Hadoop 2.0集群体系结构联合概述
2018-01-21 16:30
417 查看
Hadoop 2.0集群体系结构联合
介绍:
在这篇博客中,我将深入探讨Hadoop 2.0集群架构联盟。自ApacheHadoop 1.x发布以来,Apache Hadoop已经发展了很多。正如你在我之前的博客中所说的那样,HDFS体系结构遵循主/从拓扑结构,其中NameNode作为主守护进程,负责管理其他从属节点(称为DataNode)。在这个生态系统中,这个单一的主守护进程或NameNode成为一个瓶颈,相反,公司需要具有高可用性的NameNode。这就是HDFS联盟架构和HA(高可用性)架构的基础。
我在这个博客中涉及的主题如下:
目前的HDFS架构
当前HDFS体系结构的局限性
HDFS联邦体系结构
当前HDFS体系结构概述:
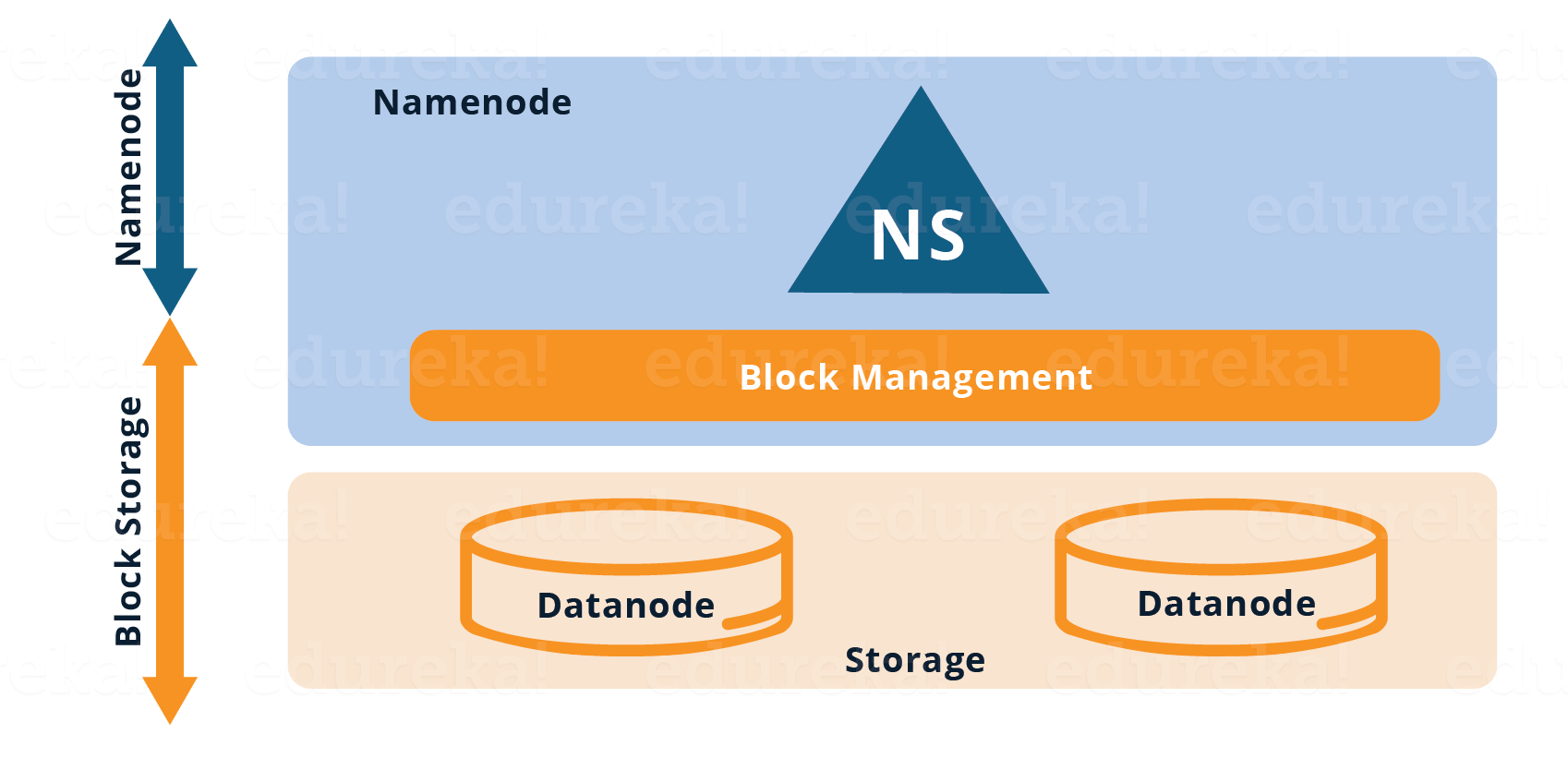
如上图所示,目前的HDFS有两层:
HDFS命名空间(NS):该层负责管理目录,文件和块。它提供了与命名空间相关的所有文件系统操作,如创建,删除或修改文件或文件目录。
存储层:它包含两个基本组件。
块管理:它执行以下操作:
定期检查DataNode的心跳,并管理DataNode成员的集群。
管理块报告并保持块位置。
支持块创建,修改,删除和块位置分配等操作。
在整个群集中保持一致的复制因子。
2. 物理存储:由DataNode管理,DataNode负责存储数据,从而为存储在HDFS中的数据提供读/写访问。
所以,目前的HDFS体系结构允许你为一个集群拥有一个单一的命名空间。在这个架构中,一个NameNode负责管理名称空间。这个架构非常方便,易于实现。而且,它提供了足够的能力来满足小型生产集群的需求。
当前HDFS的限制:
如前所述,目前的HDFS确实足以满足小型生产集群的需求和使用情况。但是像雅虎,Facebook这样的大型组织却发现了一些局限性,因为HDFS集群呈指数级增长。让我们快速看看一些限制:名称空间不像DataNodes 那样可伸缩。因此,我们可以在群集中只有一个NameNode可以处理的数量的DataNode。
命名空间层和存储层紧密结合在一起使得NameNode的交替实现非常困难。
整个Hadoop系统的性能取决于NameN
c0aa
ode 的吞吐量。因此,所有HDFS操作的整个性能取决于NameNode在特定时间可以处理多少个任务。
NameNode将整个名称空间存储在RAM中以便快速访问。这会导致内存大小的限制,即单个名称空间服务器可以应付的名称空间对象(文件和块)的数量。
许多具有HDFS部署的组织(供应商)允许多个组织(租户)使用其集群命名空间。所以,没有名称空间的分离,因此使用集群的租户组织之间没有隔离。
HDFS联邦体系结构:
在HDFS联邦体系结构中,我们具有名称服务的水平可伸缩性。因此,我们有多个联合的NameNode,即彼此独立。DataNodes存在于底层存储层。
每个DataNode注册集群中的所有NameNode。
DataNodes传输周期性心跳,阻止报告并处理来自NameNode的命令。
下面给出HDFS联邦体系结构的图形表示:
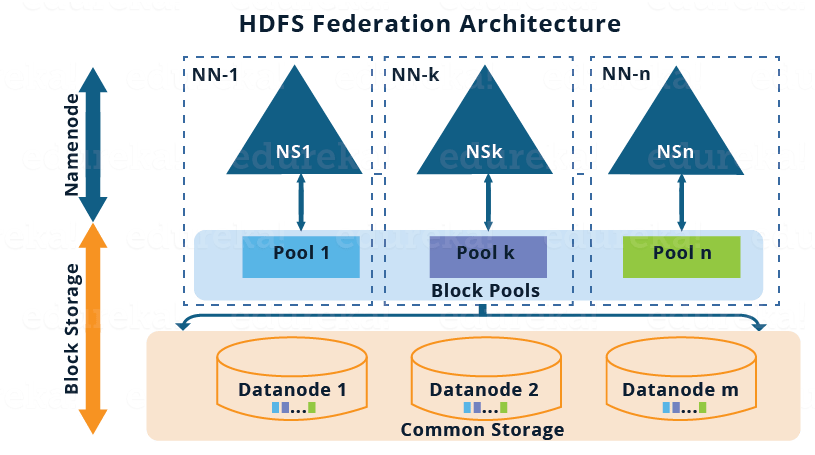
