCNN,SPP-NET,FAST-RCNN,FASTER-RCNN都是基于以上方法一步一步地改进:
对于RCNN而言,
1,使用selective search作为产生roi的算法
2,引入了CNN+SVM作为分类器,
起初选择的是pre-trained CNN(没有fine-tune) + SVM其中训练的正样本仅仅由groud-truth区域构成,负样本由iou小于0.3的bounding-box区域构成,后来想到fine-tune pre-trained CNN,即fine-tune pre-trained CNN + SVM,训练样本的选择方法不变,实验发现结果变差了,所以最后又改变了训练CNN时选取样本的规则: roi区域中iou大于0.5即作为正样本,小于0.5的为负样本,每个mini-batch部分由采样得到的32个正样本,96个负样本组合而成。这个方法把训练的样本增加了三十倍。
由于实验发现直接选取CNN作为classfier是map会下降,作者推断是因为训练过程中没有强调精准定位,而是iou>0.5即可作为正样本,且因为负样本远远多于正样本,没有向SVM使用‘hard example mining’来训练。
3,bound-box regressor
将roi区域pool5层作为特征,建立预测的bounding-box与ground-truth之间的联系。因此训练是需要选择样本对,将bounding-box与对应的ground-truth区域iou大于0.6的作为训练对,如果一个bounding-box与多于1个ground-truth区域同时满足条件,则不选择该bounding-box.
优点:将 CNN based 的模型成功引入 detection 任务中
缺点:
1, 对于有一张 image 而言,每个 region proposal 都需要通过CNN,没有共享机制。
2,训练是分多个阶段进行的,即先训练好了一个 fine-tune 的CNN 模型。都利用这个 CNN 模型 在训练一个 SVM 和 bounding-box regressor。有可能不同阶段的最优并不能导致总的最优。
对于SPP-NET而言
1,使用selective search作为产生roi的算法
2,引入了CNN+SVM作为分类器,不在需要将一张图片的每个bounding-box区域都通过CNN,提升了训练和测试效率.
文章最开始的动机是为了解决 CNN 只能接受固定输入尺寸的问题,其原因是在于全连层的输入维数必须固定,不然影响的了全连层第一层的权值数量,因此文章使用在卷积层最后一层使用 ROI pooling 的方法使得全连层输入维数固定。进而联想到对于一张图片 region proposal 区域对应的卷积层其相应的区域与单独取出 region proposal 通过卷积后的结果大致相同(忽略zero padding 等一类因素。)又因为 roi pooling 可以对不同大小的卷积层区域提取相同大小的特征维数,所以可以通过对整张图片的一次 forward,得到每个 proposal 的特征。训练时只fine-tune了最后两个全连层,因此可以先对每个bounding-box提取一个固定维数的特征向量,用此特征向量作为训练数据来进行fine-tune最后的全连层
3,训练一个 class-specific bounding-box regressor来对roi区域进行微调
对于fast-rcnn而言
1,使用selective search作为产生roi的算法
2,3,结合roi-pooling,同时训练一个 classifier,class-specific bounding-box regressor,去除了svm
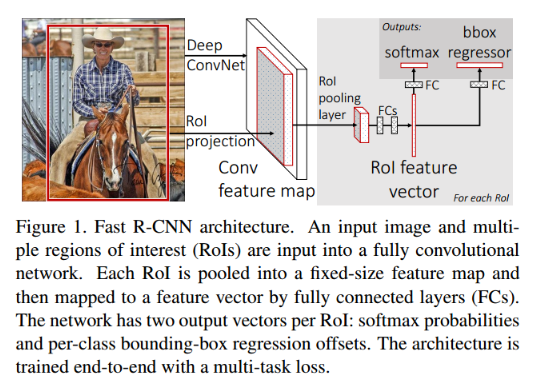
Fig.2
对于FASTER-RCNN
1,使用RPN产生proposal
训练数据为每个anchor,其中与ground-truth iou大于0.7或与ground-truth iou最大的anchor被选为正样本,iou小于0.3的为负样本。RPN损失项同时包含分类和位置损失
2,3,同FAST-RCNN
1,Fig.1 需要补充图片说明
2, SVD 相关
3,roi 到 feature map 的映射该怎样确定?即 feature map 上的一个点对应的是 原图中的一块区域。
4,faster-rcnn部分总结有待完善。
通常做 detection 的流程是:
1,确定 ROI(即很多粗略的 bounding-boxes)
2,对每个 ROI 进行分类
3,利用每个 ROI 所属类别所对应的 bounding-box regressor 对相应 ROI 的区域进行微调。
4,non-maximum suppression 决定最终的 bounding-box 类别
所以在这个过程中我们就需要:
1,产生 roi区域
2,训练一个 classifier
3,训练一个 class-specific bounding-box regressor来对roi区域进行微调
RCNN,SPP-NET,FAST-RCNN,FASTER-RCNN都是基于以上方法一步一步地改进:
对于RCNN而言,
1,使用selective search作为产生roi的算法
2,引入了CNN+SVM作为分类器,
起初选择的是pre-trained CNN(没有fine-tune) + SVM其中训练的正样本仅仅由groud-truth区域构成,负样本由iou小于0.3的bounding-box区域构成,后来想到fine-tune pre-trained CNN,即fine-tune pre-trained CNN + SVM,训练样本的选择方法不变,实验发现结果变差了,所以最后又改变了训练CNN时选取样本的规则: roi区域中iou大于0.5即作为正样本,小于0.5的为负样本,每个mini-batch部分由采样得到的32个正样本,96个负样本组合而成。这个方法把训练的样本增加了三十倍。
