RabbitMQ下的生产消费者模式与订阅发布模式
2018-01-18 20:02
405 查看
所谓模式,就是在某种场景下,一类问题及其解决方案的总结归纳。生产消费者模式与订阅发布模式是使用消息中间件时常用的两种模式,用于功能解耦和分布式系统间的消息通信,以下面两种场景为例:数据接入
假设有一个用户行为采集系统,负责从App端采集用户点击行为数据。通常会将数据上报和数据处理分离开,即App端通过REST API上报数据,后端拿到数据后放入队列中就立刻返回,而数据处理则另外使用Worker从队列中取出数据来做,如下图所示。

这样做的好处有:第一,功能分离,上报的API接口不关心数据处理功能,只负责接入数据;第二,数据缓冲,数据上报的速率是不可控的,取决于用户使用频率,采用该模式可以一定程度地缓冲数据;第三,易于扩展,在数据量大时,通过增加数据处理Worker来扩展,提高处理速率。这便是典型的生产消费者模式,数据上报为生产者,数据处理为消费者。
事件分发
假设有一个电商系统,那么,用户“收藏”、“下单”、“付款”等行为都是非常重要的事件,通常后端服务在完成相应的功能处理外,还需要在这些事件点上做很多其他处理动作,比如发送短信通知、记录用户积分等等。我们可以将这些额外的处理动作放到每个模块中,但这并不是优雅的实现,不利于功能解耦和代码维护。
我们需要的是一个事件分发系统,在各个功能模块中将对应的事件发布出来,由对其感兴趣的处理者进行处理。这里涉及两个角色:A对B感兴趣,A是处理者,B是事件,由事件处理器完成二者的绑定,并向消息中心订阅事件。服务模块是后端的业务逻辑服务,在不同的事件点发布事件,事件经过消息中心分发给事件处理器对应的处理者。整个流程如下图所示。这边是典型的订阅发布模式。

可以看到,生产消费者模式与订阅发布模式都离不开消息中间件来作为消息中转站,开源的消息中间件有很多,各有优劣。本文将重点探讨RabbitMQ的特性,以及如何实现上述的两种场景。RabbitMQ核心概念 如果你只是想使用一下RabbitMQ,那么参考官方教程修改一下就可以跑起来了,很简单。如果你有一些概念上的疑惑,不妨与笔者一起来总结一下RabbitMQ的核心概念。通信方式
RabbitMQ是基于AMQP协议来实现的消息中间件。AMQP,类似于HTTP协议,也是一个应用层的协议,网络层使用TCP来通信。因此,RabbitMQ也是典型的C-S模型,准确地说是C-S-C模型,因为伴随着RabbitMQ的使用,总是会有Producer与Consumer两个Client和一个Broker Server。

