[置顶] 全文搜索引擎Elasticsearch6.x 入门
2018-01-17 16:56
253 查看
全文搜索的需求非常大。而开源的解决办法Elasricsearch(Elastic)就是一个非常好的工具。目前是全文搜索引擎的首选。

Elastic 的底层是开源的Lucene。Elastic提供了REST API的操作接口。是Lucene的扩展。底层依旧是索引,但是可以把大索引切成n片,放到不同的节点,所以就实现了分布式。也就理所当然的是读写负载均衡。此外,他还是一个分布式实时文档存储,其中每个field可被搜索。
ES 可以自动将海量数据分布到多台服务器上去存储和检索海量数据。可以在秒级别在每台服务器上分析数据。
下面简单的介绍一下Elastic并且从零开始搭建一个Elastic。
(2).类型(type):类型是索引内部的逻辑分区。其意义完全取决与用户需求,一个索引内部可定义多个类型。类似于关系型数据库中的表结构,字段。
(3).文档(document):文档是Lucene索引和搜索的原子单位。它包含多个域。基于JSON格式存储。每个域的格式类似于字典
(4).映射(mapping):原始内容存储为文档之前的分析,映射就是定义此映射过程该如何实现。(例如切词,过滤)
集群组件:(1)Cluster:ES的集群标识为集群名称。默认为“elasticsearch”,节点靠此名字决定加入到哪一个集群中。一个节点只能属于一个集群。
(2).Node:运行单个ES实例的主机。节点的标识靠节点名。
(3).Shard:将索引切割成为的物理存储组件,但每一个shared都是一个独立且完整的索引,创建索引时,ES默认分割为5个shard。用户也可以按需自定义,创建完成后不可修改。shard有两种,primary和replica。用于负载均衡。
ES Cluster启动过程。通过多播(或单播)在9300/tcp查找同一集群中的其他节点,并建立通信。集群中所有节点会选举出一个主节点负责管理整个集群状态。以及在集群范围内决定shared的分布。
这里也简单的演示一下JAVA的环境配置。首先准备好jdk的tar包。下载网页
若出现 -bash: /usr/java/jdk1.8.0_151/bin/java: /lib/ld-linux.so.2: bad ELF interpreter: 没有那个文件或目录 这个错误, 则执行 yum install glibc.i686 即可。
至此,安装成功jdk。下来安装Elasticsearch。下载页面
下载好rpm包。执行
启动Elasticsearch。
接下来修改配置文件。
启动后,发现9200,9300端口处于监听状态。 如果发现,network.host不能绑定到0.0.0.0上。(一启动就出错,则可能的原因如下)

接下来给其余的两个节点同样的步骤安装Elasticsearch。
(1) Near RealTime(NRT):近实时。基于es的搜索在秒级别。
(2) Index (索引):包含一堆相似结构的文档数据。比如客户索引,商品索引,订单索引,索引有一个名称,一个index包含很多个document。
(3) Documents (文档): es的最小数据单元。一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常是JSON数据表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field。每个field就是一个数据字段。
(4) Type (类型):每个索引里有一个或者多个type。type是index中的一个逻辑数据分类。一个type下的document都有相同的field。
比如商品index。里面存放了所有的商品数据。商品document。但商品的种类很多。每个种类的document的field可能不太一样。比如电器商品和生鲜商品。(生鲜商品type,电器商品type,日化商品type)
日化商品type:id ,product_name ,product_desc,category_id,category_name
电器商品type:id ,product_name ,product_desc,category_id,category_name,service_period
生鲜商品type:id ,product_name ,product_desc,category_id,category_name,eat_period
然后每一个type内又有一堆的document。就不举例了。
(5) Shard:单台服务器无法存储大量的数据,es可以将一个索引中的数据分为多个shard。分布在很多台服务器上,有了shard就实现了横向扩展。存储更多的数据。让搜索和分析操作分布到多台服务器上去执行。
(6) replica:为了防止某一台服务器上的shard丢失。因此可以为每个shared创建多个replica副本。多个replica可以提升搜索操作的吞吐和性能。primary shard(建立索引时一次性建立,默认5个)replica shard(随时修改,默认一个)。
下图详细的介绍了 shard和replica。

这些命令是es的插件,日志等管理工具。plugins 是放es相关插件的。
接下来下载和安装解压缩Kibana。使用里面的开发界面,去操作Elasticsearch。
安装完成后、可简单修改其配置文件 /etc/kibana/kibana.yml 改变其监听端口(默认是localhost)。
通过 systemctl start kibana 启动。而后通过浏览器访问。
之后就可以通过kibana 的dev tool去操作

集群状态:
green: 每个索引的primary shard和replica shard 都是active状态
yellow:每个索引的primary shard 都是active 但是 部分索引的replica不是active的