由于实验发现直接选取CNN作为classfier是map会下降,作者推断是因为训练过程中没有强调精准定位,而是iou>0.5即可作为正样本,且因为负样本远远多于正样本,没有向SVM使用‘hard example mining’来训练。
3,bound-box regressor
将roi区域pool5层作为特征,建立预测的bounding-box与ground-truth之间的联系。因此训练是需要选择样本对,将bounding-box与对应的ground-truth区域iou大于0.6的作为训练对,如果一个bounding-box与多于1个ground-truth区域同时满足条件,则不选择该bounding-box.
优点:将 CNN based 的模型成功引入 detection 任务中
缺点:
1, 对于有一张 image 而言,每个 region proposal 都需要通过CNN,没有共享机制。
2,训练是分多个阶段进行的,即先训练好了一个 fine-tune 的CNN 模型。都利用这个 CNN 模型 在训练一个 SVM 和 bounding-box regressor。有可能不同阶段的最优并不能导致总的最优。
对于SPP-NET而言
1,使用selective search作为产生roi的算法
2,引入了CNN+SVM作为分类器,不在需要将一张图片的每个bounding-box区域都通过CNN,提升了训练和测试效率.
文章最开始的动机是为了解决 CNN 只能接受固定输入尺寸的问题,其原因是在于全连层的输入维数必须固定,不然影响的了全连层第一层的权值数量,因此文章使用在卷积层最后一层使用 ROI pooling 的方法使得全连层输入维数固定。进而联想到对于一张图片 region proposal 区域对应的卷积层其相应的区域与单独取出 region proposal 通过卷积后的结果大致相同(忽略zero padding 等一类因素。)又因为 roi pooling 可以对不同大小的卷积层区域提取相同大小的特征维数,所以可以通过对整张图片的一次 forward,得到每个 proposal 的特征。训练时只fine-tune了最后两个全连层,因此可以先对每个bounding-box提取一个固定维数的特征向量,用此特征向量作为训练数据来进行fine-tune最后的全连层
3,训练一个 class-specific bounding-box regressor来对roi区域进行微调
对于fast-rcnn而言
1,使用selective search作为产生roi的算法
2,3,结合roi-pooling,同时训练一个 classifier,class-specific bounding-box regressor,去除了svm
Fig.2
对于FASTER-RCNN
1,使用RPN产生proposal
训练数据为每个anchor,其中与ground-truth iou大于0.7或与ground-truth iou最大的anchor被选为正样本,iou小于0.3的为负样本。RPN损失项同时包含分类和位置损失
2,3,同FAST-RCNN

相关文章推荐
- Detection物体检测及分类方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- 目标检测方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- 目标检测 RCNN, SPPNet, Fast RCNN, Faster RCNN 总结
- 目标检测方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- RCNN系列总结(RCNN,SPPNET,Fast RCNN,Faster RCNN)
- 目标检测方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- Detection物体检测及分类方法总结(RFCN/SSD/RCNN/FastRCNN/FasterRCNN/SPPNet/DPM/OverFeat/YOLO)
- Rcnn->Sppnet->Fast Rcnn->Faster Rcnn->R-FCN->Yolo
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO,系列深度学习检测方法
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理
- 深度学习检测方法梳理:R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理
- 【相关知识】目标检测之||R-CNN||SPP-NET ||Fast-RCNN ||Faster-RCNN||YOLO ||SSD
- RCNN & SPP-net & Fast-RCNN & Faster-RCNN
- RCNN学习笔记(0)-RCNN->SPPnet->Fast RCNN->Faster RCNN
- RCNN & SPP-net & Fast-RCNN & Faster-RCNN
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理
- rcnn,sppnet,fast rcnn,ohem,faster rcnn,rfcn