一:基于spark计算框架下的带容量约束的车辆路径问题并行算法研究
2018-01-16 15:53
99 查看
Spark 分布式实现
1. Spark中各节点的功能:
Master节点:Solution Pool的存储、种群的划分、更新Soultion Pool和异常处理。Slave节点:进行算法计算的到一个最优解。
RDD:进行数据的存储,包括节点信息的存储目的是确保每个节点都得到一个初始解。
2. 论文中RDD的描述
首先,生成多个禁忌搜索节点进行搜索,然后将搜索到的最优解以集合的形式发送给Solution Pool。并将一半的节点数设置为导向性搜索节点,另一半为多样性搜索节点,并且通过不同的算法从Solution Pool中得到初始解。每个禁忌搜索节点抽象化一个RDD(TabuRDD)。一些相关要求如下:Spark调度时尽可能给每个分块一个CPU;
尽量每个TS节点用一个核计算;
每个TS节点设置相同的迭代次数。
自己的观点:前两个要求是为了在同一个节点的计算能够实现信息的共享,最后一个是为了缩短每个节点计算完成时相互等待的时间。
3. 并发算法Spark实现方式:
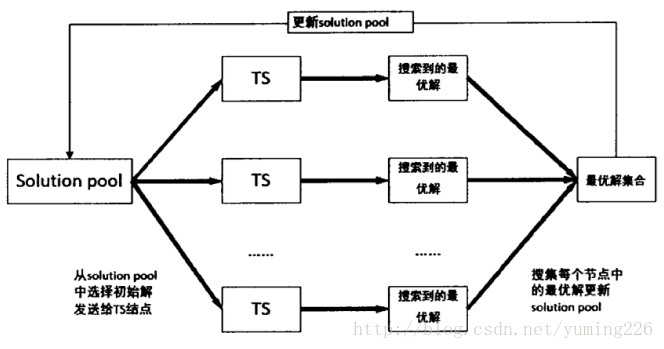
RDD的每次迭代:
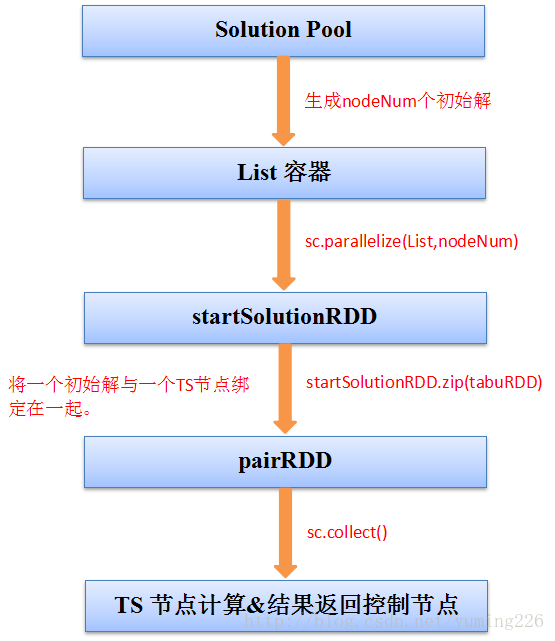
其中startSoultionRDD和pairRDD具有相同的分区数,在进行键值对转化时它们的分区是一一对应的。通过Collect函数将每个tabuRDD中搜索到的最好解收集起来发给Solution Pool。
细节说明:
在程序刚开始的时候将Solution Pool中生成的初始解根据分类算法形成不同的种群。在位tabuRDD选择初始解时是按照固定的算法来选择的,因为每个初始解只能被选择一次,所以每次的初始解都是不一样的。
每个禁忌搜索节点的参数不是完全相同的。
每次迭代的得到的最优解都会按照分类算法进入Solution Pool的不同种群中,同时更新Solution Pool中的每个参数。

相关文章推荐
- 基于案例贯通 Spark Streaming 流计算框架的运行源码
- 基于spark的图计算框架GraphX
- 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- Spark定制班第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- (版本定制)第5课:基于案例分析Spark Streaming流计算框架的运行源码
- 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- 基于案例贯通Spark Streaming流计算框架的运行源码
- 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- [置顶] 基于遗传算法求解车辆路径问题
- 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码(Spark streaming源代码导入IDEA)
- [置顶] 基于遗传算法求解车辆路径问题
- 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- Spark 介绍(基于内存计算的大数据并行计算框架)
- Spark 介绍(基于内存计算的大数据并行计算框架)
- 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- 版本定制第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码
- Spark定制班第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码