red:有部分索引的primary shard 不是active的。
(1)、查看集群中都有哪些索引。
(2)、创建索引。
(3)、删除索引。
(1)、对商品进行CRUD(增删改查)操作
(2)、执行简单的结构化查询
(3)、可以执行全文检索,以及复杂的phrase(短语)检索
(4)、对于全文检索内容可以进行高亮显示
(5)、对数据进行局和分析
一、新增商品,新增文档,新增索引。
二、检索商品。
三、修改,替换商品
可以直接替换,也可以修改。
四、删除商品
查询结果:
took: 消耗了几毫秒。
timed_out:是否超时
_shards:数据拆分成了5个分片。所以对于搜索请求。会打到所有的primary shard 或 replica shard
hits.total:查询结果的数量。2个
hits.max_score:score的含义,就是document对于一个search相关度的分配分数。越相关,就越匹配。
查询名字里带 xiaomi 的商品。
分页查询商品,总共3条商品。假设每页就显示一条。现在显示第2页。
只查出名称和价格
查出商品包含xiaomi且价格大于2000元的。
短语搜索,与全文搜索相对应。短语搜索是必须匹配。
搜索高亮显示。
更多详细的查询语法或其他内容
Text-to-speech function is limited to 200 characters
Elastic 的底层是开源的Lucene。Elastic提供了REST API的操作接口。是Lucene的扩展。底层依旧是索引,但是可以把大索引切成n片,放到不同的节点,所以就实现了分布式。也就理所当然的是读写负载均衡。此外,他还是一个分布式实时文档存储,其中每个field可被搜索。
ES 可以自动将海量数据分布到多台服务器上去存储和检索海量数据。可以在秒级别在每台服务器上分析数据。
下面简单的介绍一下Elastic并且从零开始搭建一个Elastic。
一、简介
基本组件: (1).索引(index):文档容器,类似于关系型数据库中的库。索引名必须是小写字母。(2).类型(type):类型是索引内部的逻辑分区。其意义完全取决与用户需求,一个索引内部可定义多个类型。类似于关系型数据库中的表结构,字段。
(3).文档(document):文档是Lucene索引和搜索的原子单位。它包含多个域。基于JSON格式存储。每个域的格式类似于字典
(4).映射(mapping):原始内容存储为文档之前的分析,映射就是定义此映射过程该如何实现。(例如切词,过滤)
集群组件:(1)Cluster:ES的集群标识为集群名称。默认为“elasticsearch”,节点靠此名字决定加入到哪一个集群中。一个节点只能属于一个集群。
(2).Node:运行单个ES实例的主机。节点的标识靠节点名。
(3).Shard:将索引切割成为的物理存储组件,但每一个shared都是一个独立且完整的索引,创建索引时,ES默认分割为5个shard。用户也可以按需自定义,创建完成后不可修改。shard有两种,primary和replica。用于负载均衡。
ES Cluster启动过程。通过多播(或单播)在9300/tcp查找同一集群中的其他节点,并建立通信。集群中所有节点会选举出一个主节点负责管理整个集群状态。以及在集群范围内决定shared的分布。
二、安装
安装环境 Linux centos7.3 3台. 直接就安装成集群。Elastic 的安装需要Java环境。不会配置Java环境的请参考这篇文章这里也简单的演示一下JAVA的环境配置。首先准备好jdk的tar包。下载网页
# mkdir /usr/java # tar xf jdk-8u151-linux-i586.tar.gz -C /usr/java # vim /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_151 export JRE_HOME=/usr/java/jdk1.8.0_151/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
# update-alternatives --install /usr/bin/java java /usr/java/jdk1.8.0_151/bin/java 300 # update-alternatives --install /usr/bin/javac javac /usr/java/jdk1.8.0_151/bin/javac 300 # update-alternatives --config java 共有 3 个程序提供“java”。 选择 命令 ----------------------------------------------- *+ 1 /usr/lib/jvm/jre-1.7.0-openjdk.x86_64/bin/java 2 /usr/lib/jvm/jre-1.6.0-openjdk.x86_64/bin/java 3 /usr/java/jdk1.8.0_151/bin/java 按 Enter 来保存当前选择[+],或键入选择号码:3
若出现 -bash: /usr/java/jdk1.8.0_151/bin/java: /lib/ld-linux.so.2: bad ELF interpreter: 没有那个文件或目录 这个错误, 则执行 yum install glibc.i686 即可。
至此,安装成功jdk。下来安装Elasticsearch。下载页面
下载好rpm包。执行
