Spark入门之REPL/CLI/spark shell 快速学习
2018-01-22 16:38
579 查看
*注:本文为本人结合网上资料翻译 Apache
Spark 2.x for Java developers 一书而来,仅作个人学习研究之用,支持转载,但务必注明出处。
一、前言
本章的目的是提供指导,以便读者熟悉独立模式下安装Apache Spark的过程及其依赖关系。 然后,我们将开始与Apache Spark的第一次交互,通过使用Spark CLI(称为REPL)进行一些练习。
我们将继续讨论Spark组件以及与Spark相关的常用术语,然后讨论集群环境中Spark工作的生命周期。 我们还将从图形意义上探索Spark作业的执行,从创建DAG到执行Spark Web UI中提供的实用程序的最小任务单元。
最后,我们将通过使用Spark-Submit工具和Rest API讨论Spark Job配置和提交的不同方法来结束本章。
快速安装单机模式spark:
1.下载scala:http://www.scala-lang.org/download/
2.安装scala:rpm -ivh scala-2.12.4.rpm
3.设置scala环境变量:vim /etc/profile
export SCALA_HOME=/usr/share/scalaexport PATH=$SCALA_HOME/bin:$PATH
4.下载spark:http://spark.apache.org/downloads.html
5.解压spark:tar -xvf /opt/spark-2.2.1-bin-hadoop2.7.tgz
6.配置spark环境变量:vim /etc/profile
export SPARK_HOME=/opt/spark/export PATH=$PATH:$SPARK_HOME/bin
大功告成!
通过下述命令启动spark单机模式:
$SPARK_HOME/bin/spark-shell
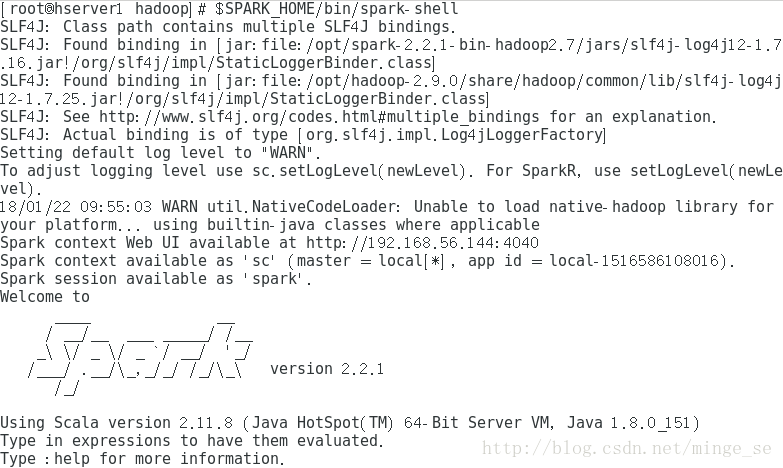
如果Spark二进制文件已经被加入到环境变量PATH中,我们可以简单地执行spark-shell命令即可。
可以在http://localhost:4040中获取spark驱动器用户界面。稍后会细讲
二、开始Spark REPL
Spark REPL或Spark shell(也称为Spark CLI)是探索Spark编程的非常有用的工具。 REPL是Read-Evaluate-Print Loop(读取-求值-打印 循环)的首字母缩写。 它是程序员用来与框架进行交互的交互式shell。 Apache Spark也带有REPL,初学者可以使用它来理解Spark编程模型。
2.1使用Spark shell进行一些基本练习
请注意,Spark shell仅在Scala语言中可用。 但是,我们已经让Java开发人员很容易理解这些例子。
2.1.1确认Spark版本
使用spark shell,通过下面的命令来确认spark脚本:

2.1.2创建和过滤RDD
让我们从创建一个string组成的RDD开始:

现在,我们来过滤这个RDD,使得其只留下以“j”开头的字符串
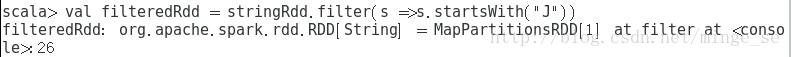
filter将一个rdd转化为另一个rdd,因此filter是transformation操作。
现在,我们对filteredrdd执行一个action操作来看看它的元素。让我们对filteredrdd执行collect操作:

collect操作返回了一个string类型的数组。因此,它是一个action操作。
2.1.3RDD中的word count<
4000
/span>
让我们对前面的stringRdd运行word count问题。word count就是大数据领域的HelloWorld。word count意味着我们将计算RDD中每个元素出现的次数。
我们如下来创建pairRDD变量:

(map():map是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD。任何原RDD中的元素在新RDD中都有且只有一个元素与之对应。)
pairRDD由单词和1(整型)构成的pair组成,其中单词代表的就是stringRDD中的字符串。
现在,我们对这个RDD执行reduceByKey操作来计算每个单词出现的次数。

(*注:reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。)
现在,我们对其进行collect操作来看看结果:

2.1.4查找整数RDD中所有偶数的和
让我们创建一个整数RDD:

我们对这个RDD执行filter操作过滤出所有的偶数:
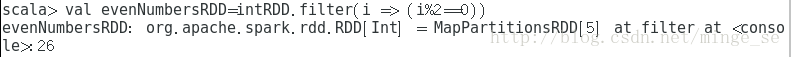
现在,我们把evenNumbersRDD中的所有元素加起来
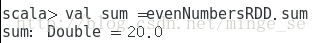
2.1.5 计算文件中的单词数量
我们来读取位于$SPARK_HOME/examples/src/main/resources中的people.txt文件:

在REPL中,用textfile()读取文件:

下一步是扁平化文件的内容,也就是说,我们将通过分割每一行来创建一个RDD,并将列表中的所有单词拼合起来,如下所示:

(flatMap可以理解为先map后flat(扁平化),如此例中可将元素用逗号分隔成两个。而map一个元素只能映射到一个元素。)
flattenFile RDD的内容如下:

现在,我们可以计算这个RDD的所有单词数量。
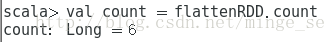
无论何时调用诸如count的action,Spark都会创建一个有向无环图(DAG)来描述每个RDD的沿袭依赖关系。 Spark提供了调试方法toDebugString()来显示RDD的这种沿袭依赖关系:

参考文献:
Apache Spark 2.x for Java developers
S Gulati,S Kumar - 2017 - 被引量: 0
Gulati, Sourav; Kumar, Sumit
Spark 2.x for Java developers 一书而来,仅作个人学习研究之用,支持转载,但务必注明出处。
一、前言
本章的目的是提供指导,以便读者熟悉独立模式下安装Apache Spark的过程及其依赖关系。 然后,我们将开始与Apache Spark的第一次交互,通过使用Spark CLI(称为REPL)进行一些练习。
我们将继续讨论Spark组件以及与Spark相关的常用术语,然后讨论集群环境中Spark工作的生命周期。 我们还将从图形意义上探索Spark作业的执行,从创建DAG到执行Spark Web UI中提供的实用程序的最小任务单元。
最后,我们将通过使用Spark-Submit工具和Rest API讨论Spark Job配置和提交的不同方法来结束本章。
快速安装单机模式spark:
1.下载scala:http://www.scala-lang.org/download/
2.安装scala:rpm -ivh scala-2.12.4.rpm
3.设置scala环境变量:vim /etc/profile
export SCALA_HOME=/usr/share/scalaexport PATH=$SCALA_HOME/bin:$PATH
4.下载spark:http://spark.apache.org/downloads.html
5.解压spark:tar -xvf /opt/spark-2.2.1-bin-hadoop2.7.tgz
6.配置spark环境变量:vim /etc/profile
export SPARK_HOME=/opt/spark/export PATH=$PATH:$SPARK_HOME/bin
大功告成!
通过下述命令启动spark单机模式:
$SPARK_HOME/bin/spark-shell
如果Spark二进制文件已经被加入到环境变量PATH中,我们可以简单地执行spark-shell命令即可。
可以在http://localhost:4040中获取spark驱动器用户界面。稍后会细讲
二、开始Spark REPL
Spark REPL或Spark shell(也称为Spark CLI)是探索Spark编程的非常有用的工具。 REPL是Read-Evaluate-Print Loop(读取-求值-打印 循环)的首字母缩写。 它是程序员用来与框架进行交互的交互式shell。 Apache Spark也带有REPL,初学者可以使用它来理解Spark编程模型。
2.1使用Spark shell进行一些基本练习
请注意,Spark shell仅在Scala语言中可用。 但是,我们已经让Java开发人员很容易理解这些例子。
2.1.1确认Spark版本
使用spark shell,通过下面的命令来确认spark脚本:
2.1.2创建和过滤RDD
让我们从创建一个string组成的RDD开始:
现在,我们来过滤这个RDD,使得其只留下以“j”开头的字符串
filter将一个rdd转化为另一个rdd,因此filter是transformation操作。
现在,我们对filteredrdd执行一个action操作来看看它的元素。让我们对filteredrdd执行collect操作:
collect操作返回了一个string类型的数组。因此,它是一个action操作。
2.1.3RDD中的word count<
4000
/span>
让我们对前面的stringRdd运行word count问题。word count就是大数据领域的HelloWorld。word count意味着我们将计算RDD中每个元素出现的次数。
我们如下来创建pairRDD变量:
(map():map是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD。任何原RDD中的元素在新RDD中都有且只有一个元素与之对应。)
pairRDD由单词和1(整型)构成的pair组成,其中单词代表的就是stringRDD中的字符串。
现在,我们对这个RDD执行reduceByKey操作来计算每个单词出现的次数。
(*注:reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。)
现在,我们对其进行collect操作来看看结果:
2.1.4查找整数RDD中所有偶数的和
让我们创建一个整数RDD:
我们对这个RDD执行filter操作过滤出所有的偶数:
现在,我们把evenNumbersRDD中的所有元素加起来
2.1.5 计算文件中的单词数量
我们来读取位于$SPARK_HOME/examples/src/main/resources中的people.txt文件:
在REPL中,用textfile()读取文件:
下一步是扁平化文件的内容,也就是说,我们将通过分割每一行来创建一个RDD,并将列表中的所有单词拼合起来,如下所示:
(flatMap可以理解为先map后flat(扁平化),如此例中可将元素用逗号分隔成两个。而map一个元素只能映射到一个元素。)
flattenFile RDD的内容如下:
现在,我们可以计算这个RDD的所有单词数量。
无论何时调用诸如count的action,Spark都会创建一个有向无环图(DAG)来描述每个RDD的沿袭依赖关系。 Spark提供了调试方法toDebugString()来显示RDD的这种沿袭依赖关系:
参考文献:
Apache Spark 2.x for Java developers
S Gulati,S Kumar - 2017 - 被引量: 0
Gulati, Sourav; Kumar, Sumit

相关文章推荐
- Spark2.x学习笔记:1、Spark2.2快速入门(本地模式)
- Spark学习2 【翻译】快速入门
- Spark入门,概述,部署,以及学习(Spark是一种快速、通用、可扩展的大数据分析引擎)
- Shell学习快速入门篇
- Spark2.x学习笔记:13、Spark SQL快速入门
- [spark学习]之spark shell 入门
- 【学习笔记】系列七:Lua 语言 15 分钟快速入门
- 快速幂学习入门
- spark入门学习(2)---利用akka建立基于心跳基础的通信框架
- MyBatis学习总结(一)——MyBatis快速入门
- 深度学习Deeplearning4j 入门实战(5):基于多层感知机的Mnist压缩以及在Spark实现
- Objective-C 学习快速入门总结
- spark学习七 共享内存的实现(快速的共享数据)
- 快速入门shell脚本编写(一)
- Gradle学习系列之一——Gradle快速入门
- SpringBoot 基础知识学习(一)——快速入门
- Spark修炼之道(基础篇)——Linux大数据开发基础:第十一节:Shell编程入门(三)
- Python学习笔记(一):基础语法、变量类型、运算符(快速入门篇)
- sql server 快速入门学习笔记(基础)
- [置顶] Spark快速入门指南(Quick Start Spark)