分布式文件系统HDFS
2018-01-18 17:32
225 查看
1.什么是HDFS?
hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。源自于谷歌的GFS论文。发表于2003年,HDFS是GFS的克隆版。
2.HDFS的设计目标
(1)非常巨大的分布式文件系统
(2)运行在普通的廉价的硬件上
(3)易拓展,为用户提供性能不错的文件存储服务
3.HDFS架构
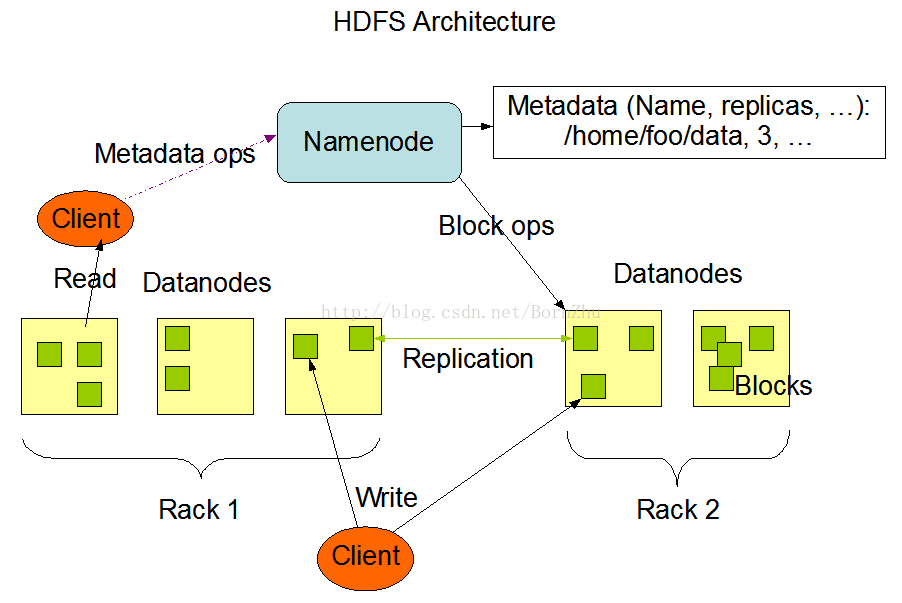
HDFS是Master/Slave架构。一个HDFS集群包括1个NameNode,也就是一个Master,和多个DataNode,也就是Slave。
在HDFS中,一个文件将会被拆分成多个Block(单位block大小,blocksize:128M),这些block被存储在一系列DataNodes上。
NameNode:(1)负责客户端请求的响应;(2)负责元数据(文件的名称、副本系数、Block存放的DataNode)的管理;
DataNode:(1)存储用户文件对应的Block;(2)定期向NameNode发送心跳信息,汇报自身及所有block信息,和健康状况;
比较典型的部署方式是集群内一台机器专门部署一个NameNode,其他机器部署DataNode。
4.HDFS的副本机制
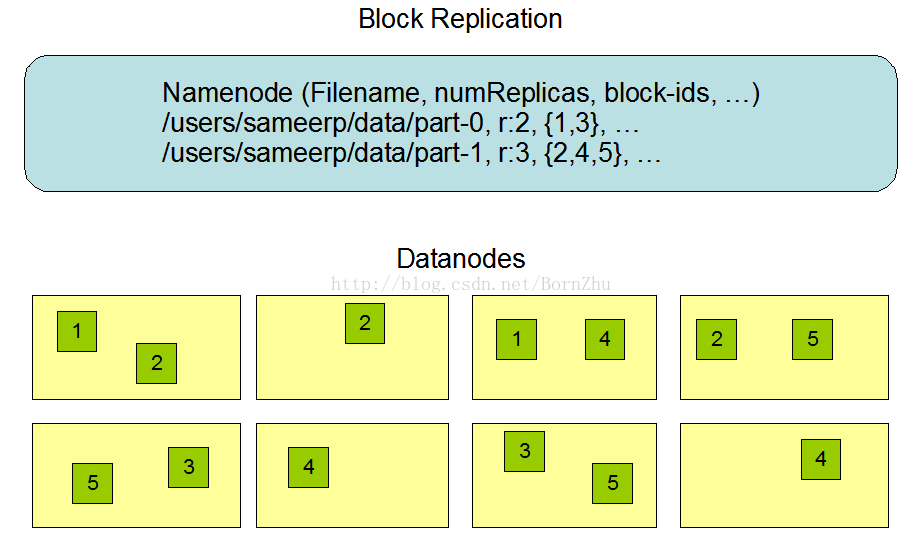
HDFS将每个文件存储为一系列block,除了最后一个block,其他的每个block的大小是相同的,block有许多副本用于增加容错性。每个
文件被分成的block大小和副本系数可以被配置,应用程序能够指定文件的副本数,副本系数在文件创建时即确定,同时也可以之后进
行改变,HDFS内的文件只能被写一次,并且同一时刻只能有一个writer。
NameNode管理block副本的复制,它定期的从DataNode接收心跳和blockreport。
黄色代表每一个机器,绿色就是block,可以看到每一个block有多个副本,副本数由NameNode决定。
5.HDFS的优缺点
优点:
(1)高容错
(2)适合批处理
(3)适合大数据处理
(4)构建在廉价的机构上
缺点:
(1)低延迟的数据访问
(2)不适合小文件储存
hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。源自于谷歌的GFS论文。发表于2003年,HDFS是GFS的克隆版。
2.HDFS的设计目标
(1)非常巨大的分布式文件系统
(2)运行在普通的廉价的硬件上
(3)易拓展,为用户提供性能不错的文件存储服务
3.HDFS架构