# rpm -ivh elasticsearch-6.1.1.rpm warning: elasticsearch-6.1.1.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY Preparing... ########################################### [100%] Creating elasticsearch group... OK Creating elasticsearch user... OK 1:elasticsearch ########################################### [100%] ### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using chkconfig sudo chkconfig --add elasticsearch ### You can start elasticsearch service by executing sudo service elasticsearch start
启动Elasticsearch。
# systemctl start elasticsearch
接下来修改配置文件。
# vim /etc/elasticsearch/elasticsearch.yml cluster.name: my-elastic # 集群名字,相同集群名字的节点会放到同一个集群下 node.name: "node-1" # 节点名字 discovery.zen.minimum_master_nodes: 2 #指定集群中的节点中有几个有master资格的节点。 #对于大集群可以写3个以上。 discovery.zen.ping.timeout: 3s #默认是3s,这是设置集群中自动发现其它节点时ping连接超时时间 discovery.zen.ping.multicast.enabled: false #设置是否打开多播发现节点,默认是true。 network.bind_host: 192.168.40.129 #设置绑定的ip地址,这是我的虚拟机的IP。 network.publish_host: 192.168.40.129 #设置其它节点和该节点交互的ip地址。 network.host: 0.0.0.0 #同时设置bind_host和publish_host上面两个参数。 transport.tcp.port: 9300 #设置参与集群的端口 http.port: 9200 #接收请求端口 #discovery.zen.ping.unicast.hosts:["节点1的 ip","节点2 的ip","节点3的ip"] #指明集群中其它可能为master的节点ip,以防es启动后发现不了集群中的其他节点。
启动后,发现9200,9300端口处于监听状态。 如果发现,network.host不能绑定到0.0.0.0上。(一启动就出错,则可能的原因如下)
接下来给其余的两个节点同样的步骤安装Elasticsearch。
三、核心概念
首先,elasticsearch 是基于lucene开发,lucene的开发十分复杂,api复杂(需要大量的java代码才能完成一个简单的功能)。(1) Near RealTime(NRT):近实时。基于es的搜索在秒级别。
(2) Index (索引):包含一堆相似结构的文档数据。比如客户索引,商品索引,订单索引,索引有一个名称,一个index包含很多个document。
(3) Documents (文档): es的最小数据单元。一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常是JSON数据表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field。每个field就是一个数据字段。
{
"id" : "qWAEoJU",
"product_name" : "蒂花之秀",
"product_desc" : "乌黑亮丽",
"category" : "2",
"category_name" : "日化用品"
}(4) Type (类型):每个索引里有一个或者多个type。type是index中的一个逻辑数据分类。一个type下的document都有相同的field。
比如商品index。里面存放了所有的商品数据。商品document。但商品的种类很多。每个种类的document的field可能不太一样。比如电器商品和生鲜商品。(生鲜商品type,电器商品type,日化商品type)
日化商品type:id ,product_name ,product_desc,category_id,category_name
电器商品type:id ,product_name ,product_desc,category_id,category_name,service_period
生鲜商品type:id ,product_name ,product_desc,category_id,category_name,eat_period
然后每一个type内又有一堆的document。就不举例了。
(5) Shard:单台服务器无法存储大量的数据,es可以将一个索引中的数据分为多个shard。分布在很多台服务器上,有了shard就实现了横向扩展。存储更多的数据。让搜索和分析操作分布到多台服务器上去执行。
(6) replica:为了防止某一台服务器上的shard丢失。因此可以为每个shared创建多个replica副本。多个replica可以提升搜索操作的吞吐和性能。primary shard(建立索引时一次性建立,默认5个)replica shard(随时修改,默认一个)。
下图详细的介绍了 shard和replica。
四、安装后相关简介
通过rpm包安装之后。会安装上很多的文件。除了/etc/elasticsearch 下的配置文件外,还有很多。# pwd /usr/share/elasticsearch/bin # ls elasticsearch elasticsearch-env elasticsearch-keystore elasticsearch-plugin elasticsearch-translog
