基于ambari搭建hadoop生态圈大数据组件
2018-01-22 14:18
471 查看
Ambari
介绍
Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、Hbase、Zookeper、Sqoop和Hcatalog等。
Apache Ambari 支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeper、Sqoop和Hcatalog等的集中管理。也是5个顶级hadoop管理工具之一。
建议
需对hadoop生态圈的各个组件以及环境配置,参数有一定的知识,才建议使用ambari搭建对比(CDH)
1、Hortonworks Hadoop区别于其他的Hadoop发行版(如Cloudera)的根本就在于,Hortonworks的产品均是百分之百开源。
2、Cloudera有免费版和企业版,企业版只有试用期。
3、apache hadoop则是原生的hadoop。
4、目前在中国流行的是apache hadoop,Cloudera CDH,当然Hortonworks也有用的5、Apache Ambari是一个基于web的工具,用于配置、管理和监视Apache Hadoop集群,支持Hadoop HDFS、Hadoop MapReduce、Hive、HCatalog,、HBase、ZooKeeper、Oozie、Pig和Sqoop。Ambari同样还提供了集群状况仪表盘,比如heatmaps和查看MapReduce、Pig、Hive应用程序的能力,以友好的用户界面对它们的性能特性进行诊断。
准备
安装前先安装好 Centos 7.2, jdk-8u91, mysql5.7.13主节点:master(172.26.99.126)
从节点:slave1(172.26.99.127),slave2(172.26.99.128),slave3(172.26.99.129)
注意事项:确保所有节点时间同步;确保所有节点能互相通信以及能访问外网
配置SSH免密码登录
主节点(master)里root用户登录执行如下步骤ssh-keygen
cd ~/.ssh/
cat id_rsa.pub>> authorized_keys
在从节点登录root执行命令
mkdir ~/.ssh/
分发主节点里配置好的authorized_keys到各从节点
scp/root/.ssh/authorized_keys root@172.26.99.127:~/.ssh/authorized_keys
scp/root/.ssh/authorized_keys root@172.26.99.128:~/.ssh/authorized_keys
scp/root/.ssh/authorized_keys
root@172.26.99.129:~/.ssh/authorized_keys
创建ambari系统用户和用户组
只在主节点操作添加ambari安装、运行用户和用户组,也可以不创建新用户,直接使用root或者系统其他账号
adduser ambari
passwd ambari
开启NTP服务
所有集群上节点都需要操作Centos 7 命令
yum install ntp
systemctl is-enabled ntpd
systemctl enable ntpd
systemctl start ntpd
检查DNS和NSCD
所有节点都要设置ambari在安装时需要配置全域名,所以需要检查DNS.
vi /etc/hosts
172.26.99.126 master.chinadci.com master
172.26.99.127 slave1.chinadci.com slave1
172.26.99.128 slave2.chinadci.com slave2
172.26.99.129 slave3.chinadci.com slave3
每台节点里配置FQDN,如下以主节点为例(要注意FQDN的命名规范:hostname+域名)
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master.chinadci.com
关闭防火墙
所有节点都要设置systemctl disable firewalld
systemctl stop firewalld
关闭SELinux
所有节点都要设置查看SELinux状态:
sestatus
如果SELinuxstatus参数为enabled即为开启状态
