Mahout 用朴素贝叶斯对20 Newsgroups 数据分类的案例
2018-01-22 21:50
162 查看
源起
《Mahout in Action(Mahout 实战)》这本书的第14.6节有一个用朴素贝叶斯对20 Newsgroups 进行数据分类的案例,但是由于该出出版使用的是mahout0.6版本进行的实验,我用目前最新的0.13版本已经不能再重复这个实验了(mahout做了很多改动)。ERROR MahoutDriver: : Try the new vector backed naivebayes classifier see examples/bin/classify-20newsgroups.sh
对于这个实验可以参考mahout官网给出的教程,Twenty Newsgroups Classification Example
下面是我根据官网的描述的做的实验过程(其实大家跟着官网做是一样的,而且解释的还权威。。。)
过程
1. 将数据集上传到hadoop文件系统hadoop fs -put 20news-bydate-train hdfs://192.168.217.128:9000/user/pangying/testdata/20news-bydate-train
注意可能会报这个错误
java.lang.InterruptedException at java.lang.Object.wait(Native Method) at java.lang.Thread.join(Thread.java:1252) at java.lang.Thread.join(Thread.java:1326) at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:973) at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:624) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:801
但是此错误可以忽略(有博主说这个错误是hadoop的一个bug),检查一下HDFS,发现文件上上传成功的。
2. Convert the full 20 newsgroups dataset into a< Text, Text > SequenceFile.
将文件转成单行文本
mahout seqdirectory -i testdata/20news-bydate-train/ -o 20news-sql -ow
3. Convert and preprocesses the dataset into a < Text,VectorWritable > SequenceFile containing term frequencies for each document.
对样本进行向量化处理
mahout seq2sparse -i 20news-sql-test -o 20news-vectors-test -lnorm -nv -wt tfidf
4. Train the classifier
mahout trainnb -i 20news-vectors/tfidf-vectors -o nbmodel -li labelindex -ow -c5. Test the classifier
mahout testnb -i 20news-vectors-test/tfidf-vectors -m nbmodel -l labelindex -ow -o 20news-testing -c6 控制台会打印出结果
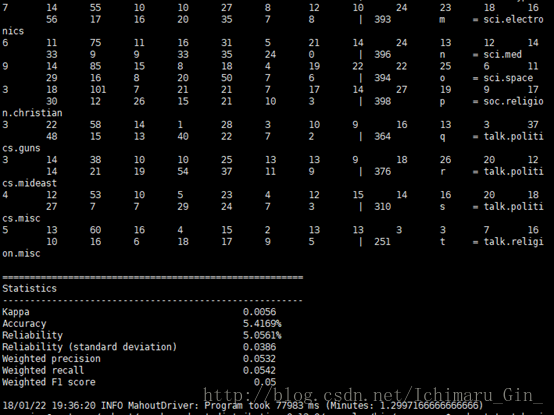
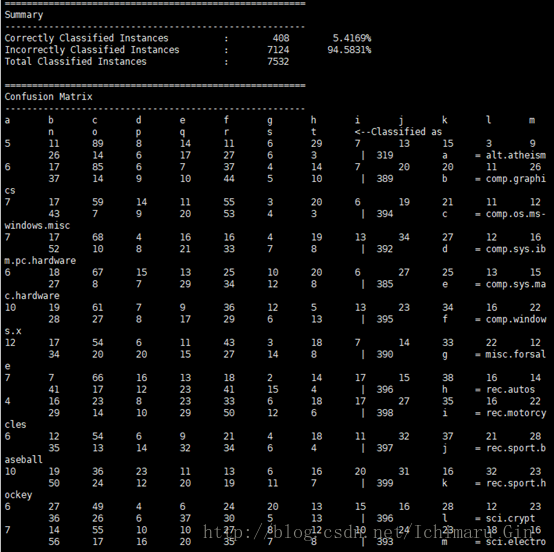
但是我的正确率竟然只有5%。。。肯定是有问题了,这个还需要再分析,但是基本的过程就是这样

相关文章推荐
- 朴素贝叶斯分类算法原理与Python实现与使用方法案例
- 数据挖掘分类方法探究----朴素贝叶斯方法
- 数据挖掘系列(8)朴素贝叶斯分类算法原理与实践
- 数据挖掘系列(8)朴素贝叶斯分类算法原理与实践
- 邮件分类和过滤-朴素贝叶斯NB经典案例
- Python实现基于朴素贝叶斯的垃圾邮件分类 标签: python朴素贝叶斯垃圾邮件分类 2016-04-20 15:09 2750人阅读 评论(1) 收藏 举报 分类: 机器学习(19) 听说
- 数据仓库专题20-案例篇:电商领域数据主题域模型设计v0.1(改进意见征集中)
- Hadoop—Mahout部署及进行20newsgroup数据分析例子---练习10
- 数据挖掘(8):朴素贝叶斯分类算法原理与实践
- Hadoop/MapReduce、Spark 朴素贝叶斯分类器分类符号数据
- 一小时了解数据挖掘②:分类算法的应用和成熟案例解析
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
- mahout測试朴素贝叶斯分类样例
- 数据挖掘经典算法--朴素贝叶斯分类
- 数据挖掘回顾三:分类算法之 朴素贝叶斯 算法
- 数据挖掘算法之深入朴素贝叶斯分类
- 一小时了解数据挖掘②:分类算法的应用和成熟案例解析
- 案例2:数据挖掘---BP神经网络的数据分类—语音特征信号分类
- 数据挖掘系列-朴素贝叶斯分类算法原理与实践