使用python 批量 配对t检验 医学 基础研究 数据分析
2018-01-21 16:44
483 查看
需要excel数据源文件的请去http://download.csdn.net/download/camelbrand/10216783下载,只保留少数列的数据,剩余的2000多个数据已经被我删除了。
帮学医的同学弄完一个python数据处理的程序,怕以后忘记了,记录下来
t检验是计量资料的假设检验中最为简单常用的,当样本含量n较小时,比如n小于60。配对t检验又称成对t检验,适用于配对设计的计量资料。配对设计是将受试对象按照某些重要特征,如可疑混杂因素性别等配成对子,每对中的两个受试对象随机分配到两处理组。
要计算的部分数据如下,从列LINC01587开始,一共有2027列数据:
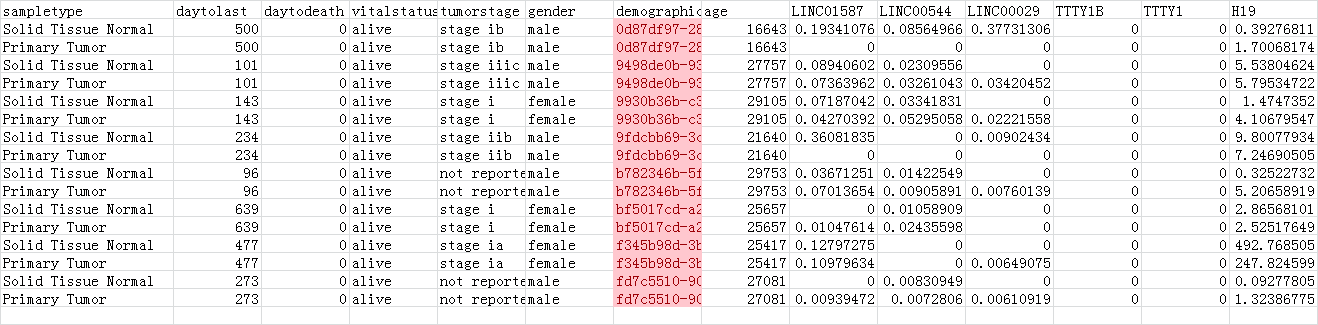
其中Solid Tissue Normal和Primary Tumor是一对,如第2行和第3行是一对,第4行和第5行是一对,以此类推。需要完成的工作是从LINC01587开始,计算该列的数据的差异有无统计学意义。通常使用的spss工具来计算,安装IBM SPSS Statics之后,先来个demo学习计算LINC01587演示下。
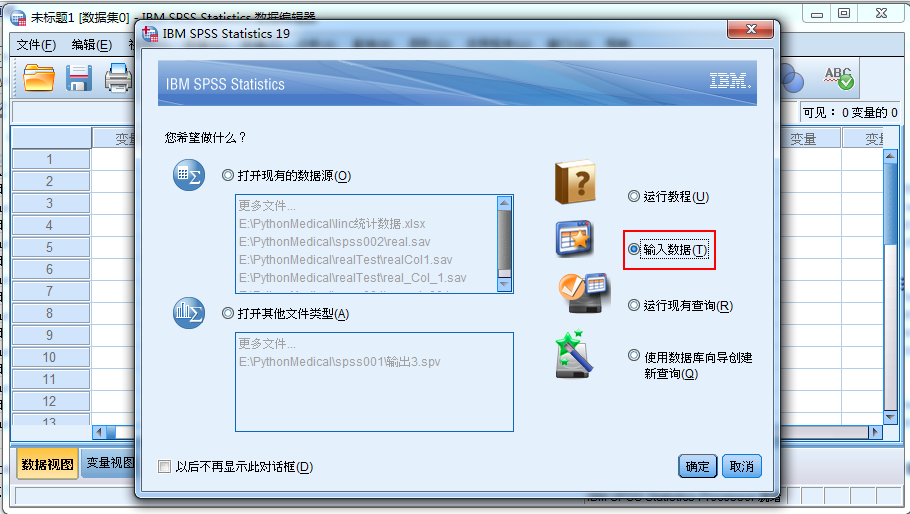
1.启动IBM SPSS Statics,选择输入数据,点击确定
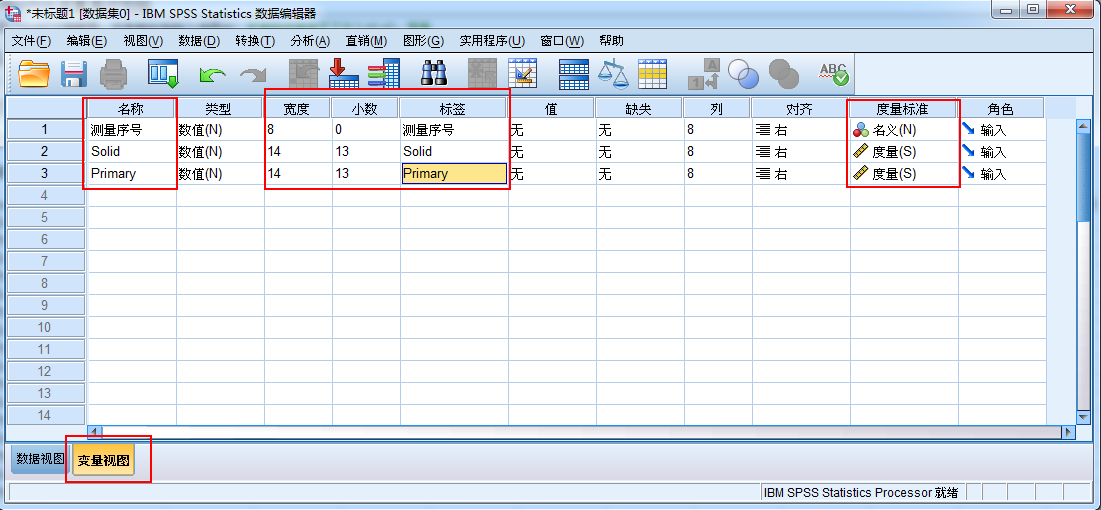
2.弹出界面中,新建变量视图,如下图所示填入参数Solid代表Solid Tissue Normal
Primary代表Primary Tumor,然后点击数据视图
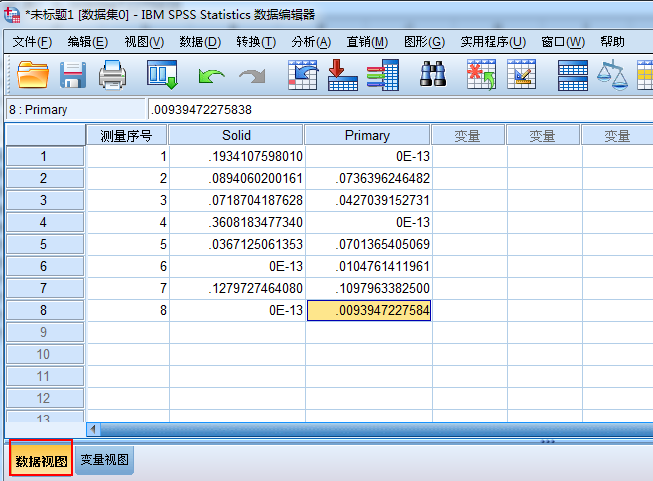
按照上面的表格数据,将列LINC01587以此填入,如下图所示,其中0E-13表示为0
3.点击分析,选择比较均值,然后选择配对样本T检验

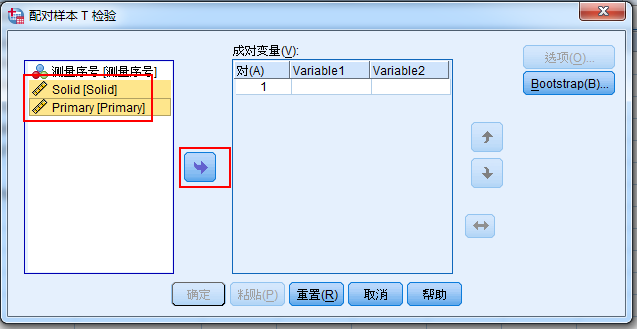
弹出界面中,按下键盘上的Ctrl键,然后依次选中左边红色框内的Solid和Primary,然后点击右边红框内的的箭头
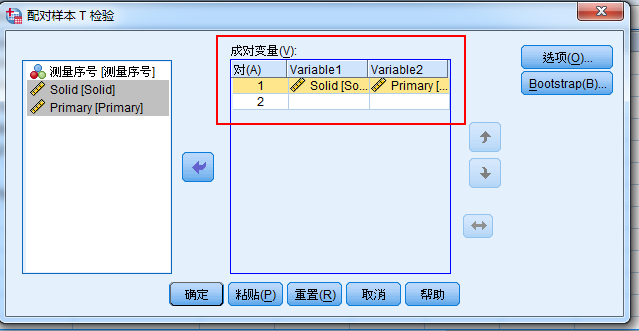
如上图所示,点击确定,SPSS输出计算结果如下,其中右下角红色框内的是我们需要的结果。

上图计算得到的p值是0.188。
第一个表格是数据的基本描述。
第二个是数据前后变化的相关系数,那个概率P值是相关系数的概率值,概率大于显著性水平0.05,则说明数据变化前后没有显著的线性变化,线性相关程度较弱。
第三个表格是数据相减后与0的比较,通过概率值为0,小于显著性水平0.05,则拒绝原假设,相减的差值与0有较大差别,则表明数据变化前后有显著的变化。
但是数据源有2027列数据都需要计算,工作量巨大,可以考虑使用python来完成这部分工作。
那么我们设计python程序需要完成的工作包括:
1.打开excel数据文件,并读取文件数据
2.依次对所有列数据进行计算,并输出p值计算结果。
地址为http://blog.csdn.net/hjh00/article/details/48530183的博客,最后一部分内容给出了如何使用python完成配对t检验的程序
使用python开发程序,首先需要安装python,本人的电脑上已经安装了python的开发环境,具体配置参考python教程(按照这个教程一步一步来学习入门)https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