Client要与Server进行通信,就必须先建立连接,RabbitMQ中有Connection与Channel两个概念,前者就是一个TCP连接,后者是在这个连接上的虚拟概念,负责逻辑上的数据传递,因此,为了节省资源,一般在一个客户端中建立一个Connection,每次使用时再分配一个Channel即可。
消息体
Message是RabbitMQ中的消息体概念。类似HTTP传输中,有header和body两部分数据,Message中也有Attributes和Payload两部分数据,前者是一些元信息,后者是传递的消息数据实体。
消息投递
Exchange、Queue与Routing Key三个概念是理解RabbitMQ消息投递的关键。RabbitMQ中一个核心的原则是,消息不能直接投递到Queue中。Producer只能将自己的消息投递到Exchange中,由Exchange按照routing_key投递到对应的Queue中,具体的架构参见下图。细细品味就会体会到这样设计的精妙之处。
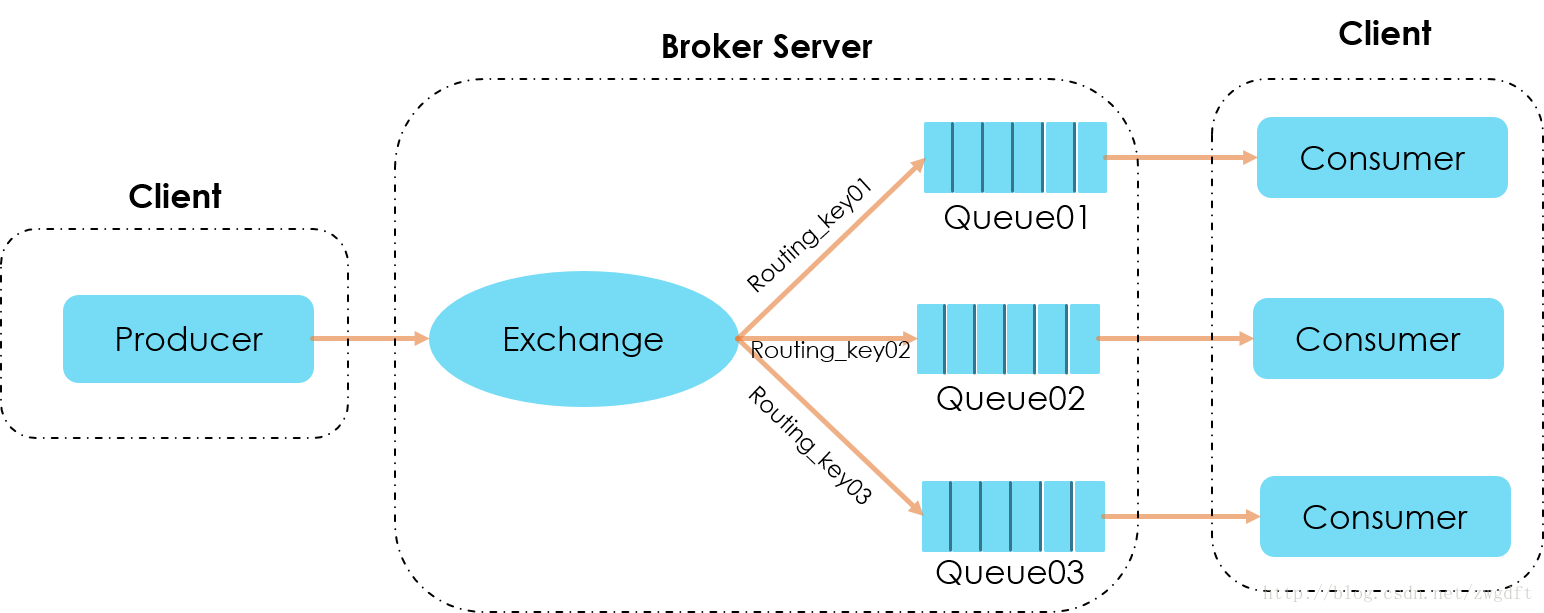
那么,具体实现时,如何完成这三者关系的绑定?总结起来是两点:第一,在Consumer Worker中,声明自己对哪个Exchange感兴趣,并将自己的Queue绑定到自己感兴趣的一组routing_key上,建立相应的映射关系;第二,在Producer中,将消息投递一个Exchange中,并指明它的routing_key。由此可见,Queue这个概念只是对Consumer可见,Producer并不关心消息被投递到哪个Queue中。
看过RabbitMQ的”Hello World”教程的童鞋可能会发现在那里面的图中并没有看到Exchange和routing_key的踪迹,但这并不意味着RabbitMQ可以支持直接将消息投递到Queue中,而是在内部使用了默认的Exchange和routing_key了。默认情况下,RabbitMQ使用名称为“amq.direct”的Direct Exchange,routing_key默认名字与Queue保持一致。
搞清楚上述概念,就不难理解Exchange的四种类型了。Direct、Fanout、Topic、Headers,区别在于如何将消息从Exchange投递到Queue中。Direct使用具体的routing_key来投递;Fanout则忽略routing_key,直接广播给所有的Queue;Topic是使用模糊匹配来对一组routing_key进行投递;Headers也是忽略routing_key,使用消息中的Headers信息来投递。
消息可靠性