SELinux status: enabled
修改配置文件需要重启机器:
vi /etc/sysconfig/selinux
SELINUX=disabled
制作本地源
制作本地源只需在主节点上进行即可相关准备工作
安装 Apache HTTP 服务器
安装HTTP服务器,允许 http服务通过防火墙(永久)
yum install httpd
firewall-cmd --add-service=http
firewall-cmd --permanent --add-service=http
添加Apache
服务到系统层使其随系统自动启动
systemctl start httpd.service
systemctl enable httpd.service
安装本地源制作相关工具
yum install yum-utils createrepo下载安装资源
下载Ambari 2.2.2 , HDP 2.4.2的安装资源,本次安装是在Centos 7
上,只列出centos7的资源,其他系统的请现在对用系统的资源
Ambari 2.2.2 下载资源
| OS | Format | URL |
| CentOS 7 | Base URL | http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.2.0 |
| CentOS 7 | Repo File | http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.2.2.0/ambari.repo |
| CentOS 7 | Tarball md5 asc | http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.2.0/ambari-2.2.2.0-centos7.tar.gz |
| OS | Repository Name | Format | URL |
| CentOS 7 | HDP | Base URL | http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.2.0 |
| CentOS 7 | HDP | Repo File | http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.2.0/hdp.repo |
| CentOS 7 | HDP | Tarball md5 asc | http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.2.0/HDP-2.4.2.0-centos7-rpm.tar.gz |
| CentOS 7 | HDP-UTILS | Base URL | http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7 |
| CentOS 7 | HDP-UTILS | Repo File | http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7/HDP-UTILS-1.1.0.20-centos7.tar.gz |
需要下载的压缩包如下:
Ambari 2.2.2
http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.0.0/HDP-2.4.0.0-centos7-rpm.tar.gz
HDP 2.4.2
http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.2.0/ambari-2.2.2.0-centos7.tar.gz
HDP-UTILS 1.1.0
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7/HDP-UTILS-1.1.0.20-centos7.tar.gz
在httpd网站根目录,默认是即/var/www/html/,创建目录ambari,
并且将下载的压缩包解压到/var/www/html/ambari目录
cd /var/www/html/
mkdir ambari
cd /var/www/html/ambari/
tar -zxvf ambari-2.2.2.0-centos7.tar.gz
tar -zxvf HDP-2.4.2.0-centos7-rpm.tar.gz