配置好python之后,在windows CMD命令行输入python,显示我的python版本号是 Python 3.6.1

上面博客给出的配对t检验计算程序如下图,但是安装好python之后,可能电脑上并没有scipy.stats,为了安装scipy(后面部门的excel处理功能可能也没有安装),可以参考网址:
https://www.cnblogs.com/babyfei/p/7080047.html?utm_source=itdadao&utm_medium=referral
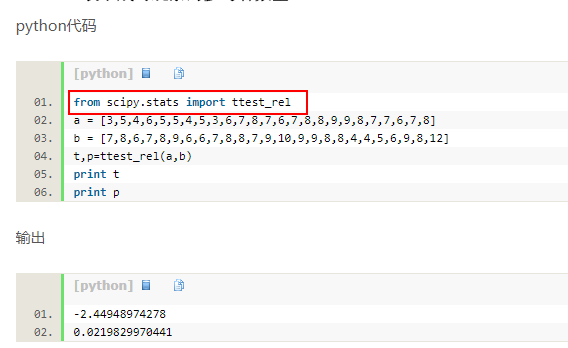
安装好python开发环境之后,要完成上面SPSS计算的工作,我们只需要列出下,加了#号的都是注释,不会执行,我的程序只是把列表变量a和b替换成列LINC01587的数据,其中a是Solid Tissue Normal,b代表Primary Tumor
执行上面的程序,分别打印t和p,红色框内的p值与上面SPSS计算的p值结果一致:
那么接下来的工作只需要设计使用python对excel文件进行处理的部分了,我的代码如下(实际调试我使用了软件Geany作为编辑器,可以很方便的编辑和运行python程序):
针对其他格式不一致的表格,改程序未必生效,比较关键的参数是38行row[0]中的0,以及52行的数字8,都是根据excel表内容自定义写入的。
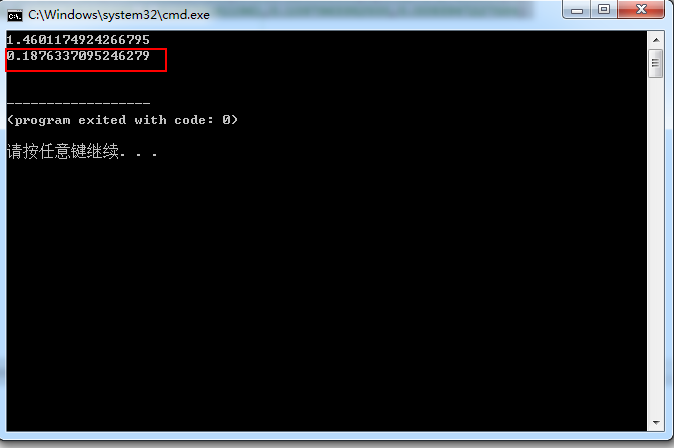
print(xxx,file=f)的结果会输出到python程序文件所在目录的excel.txt文本文档中,输出结果如下,最后一行就是从LINC01587列开始计算的p值,nan表示该列数据计算的p无效
main function
<class 'list'>
calculate 8
calculate 9
calculate 10
calculate 11
calculate 12
calculate 13
calc over
[0.18763370952460945, 0.6178834746354206, 0.45183198301444494, nan, nan, 0.3665736965096091]
后续还可以直接使用python将计算结果写入excel表中,我这里只做到了通过txt文本打印输出。如果有时间,可以继续开发研究一下。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
my mail:shaw2321@163.com
帮学医的同学弄完一个python数据处理的程序,怕以后忘记了,记录下来
t检验是计量资料的假设检验中最为简单常用的,当样本含量n较小时,比如n小于60。配对t检验又称成对t检验,适用于配对设计的计量资料。配对设计是将受试对象按照某些重要特征,如可疑混杂因素性别等配成对子,每对中的两个受试对象随机分配到两处理组。
要计算的部分数据如下,从列LINC01587开始,一共有2027列数据:
其中Solid Tissue Normal和Primary Tumor是一对,如第2行和第3行是一对,第4行和第5行是一对,以此类推。需要完成的工作是从LINC01587开始,计算该列的数据的差异有无统计学意义。通常使用的spss工具来计算,安装IBM SPSS Statics之后,先来个demo学习计算LINC01587演示下。