不同于HTTP的同步访问,RabbitMQ中,Producer并不知道消息是否被可靠地投递到了Consumer中处理。那么,RabbitMQ是如何保证消息的可靠投递?主要是两点:第一,消息确认机制。Consumer处理完消息后,需要发送确认消息给Broker Server,可以选择“确认接收”、“丢弃”、“重新投递”三种方式。如果Consumer在Broker Server收到确认消息之前挂了,Broker Server便会重新投递该消息。第二,可以选择数据持久化,这样即使RabbitMQ重启,也不会丢失消息。
生产消费者模式 搞清楚了RabbitMQ的核心概念,要针对特定的场景来设计使用方案就很简单了,基本上就是上述RabbitMQ架构图的变迁。让我们先来看看文章开头提到的“数据接入”场景,如何实现生产消费者模式。
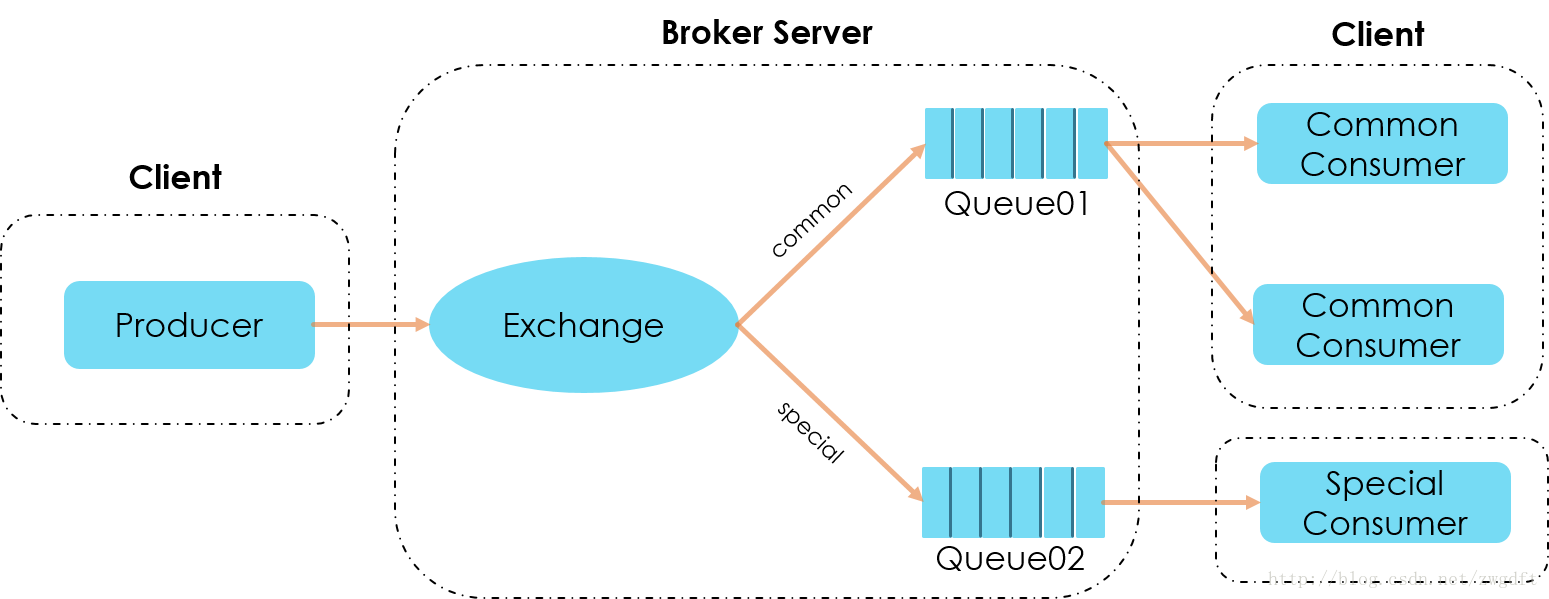
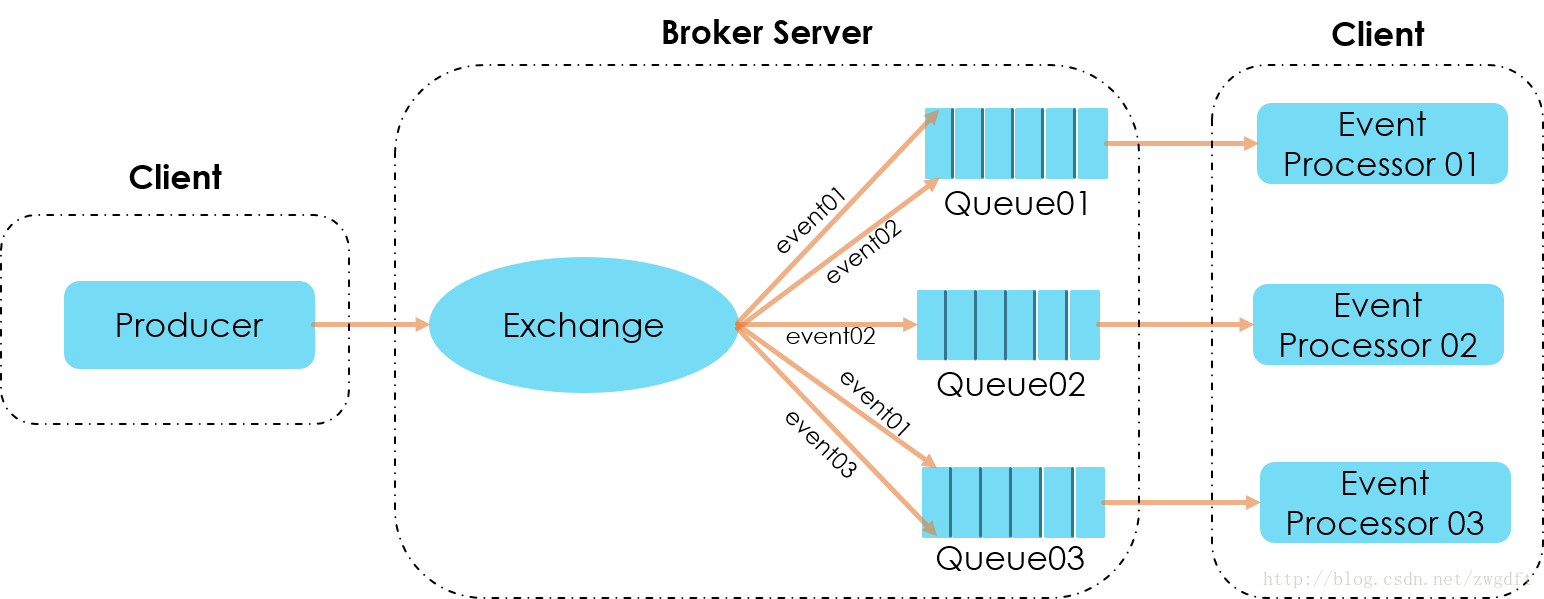
这里增加了一下场景复杂度:对于上报的数据,如果是special的行为,需要优先处理。从上图可以看到,数据上报端负责将数据投递到RabbitMQ对应的Exchange,并指明routing_key是common还是special。数据处理端,可以根据情况启多个Woker来消费数据,但至少需要两个,一个用来处理common数据,一个用来处理special的数据。注意:当需要增加多个Worker来消费同一类数据时,需要保持Queue名字一致,比如上面的Common数据。订阅发布模式 再来看“事件分发”的场景,架构如下图所示,使用event name/id来作为RabbitMQ的routing key的名字。Event Processor 01对event 01 和event 02感兴趣,则在启动Consumer Worker时,将自己的Queue绑定到这两个routing key上即可,其他Event Processor也是如此,这样便完成了事件的订阅。当有事件发布时,消息便会按照event name/id被投递到对应的Queue中。
由此可见,在不同的应用中,变化的只是routing_key与Consumer Queue的绑定关系,在充分理解RabbitMQ的核心概念后处理这些应该也是得心应手了。
(全文完,本文地址:http://blog.csdn.net/zwgdft/article/details/53561277)
Bruce,2016/12/11
假设有一个用户行为采集系统,负责从App端采集用户点击行为数据。通常会将数据上报和数据处理分离开,即App端通过REST API上报数据,后端拿到数据后放入队列中就立刻返回,而数据处理则另外使用Worker从队列中取出数据来做,如下图所示。
