经典的文本数据预处理流程
2018-01-15 11:00
204 查看
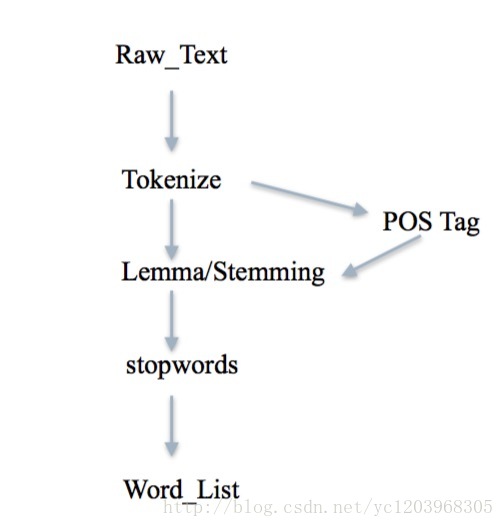
首先对文本进行分词,因为可以直接用NLTK的分词器,中文的可以用结巴分词
在英文中,往往还需要对单词进行词干提取和词形归一化。在词形归一的过程中如果结合POS Tag可以更好的进行词形归一。
去除停用词,得到最终的词列表

相关文章推荐
- 如何将多个文本数据转化为指定数据格式[以电影数据为例](数据预处理)
- 中文文本挖掘预处理流程总结
- 数据挖掘 NLP 之 文本挖掘 文本处理 通用流程
- 文本数据预处理:sklearn 中 CountVectorizer、TfidfTransformer
- 文本分类的数据预处理流程介绍
- 中文文本挖掘预处理流程总结
- 几种简单的文本数据预处理方法
- 文本挖掘预处理的流程总结
- Pytorch入门学习(六)--- 加载数据以及预处理(初步)--- 只为了更好理解流程
- 文本挖掘预处理的流程总结
- 文本挖掘—搜狗语料库数据预处理
- 数据挖掘之文本分类的数据预处理
- 以虎嗅网4W+文章的文本挖掘为例,展现数据分析的一整套流程
- 文本内容分析和智能反馈(2)- 数据预处理和按纬度统计
- 文本数据预处理:sklearn中CountVectorizer、TfidfTransformer和TfidfVectorizer
- 英文文本挖掘预处理流程总结
- 中文文本挖掘预处理流程
- 文本数据预处理系统软件
- 英文文本挖掘预处理流程总结
- 基于FSL的DTI数据预处理流程