HDFS是Master/Slave架构。一个HDFS集群包括1个NameNode,也就是一个Master,和多个DataNode,也就是Slave。
在HDFS中,一个文件将会被拆分成多个Block(单位block大小,blocksize:128M),这些block被存储在一系列DataNodes上。
NameNode:(1)负责客户端请求的响应;(2)负责元数据(文件的名称、副本系数、Block存放的DataNode)的管理;
DataNode:(1)存储用户文件对应的Block;(2)定期向NameNode发送心跳信息,汇报自身及所有block信息,和健康状况;
比较典型的部署方式是集群内一台机器专门部署一个NameNode,其他机器部署DataNode。
4.HDFS的副本机制
HDFS将每个文件存储为一系列block,除了最后一个block,其他的每个block的大小是相同的,block有许多副本用于增加容错性。每个
文件被分成的block大小和副本系数可以被配置,应用程序能够指定文件的副本数,副本系数在文件创建时即确定,同时也可以之后进
行改变,HDFS内的文件只能被写一次,并且同一时刻只能有一个writer。
NameNode管理block副本的复制,它定期的从DataNode接收心跳和blockreport。
黄色代表每一个机器,绿色就是block,可以看到每一个block有多个副本,副本数由NameNode决定。
5.HDFS的优缺点
优点:
(1)高容错
(2)适合批处理
(3)适合大数据处理
(4)构建在廉价的机构上
缺点:
(1)低延迟的数据访问
(2)不适合小文件储存

相关文章推荐
- 分布式文件系统HDFS 之一
- hdfs:Hadoop分布式文件系统
- 从零开始学习Hadoop--第3章 HDFS分布式文件系统
- 第3周 分布式文件系统HDFS原理与操作
- 大数据时代之hadoop(四):hadoop 分布式文件系统(HDFS)
- HDFS分布式文件系统常用命令
- 利用libhdfs访问分布式文件系统(hdfs)
- Hadoop分布式文件系统(HDFS)
- HDFS分布式文件系统具有哪些优点?
- 分布式文件系统HDFS常用操作与设计原理
- HDFS分布式文件系统资源管理器开发总结
- Hadoop HDFS分布式文件系统设计要点与架构
- Hadoop分布式文件系统漫画详解HDFS Comics
- hdfs: 一个分布式文件系统(一)
- Python结合hdfs模块操作HDFS分布式文件系统
- 02-天亮大数据系统教程之分布式文件系统HDFS
- Hadoop分布式文件系统(HDFS)
- Hadoop分布式文件系统HDFS的安装
- hadoop知识点总结(二)hdfs分布式文件系统
- 【从零开始学习Hadoop】--2.HDFS分布式文件系统