1.启动IBM SPSS Statics,选择输入数据,点击确定
2.弹出界面中,新建变量视图,如下图所示填入参数Solid代表Solid Tissue Normal
Primary代表Primary Tumor,然后点击数据视图
按照上面的表格数据,将列LINC01587以此填入,如下图所示,其中0E-13表示为0
3.点击分析,选择比较均值,然后选择配对样本T检验
弹出界面中,按下键盘上的Ctrl键,然后依次选中左边红色框内的Solid和Primary,然后点击右边红框内的的箭头
如上图所示,点击确定,SPSS输出计算结果如下,其中右下角红色框内的是我们需要的结果。
上图计算得到的p值是0.188。
第一个表格是数据的基本描述。
第二个是数据前后变化的相关系数,那个概率P值是相关系数的概率值,概率大于显著性水平0.05,则说明数据变化前后没有显著的线性变化,线性相关程度较弱。
第三个表格是数据相减后与0的比较,通过概率值为0,小于显著性水平0.05,则拒绝原假设,相减的差值与0有较大差别,则表明数据变化前后有显著的变化。
但是数据源有2027列数据都需要计算,工作量巨大,可以考虑使用python来完成这部分工作。
那么我们设计python程序需要完成的工作包括:
1.打开excel数据文件,并读取文件数据
2.依次对所有列数据进行计算,并输出p值计算结果。
地址为http://blog.csdn.net/hjh00/article/details/48530183的博客,最后一部分内容给出了如何使用python完成配对t检验的程序
使用python开发程序,首先需要安装python,本人的电脑上已经安装了python的开发环境,具体配置参考python教程(按照这个教程一步一步来学习入门)https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
配置好python之后,在windows CMD命令行输入python,显示我的python版本号是 Python 3.6.1
上面博客给出的配对t检验计算程序如下图,但是安装好python之后,可能电脑上并没有scipy.stats,为了安装scipy(后面部门的excel处理功能可能也没有安装),可以参考网址:
https://www.cnblogs.com/babyfei/p/7080047.html?utm_source=itdadao&utm_medium=referral
安装好python开发环境之后,要完成上面SPSS计算的工作,我们只需要列出下,加了#号的都是注释,不会执行,我的程序只是把列表变量a和b替换成列LINC01587的数据,其中a是Solid Tissue Normal,b代表Primary Tumor
# http://blog.csdn.net/hjh00/article/details/48530183 from scipy.stats import ttest_rel #a = [3,4,1,1,1,3,3,6,5,1,4,5,4,4,3,6,7,7,7,8] #b = [7,6,7,8,7,6,5,6,4,2,5,4,3,6,7,5,4,3,8,7] a = [0.1934107598010,0.0894060200161,0.0718704187628,0.3608183477340,0.0367125061353,0,0.1279727464080,0] b= [0,0.0736396246482,0.0427039152731,0,0.0701365405069,0.0104761411961,0.1097963382500,0.0093947227584] t,p=ttest_rel(a,b) print (t ) print (p )
执行上面的程序,分别打印t和p,红色框内的p值与上面SPSS计算的p值结果一致:
那么接下来的工作只需要设计使用python对excel文件进行处理的部分了,我的代码如下(实际调试我使用了软件Geany作为编辑器,可以很方便的编辑和运行python程序):
1 # -*- coding: utf-8 -*-
2 import xdrlib ,sys
3 import xlrd
4 from scipy.stats import ttest_rel
5
6 #打开excel文件
7 def open_excel(file= 'test.xlsx'):
8 try:
9 data = xlrd.open_workbook(file)
10 return data
11 except Exception as e:
12 print (str(e))
13
14 #根据名称获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的索引 ,by_name:Sheet1名称
15 def excel_table_byname(file= 'test.xlsx', colnameindex=0, by_name=u'Sheet1'):
16 data = open_excel(file) #打开excel文件
17 table = data.sheet_by_name(by_name) #根据sheet名字来获取excel中的sheet
18 nrows = table.nrows #行数
19 nCol = table.ncols #列数
20 print("row count is",nrows)
21 print("colume count is",nCol)
22 colnames = table.row_values(colnameindex) #某一行数据
23 list =[] #装读取结果的序列
24 for rownum in range(0, nrows): #遍历每一行的内容
25 row = table.row_values(rownum) #根据行号获取行
26 if row: #如果行存在
27 app = [] #一行的内容
28 for i in range(len(colnames)): #一列列地读取行的内容
29 app.append(row[i])
30 list.append(app) #装载数据
31
32 return list
33
34 def get_col(table,col,fstStr):
35 listdata = []
36 #sprint(col,type(col))
37 for row in table:
38 if(row[0]==fstStr):
39 listdata.append(row[col])
40 return listdata
41
42 #主函数
43 def main():
44 tables = excel_table_byname()
45 f = open("./excel.txt", 'w+')
46 print("main function", file=f)
47 print(type(tables), file=f)