这些命令是es的插件,日志等管理工具。plugins 是放es相关插件的。
接下来下载和安装解压缩Kibana。使用里面的开发界面,去操作Elasticsearch。
# yum -y install kibana-6.1.1-x86_64.rpm
安装完成后、可简单修改其配置文件 /etc/kibana/kibana.yml 改变其监听端口(默认是localhost)。
通过 systemctl start kibana 启动。而后通过浏览器访问。
之后就可以通过kibana 的dev tool去操作
集群状态:
green: 每个索引的primary shard和replica shard 都是active状态
yellow:每个索引的primary shard 都是active 但是 部分索引的replica不是active的
red:有部分索引的primary shard 不是active的。
五、简单操作
索引操作(1)、查看集群中都有哪些索引。
curl -X GET localhost:9200/_cat/indices
(2)、创建索引。
# curl -X PUT localhost:9200/test_index?pretty
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test_index"
}(3)、删除索引。
# curl -X DELETE localhost:9200/test_index?pretty
{
"acknowledged" : true
}六、入门案例实战
模拟场景:电商网站。需要基于ES构建的后台系统。提供以下功能。(1)、对商品进行CRUD(增删改查)操作
(2)、执行简单的结构化查询
(3)、可以执行全文检索,以及复杂的phrase(短语)检索
(4)、对于全文检索内容可以进行高亮显示
(5)、对数据进行局和分析
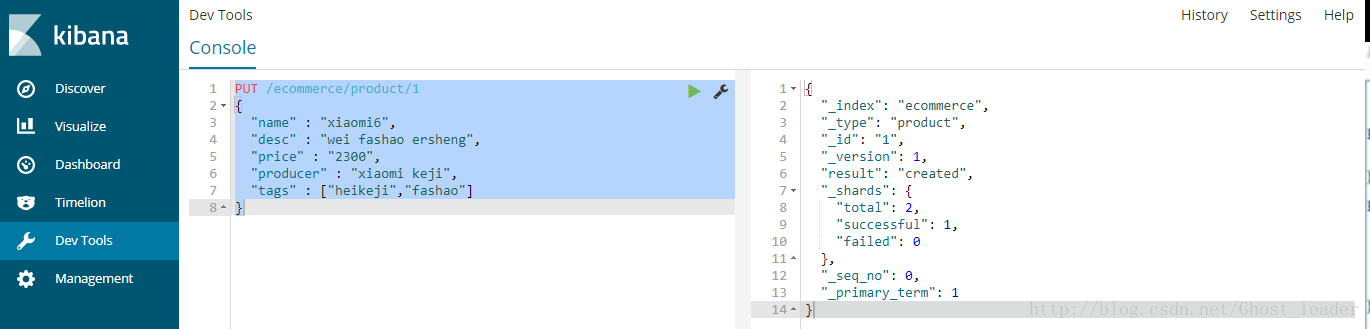
一、新增商品,新增文档,新增索引。
PUT /ecommerce/product/1
{
"name" : "xiaomi6",
"desc" : "wei fashao ersheng",
"price" : "2300",
"producer" : "xiaomi keji",
"tags" : ["heikeji","fashao"]
}PUT /ecommerce/product/2
{
"name" : "iphoneX",
"desc" : "gaoduan daqi",
"price" : "8300",
"producer" : "apple",
"tags" : ["qianwei","shishang"]
}二、检索商品。
# curl -XGET localhost:9200/ecommerce/product/1
{"_index":"ecommerce","_type":"product","_id":"1","_version":1,"found":true,"_source":{
"name" : "xiaomi6",
"desc" : "wei fashao ersheng",
"price" : "2300",
"producer" : "xiaomi keji",
"tags" : ["heikeji","fashao"]
}三、修改,替换商品
可以直接替换,也可以修改。
POST /ecommerce/product/1/_update
{
"doc":{
"price": "2400"
}
}四、删除商品
DELETE /ecommerce/product/1
高级操作
搜索所有的商品。GET ecommerce/product/_search
查询结果:
took: 消耗了几毫秒。
timed_out:是否超时
_shards:数据拆分成了5个分片。所以对于搜索请求。会打到所有的primary shard 或 replica shard
hits.total:查询结果的数量。2个
hits.max_score:score的含义,就是document对于一个search相关度的分配分数。越相关,就越匹配。
{
"took": 90,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 1,
"_source": {
"name": "iphoneX",
"desc": "gaoduan daqi",
"price": "8300",
"producer": "apple",
"tags": [
"qianwei",
"shishang"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_score": 1,
"_source": {
"name": "xiaomi6",
"desc": "wei fashao ersheng",
"price": "2400",
"producer": "xiaomi keji",
"tags": [
"heikeji",
"fashao"
]
}
}
]
}
}查询名字里带 xiaomi 的商品。
GET /ecommerce/product/_search?q=name:xiaomi
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"name" :"xiaomi"
}
}
}分页查询商品,总共3条商品。假设每页就显示一条。现在显示第2页。
GET ecommerce/product/_search
{
"query":{
"match_all": {}},
"from":1,
"size":1
}只查出名称和价格
GET ecommerce/product/_search
{
"query":{
"match_all": {}
},
"_source": ["name","price"]