这样做的好处有:第一,功能分离,上报的API接口不关心数据处理功能,只负责接入数据;第二,数据缓冲,数据上报的速率是不可控的,取决于用户使用频率,采用该模式可以一定程度地缓冲数据;第三,易于扩展,在数据量大时,通过增加数据处理Worker来扩展,提高处理速率。这便是典型的生产消费者模式,数据上报为生产者,数据处理为消费者。
事件分发
假设有一个电商系统,那么,用户“收藏”、“下单”、“付款”等行为都是非常重要的事件,通常后端服务在完成相应的功能处理外,还需要在这些事件点上做很多其他处理动作,比如发送短信通知、记录用户积分等等。我们可以将这些额外的处理动作放到每个模块中,但这并不是优雅的实现,不利于功能解耦和代码维护。
我们需要的是一个事件分发系统,在各个功能模块中将对应的事件发布出来,由对其感兴趣的处理者进行处理。这里涉及两个角色:A对B感兴趣,A是处理者,B是事件,由事件处理器完成二者的绑定,并向消息中心订阅事件。服务模块是后端的业务逻辑服务,在不同的事件点发布事件,事件经过消息中心分发给事件处理器对应的处理者。整个流程如下图所示。这边是典型的订阅发布模式。
可以看到,生产消费者模式与订阅发布模式都离不开消息中间件来作为消息中转站,开源的消息中间件有很多,各有优劣。本文将重点探讨RabbitMQ的特性,以及如何实现上述的两种场景。RabbitMQ核心概念 如果你只是想使用一下RabbitMQ,那么参考官方教程修改一下就可以跑起来了,很简单。如果你有一些概念上的疑惑,不妨与笔者一起来总结一下RabbitMQ的核心概念。通信方式
RabbitMQ是基于AMQP协议来实现的消息中间件。AMQP,类似于HTTP协议,也是一个应用层的协议,网络层使用TCP来通信。因此,RabbitMQ也是典型的C-S模型,准确地说是C-S-C模型,因为伴随着RabbitMQ的使用,总是会有Producer与Consumer两个Client和一个Broker Server。
Client要与Server进行通信,就必须先建立连接,RabbitMQ中有Connection与Channel两个概念,前者就是一个TCP连接,后者是在这个连接上的虚拟概念,负责逻辑上的数据传递,因此,为了节省资源,一般在一个客户端中建立一个Connection,每次使用时再分配一个Channel即可。
消息体
Message是RabbitMQ中的消息体概念。类似HTTP传输中,有header和body两部分数据,Message中也有Attributes和Payload两部分数据,前者是一些元信息,后者是传递的消息数据实体。
消息投递
Exchange、Queue与Routing Key三个概念是理解RabbitMQ消息投递的关键。RabbitMQ中一个核心的原则是,消息不能直接投递到Queue中。Producer只能将自己的消息投递到Exchange中,由Exchange按照routing_key投递到对应的Queue中,具体的架构参见下图。细细品味就会体会到这样设计的精妙之处。