48 TotalCol = len(tables[0])
49 #for row in tables:
50 #print (row)
51 p_result = [];
52 for n in range(8,TotalCol):
53 print("calculate",n, file=f)
54 list1 = get_col(tables,n,"Solid Tissue Normal")
55 list2 = get_col(tables,n,"Primary Tumor")
56 t,p=ttest_rel(list1,list2)
57 p_result.append(p)
58 print("calc over", file=f)
59 print(p_result, file=f)
60 if __name__=="__main__":
61 main()针对其他格式不一致的表格,改程序未必生效,比较关键的参数是38行row[0]中的0,以及52行的数字8,都是根据excel表内容自定义写入的。
print(xxx,file=f)的结果会输出到python程序文件所在目录的excel.txt文本文档中,输出结果如下,最后一行就是从LINC01587列开始计算的p值,nan表示该列数据计算的p无效
main function
<class 'list'>
calculate 8
calculate 9
calculate 10
calculate 11
calculate 12
calculate 13
calc over
[0.18763370952460945, 0.6178834746354206, 0.45183198301444494, nan, nan, 0.3665736965096091]
后续还可以直接使用python将计算结果写入excel表中,我这里只做到了通过txt文本打印输出。如果有时间,可以继续开发研究一下。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
my mail:shaw2321@163.com

相关文章推荐
- Python数据分析基础模块:Anaconda的安装以及简单使用
- 使用python向Redis批量导入数据
- 使用python进行数据分析
- Python 数据分析-pandas 基础
- Python 数据分析包:pandas 基础
- 各种工具使得数据分析工作使用python变得越来越流行
- Python 数据分析包:pandas 基础
- Python 数据分析包:pandas 基础
- ASP.NET基础教程-使用CommandBuilder对象自动生成SQL语句对数据进行批量更新
- 使用Python工具分析风险数据 20160723
- 使用Python批量下载数据
- 利用python进行数据分析-NumPy基础
- python基础练习(二)—— 数据分析包numpy数组操作
- 使用python中的urlretrieve下批量下载数据
- 使用python,批量导入数据到elasticsearch中
- Python数据分析入门之pandas总结基础
- matplotlib -- 使用python中的matplotlib进行绘图分析数据
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
- 【Python】Python的数据分析(二)——pandas安装及使用