}查出商品包含xiaomi且价格大于2000元的。
GET ecommerce/product/_search
{
"query":{
"bool":{
"must":{
"match":{
"name":"xiaomi"
}
},
"filter":{
"range":{
"price":{
"gt": 2000
}
}
}
}
}
}短语搜索,与全文搜索相对应。短语搜索是必须匹配。
GET ecommerce/product/_search
{
"query":{
"match_phrase":{
"producer": "keji"
}
}
}搜索高亮显示。
GET ecommerce/product/_search
{
"query":{
"match":{
"producer": "keji"
}
},
"highlight": {
"fields": {
"producer": {}
}
}
}更多详细的查询语法或其他内容
| Detect languageAfrikaansAlbanian ArabicArmenian AzerbaijaniBasqueBelarusian BengaliBosnian BulgarianCatalanCebuano ChichewaChinese (Simplified) Chinese (Traditional)Croatian CzechDanishDutch EnglishEsperantoEstonian FilipinoFinnishFrench GalicianGeorgianGerman GreekGujaratiHaitian Creole HausaHebrew HindiHmongHungarian IcelandicIgboIndonesian IrishItalianJapanese JavaneseKannadaKazakh KhmerKoreanLao LatinLatvianLithuanian MacedonianMalagasyMalay MalayalamMalteseMaori MarathiMongolianMyanmar (Burmese) NepaliNorwegian PersianPolishPortuguese PunjabiRomanianRussian SerbianSesothoSinhala SlovakSlovenianSomali SpanishSundaneseSwahili SwedishTajikTamil TeluguThaiTurkish UkrainianUrduUzbek VietnameseWelshYiddish YorubaZulu | AfrikaansAlbanianArabic ArmenianAzerbaijaniBasque BelarusianBengali BosnianBulgarianCatalan CebuanoChichewaChinese (Simplified) Chinese (Traditional)Croatian CzechDanish DutchEnglish EsperantoEstonianFilipino FinnishFrench GalicianGeorgianGerman GreekGujaratiHaitian Creole HausaHebrew HindiHmongHungarian IcelandicIgboIndonesian IrishItalianJapanese JavaneseKannadaKazakh KhmerKoreanLao LatinLatvianLithuanian MacedonianMalagasyMalay MalayalamMalteseMaori MarathiMongolianMyanmar (Burmese) NepaliNorwegian PersianPolishPortuguese PunjabiRomanianRussian SerbianSesothoSinhala SlovakSlovenianSomali SpanishSundaneseSwahili SwedishTajikTamil TeluguThaiTurkish UkrainianUrduUzbek VietnameseWelshYiddish YorubaZulu |
| Options :History :Feedback :Donate | Close |

相关文章推荐
- 全文搜索引擎Elasticsearch入门教程
- 全文搜索引擎Elasticsearch入门教程
- 全文搜索引擎Elasticsearch入门教程
- 【Elasticsearch全文搜索引擎实战】之Filebeat快速入门
- ElasticSearch入门 - 分布式安装
- [置顶] Python 入门指南
- [置顶] ActiveMQ入门教程(一) - JMS和ActiveMQ简介
- Elasticsearch 数据搜索篇·【入门级干货】
- ElasticSearch入门之花落红尘(三)
- [置顶] Hystrix限流,熔断,降级入门
- [置顶] Spring Boot RabbitMQ 入门(四)之 Topic交换器
- [置顶] 【Git入门之九】解决冲突
- Elasticsearch v2.2 快速入门(含curl,Sense,python 3种客户端方式)
- ElasticSearch学习13_ElasticSearch RESTful搜索引擎_Java Jest使用入门
- 5.1 入门整合案例(SpringBoot+Spring-data-elasticsearch) ---- good
- ElasticSearch 简单入门
- [置顶] Elasticsearch实践(一)用Docker搭建Elasticsearch集群
- [置顶] 高效前端优化工具--Fiddler入门教程
- Elasticsearch 全教程--入门