那么,具体实现时,如何完成这三者关系的绑定?总结起来是两点:第一,在Consumer Worker中,声明自己对哪个Exchange感兴趣,并将自己的Queue绑定到自己感兴趣的一组routing_key上,建立相应的映射关系;第二,在Producer中,将消息投递一个Exchange中,并指明它的routing_key。由此可见,Queue这个概念只是对Consumer可见,Producer并不关心消息被投递到哪个Queue中。
看过RabbitMQ的”Hello World”教程的童鞋可能会发现在那里面的图中并没有看到Exchange和routing_key的踪迹,但这并不意味着RabbitMQ可以支持直接将消息投递到Queue中,而是在内部使用了默认的Exchange和routing_key了。默认情况下,RabbitMQ使用名称为“amq.direct”的Direct Exchange,routing_key默认名字与Queue保持一致。
搞清楚上述概念,就不难理解Exchange的四种类型了。Direct、Fanout、Topic、Headers,区别在于如何将消息从Exchange投递到Queue中。Direct使用具体的routing_key来投递;Fanout则忽略routing_key,直接广播给所有的Queue;Topic是使用模糊匹配来对一组routing_key进行投递;Headers也是忽略routing_key,使用消息中的Headers信息来投递。
消息可靠性
不同于HTTP的同步访问,RabbitMQ中,Producer并不知道消息是否被可靠地投递到了Consumer中处理。那么,RabbitMQ是如何保证消息的可靠投递?主要是两点:第一,消息确认机制。Consumer处理完消息后,需要发送确认消息给Broker Server,可以选择“确认接收”、“丢弃”、“重新投递”三种方式。如果Consumer在Broker Server收到确认消息之前挂了,Broker Server便会重新投递该消息。第二,可以选择数据持久化,这样即使RabbitMQ重启,也不会丢失消息。
生产消费者模式 搞清楚了RabbitMQ的核心概念,要针对特定的场景来设计使用方案就很简单了,基本上就是上述RabbitMQ架构图的变迁。让我们先来看看文章开头提到的“数据接入”场景,如何实现生产消费者模式。