在继续之前,让我简单地谈一谈上面的建筑形象:
有多个命名空间(NS1,NS2,...,NSn),每个命名空间由其各自的NameNode管理。
每个命名空间都有自己的块池(NS1有池1,NSk有池k等等)。
如图所示,池1中的块(天蓝色)存储在DataNode
1,DataNode 2等上。同样,每个块池中的所有块都将驻留在所有DataNode上。
现在,我们来详细了解HDFS Federation Architecture的组件:
Block Pool:
块池只是属于特定名称空间的一组块。所以,我们有一个块池的集合,其中每个块池都是独立管理的。独立管理每个块池的独立性允许命名空间为新块创建块ID,而无需与其他命名空间协调。存在于所有块池中的数据块存储在所有的DataNode中。基本上,块池提供了一个抽象,使得驻留在DataNode中的数据块(如在单个名称空间体系结构中)可以被分组,对应于特定的名称空间。
命名空间量:
命名空间卷除了命名空间外还有块池。因此,在HDFS联合中,我们有多个名称空间卷。它是一个独立的管理单元,即每个命名空间的卷可以独立运作。如果一个NameNode或名称空间被删除,那么驻留在DataNode上的相应的块池也将被删除。
Hadoop
2.0集群体系结构联合体演示 Edureka
现在,我猜你对HDFS联邦体系结构有一个很好的想法。这更多的是理论上的概念,人们一般不会在实际的生产系统中使用它。HDFSFederation有一些实现问题,使得部署变得困难。因此,HA(高可用性)架构首选解决单点故障问题。我在下一篇博客中介绍了HDFS
HA架构。

相关文章推荐
- Hadoop 2.0集群配置详细教程
- Hadoop 2.0集群配置详细教程
- 大数据入门第五天——离线计算之hadoop(上)概述与集群安装
- CentOS7 基于Hadoop2.7 的Spark2.0集群搭建
- hadoop2.0集群搭建详解
- CentOS7 基于Hadoop2.7 的Spark2.0集群搭建
- Hadoop集群算法调用--web平台2.0
- RedHadoop创始人童小军在北京开讲“Hadoop2.0集群优化与管理”啦!
- Spark2.0 + Hadoop2.7.2 + Centos7 集群部署<一>
- Hadoop2.0 HA集群搭建步骤
- Hadoop2.0 HA 集群搭建步骤
- Linux7 下Hadoop集群用户管理方案之一 用户管理集群方案概述
- hadoop2.0 做spider下载集群的设置
- Cloudera Hadoop 4 实战课程(Hadoop 2.0、集群界面化管理、电商在线查询+日志离线分析)
- Hadoop2.0集群安装配置
- 基于hadoop2.7集群的Spark2.0,Sqoop1.4.6,Mahout0.12.2完全分布式安装
- Cloudera Hadoop 4 实战课程(Hadoop 2.0、集群界面化管理、电商在线查询+日志离线分析)
- Hadoop 2.0集群配置详细教程[虚拟机下配置成功]
- hadoop2.0集群版本在线升级方法
- Cloudera Hadoop 4 实战课程(Hadoop 2.0、集群界面化管理、电商在线查询+日志离线分析