tar -zxvf HDP-UTILS-1.1.0.20-centos7.tar.gz
验证httd网站是否可用,可以使用links
命令或者浏览器直接访问下面的地址:
http://172.26.99.126/ambari/
结果如下:
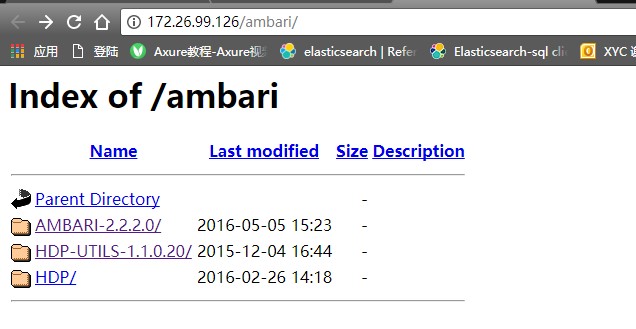
配置ambari、HDP、HDP-UTILS的本地源
首先下载上面资源列表中的相应repo文件,修改其中的URL为本地的地址,相关配置如下:wget http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.2.2.0/ambari.repo
wget http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.2.0/hdp.repo
vi ambari.repo

vi hdp.repo
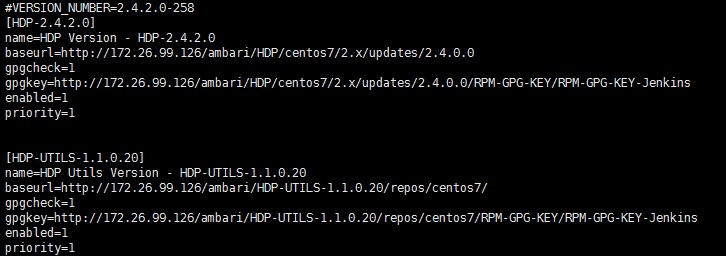
将上面的修改过的源放到/etc/yum.repos.d/下面
执行以下命令
yum clean all
yum list update
yum makecache
yum repolist
安装Mysql数据库
Ambari安装会将安装等信息写入数据库,建议使用自己安装的Mysql数据库,也可以不安装而使用默认数据库PostgreSQLMysql数据库安装过程请参考下面文章:
http://blog.csdn.net/u011192458/article/details/77394703
安装完成后创建ambari数据库及用户,登录root用户执行下面语句:
create database ambari character set utf8 ;
CREATE USER 'ambari'@'%'IDENTIFIED BY 'ambari';
GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'%';
FLUSH PRIVILEGES;
安装mysqljdbc
驱动
yum install mysql-connector-java
安装JDK
安装解压版JDK,先到官网下载jdk-8u91-linux-x64.tar.gz ,再执行下面命令:tar -zxvf jdk-8u91-linux-x64.tar.gz -C /opt/java/
vi /etc/profile
export JAVA_HOME=/opt/jdk1.8
exportCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
source /etc/profile
安装Ambari
安装Ambari2.2.2
安装Ambariyum install ambari-server
配置Ambari
ambari-server setup根据操作选择提示
选择注意:ambari-server服务账号密码都是ambari
JDK路径是自定义路径/var/opt/jdk1.8
数据库配置选择的是自定义安装的Mysql
数据库的账户和密码都是ambari
导入ambari脚本
将Ambari数据库脚本导入到数据库如果使用自己定义的数据库,必须在启动Ambari服务之前导入Ambari的sql脚本
用Ambari用户(上面设置的用户)登录mysql
mysql -u ambari -p
use ambari source/var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
启动Ambari
执行启动命令,启动Ambari服务ambari-server start
成功启动后在浏览器输入Ambari地址:
http://172.26.99.126:8080/
出现登录界面,默认管理员账户登录,账户:admin
密码:admin
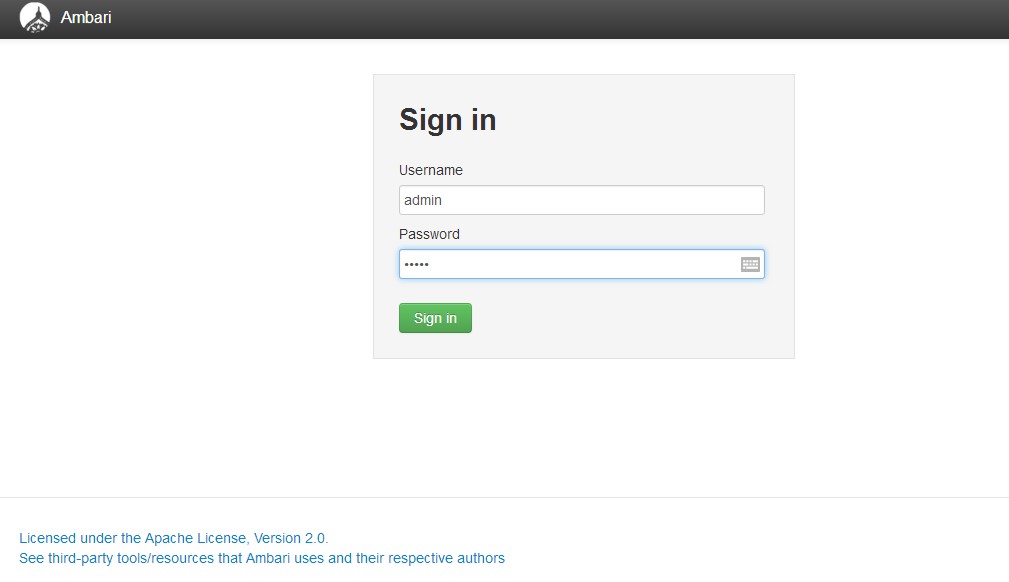
登录成功后出现下面的界面,至此Ambari的安装成功
Ambari集群配置
机架:
slave1.chinadci.com172.26.99.127 /default-rackslave2.chinadci.com172.26.99.128 /default-rack
slave3.chinadci.com172.26.99.129 /default-rack
配置:
Hadoop生态圈的各个组件日志默认安装在各个组件的根目录下,方便用于寻找。利用ambari可以快速的搭建Hadoop集群,安装后各组件的默认安装在各个节点的/usr/hdp/目录下。
Ambari-server服务器的日志目录默认安装在/var/log目录下
Ambari-agent采集器的日志目录默认安装在/var/log目录下
文件备份一般为3个
HDFS默认块大小为128M,则每个文件大小不应小于128。
Yarn默认配置内存8G,即每台节点最少8G、CPU核数8核
参考文献: https://www.cnblogs.com/zhijianliutang/p/5731002.html
Hadoop集群运行的过程是需要将所有的数据分布记录拉入到内存中的,所以这就意味着当整个集群的数据越来越大,我们知道在大数据的环境下,几TB级别或者PB级别的数据是很常见的,这也就意味这个数据分布记录也要增大,所以需要加大内存,这里有一个参考依据:
一般1GB内存可以管理百万个block文件。
举例:bolck为128M,副本为3个,200台集群,4TB数据,需要的Namenode内存为:200(服务器数)x 4194304MB(4TB数据) / (128MB x 3)=2184533.33个文件=2.18百万个文件,所以内存值也就接近于2.2G了。
再次,因为这里有一台机器用来做备份,所以secondarynamenode需要的内存与namenode需要的内存大概一样,然后就是从节点的各台服务器需要的内存量了
首先计算当前CPU的虚拟核数(Vcore):
虚拟核数(Vcore)=CPU个数*单CPU合数*HT(超线程数)
然后根据虚拟核数配置内存容量:
内存容量=虚拟核数(Vcore)*2GB(至少2GB)
关于CPU的选择,因为Hadoop为分布式计算运算,所以其运行模型基本是密集型并行计算,所以推荐的CPU要尽量选择多路多核的,条件允许的话每个节点都要如此。
然后,在一个大型的分布式集群中,还需要注意的是,因为分布式的计算,需要各个节点间进行频繁的通信和IO操作,这也就意味对网络带宽有要求,所以推荐使用千兆以上的网卡,条件允许可以万兆网卡,交换机亦如此。
注意:由于zookeeper等一些组件需要选举leader以及follow,所需节点数最少为3节点以上而且奇数,否则一个节点挂掉,导致集群无法选择leader,整个zookeeper就无法运行。
举例:
集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。也就是说如果有2个zookeeper,那么只要有1个死了zookeeper就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0;同理,要是有3个zookeeper,一个死了,还剩下2个正常的,过半了,所以3个zookeeper的容忍度为1;同理你多列举几个:2->0;3->1;4->1;5->2;6->2会发现一个规律,2n和2n-1的容忍度是一样的,都是n-1,所以为了更加高效,何必增加那一个不必要的zookeeper。

相关文章推荐
- 基于Hadoop生态圈的数据仓库实践 —— 环境搭建(一)
- 基于Ambari搭建Hadoop生态圈
- 基于Hadoop生态圈的数据仓库实践 —— 环境搭建(三)
- 基于Apache Ambari搭建Hadoop大数据平台
- 基于Hadoop生态圈的数据仓库实践 —— 环境搭建(二)
- 基于Hadoop生态圈的数据仓库实践 —— 进阶技术(十四)
- 基于hadoop生态圈的数据仓库实践 —— 进阶技术(十五)
- 基于centos7搭建hadoop+zookeeper+hbase大数据集群
- 基于Hadoop生态圈的数据仓库实践 —— ETL(一)
- 基于hadoop生态圈的数据仓库实践 —— OLAP与数据可视化(四)
- 基于Hadoop生态圈的数据仓库实践 —— 进阶技术(六)
- 基于hadoop生态圈的数据仓库实践 —— 进阶技术(十六)
- 基于Hadoop生态圈的数据仓库实践 —— 进阶技术(七)
- 基于Hadoop生态圈的数据仓库实践 —— 进阶技术(二)
- 基于hadoop生态圈的数据仓库实践 —— OLAP与数据可视化(六)
- 基于Hadoop的数据分析平台搭建 - 大数据
- 基于Hadoop2.6.0搭建的大数据集群
- 基于Hadoop生态圈的数据仓库实践 —— 进阶技术(十一)
- 基于Hadoop的数据分析平台搭建 - 大数据
- 基于Hadoop生态圈的数据仓库实践 —— 进阶技术(四)