这里增加了一下场景复杂度:对于上报的数据,如果是special的行为,需要优先处理。从上图可以看到,数据上报端负责将数据投递到RabbitMQ对应的Exchange,并指明routing_key是common还是special。数据处理端,可以根据情况启多个Woker来消费数据,但至少需要两个,一个用来处理common数据,一个用来处理special的数据。注意:当需要增加多个Worker来消费同一类数据时,需要保持Queue名字一致,比如上面的Common数据。订阅发布模式 再来看“事件分发”的场景,架构如下图所示,使用event name/id来作为RabbitMQ的routing key的名字。Event Processor 01对event 01 和event 02感兴趣,则在启动Consumer Worker时,将自己的Queue绑定到这两个routing key上即可,其他Event Processor也是如此,这样便完成了事件的订阅。当有事件发布时,消息便会按照event name/id被投递到对应的Queue中。
由此可见,在不同的应用中,变化的只是routing_key与Consumer Queue的绑定关系,在充分理解RabbitMQ的核心概念后处理这些应该也是得心应手了。
(全文完,本文地址:http://blog.csdn.net/zwgdft/article/details/53561277)
Bruce,2016/12/11

相关文章推荐
- RabbitMQ下的生产消费者模式与订阅发布模式
- RabbitMQ下的生产消费者模式与订阅发布模式
- RabbitMQ下的生产消费者模式与订阅发布模式
- Kafka下的生产消费者模式与订阅发布模式
- Kafka下的生产消费者模式与订阅发布模式
- RabbitMQ入门-发布订阅模式
- RabbitMQ五种消息队列学习(四)--发布订阅模式
- RabbitMQ消息分发模式----"Publish/Subscribe"发布/订阅模式
- RabbitMq六种使用模式(3)_订阅发布模式
- RabbitMQ 使用 | 第三篇:发布/订阅模式
- active mq 多个消费者实战(发布订阅模式)
- RabbitMQ消息分发模式----"Publish/Subscribe"发布/订阅模式
- .Net下RabbitMQ发布订阅模式实践
- 学习笔记_JavaSE_24-JDK1.5LOCK锁、生产消费者案例、线程池组、设计模式
- Java多线程学习笔记--生产消费者模式
- RabbitMQ/JAVA (发布/订阅模式)
- 分布式消息中间件(二)——ActiveMQ发布-订阅消息模式
- springboot结合redis实现redis订阅发布模式
- 观察者(发布订阅)模式 与 委托事件
- 3、RabbitMQ之消息发布订阅与信息持久化技术