部署kube-prometheus,添加邮件报警
2018-01-14 17:35
876 查看
这个项目出自coreos,已经存在很久了,第一次尝试的时候还很简陋,现在完善了很多。
项目提供了一键部署脚本,跑起来并不难,不过个人感觉要真正掌握并灵活使用并不是很容易。
kube version: 1.9.1
OS version: debian stretch
1、从github上把项目拉下来。
项目提供了一键部署脚本,跑起来并不难,不过个人感觉要真正掌握并灵活使用并不是很容易。
kube version: 1.9.1
OS version: debian stretch
1、从github上把项目拉下来。
# git clone https://github.com/coreos/prometheus-operator.git[/code] 2、准备镜像,这里用到了墙外的镜像,自行科学下载。quay.io/prometheus/alertmanager:v0.9.1 quay.io/coreos/configmap-reload:v0.0.1 grafana/grafana:4.5.2 quay.io/coreos/grafana-watcher:v0.0.8 quay.io/coreos/kube-state-metrics:v1.0.1 gcr.io/google_containers/addon-resizer:1.0 quay.io/prometheus/node-exporter:v0.15.0 quay.io/prometheus/prometheus:v2.0.0 quay.io/coreos/prometheus-config-reloader:v0.0.2 quay.io/coreos/prometheus-operator:v0.15.0
3、执行脚本部署项目。
脚本内容如下:#!/usr/bin/env bash if [ -z "${KUBECONFIG}" ]; then export KUBECONFIG=~/.kube/config fi # CAUTION - setting NAMESPACE will deploy most components to the given namespace # however some are hardcoded to 'monitoring'. Only use if you have reviewed all manifests. if [ -z "${NAMESPACE}" ]; then NAMESPACE=monitoring fi kubectl create namespace "$NAMESPACE" kctl() { kubectl --namespace "$NAMESPACE" "$@" } kctl apply -f manifests/prometheus-operator # Wait for CRDs to be ready. printf "Waiting for Operator to register custom resource definitions..." until kctl get customresourcedefinitions servicemonitors.monitoring.coreos.com > /dev/null 2>&1; do sleep 1; printf "."; done until kctl get customresourcedefinitions prometheuses.monitoring.coreos.com > /dev/null 2>&1; do sleep 1; printf "."; done until kctl get customresourcedefinitions alertmanagers.monitoring.coreos.com > /dev/null 2>&1; do sleep 1; printf "."; done until kctl get servicemonitors.monitoring.coreos.com > /dev/null 2>&1; do sleep 1; printf "."; done until kctl get prometheuses.monitoring.coreos.com > /dev/null 2>&1; do sleep 1; printf "."; done until kctl get alertmanagers.monitoring.coreos.com > /dev/null 2>&1; do sleep 1; printf "."; done echo "done!" kctl apply -f manifests/node-exporter kctl apply -f manifests/kube-state-metrics kctl apply -f manifests/grafana/grafana-credentials.yaml kctl apply -f manifests/grafana find manifests/prometheus -type f ! -name prometheus-k8s-roles.yaml ! -name prometheus-k8s-role-bindings.yaml -exec kubectl --namespace "$NAMESPACE" apply -f {} \; kubectl apply -f manifests/prometheus/prometheus-k8s-roles.yaml kubectl apply -f manifests/prometheus/prometheus-k8s-role-bindings.yaml kctl apply -f manifests/alertmanager/
从脚本上看,其实很简单,有木有..# cd contrib/kube-prometheus/ # hack/cluster-monitoring/deploy namespace "monitoring" created clusterrolebinding "prometheus-operator" created clusterrole "prometheus-operator" created serviceaccount "prometheus-operator" created service "prometheus-operator" created deployment "prometheus-operator" created Waiting for Operator to register custom resource definitions......done! daemonset "node-exporter" created service "node-exporter" created clusterrolebinding "kube-state-metrics" created clusterrole "kube-state-metrics" created deployment "kube-state-metrics" created rolebinding "kube-state-metrics" created role "kube-state-metrics-resizer" created serviceaccount "kube-state-metrics" created service "kube-state-metrics" created secret "grafana-credentials" created secret "grafana-credentials" unchanged configmap "grafana-dashboards-0" created deployment "grafana" created service "grafana" created servicemonitor "alertmanager" created servicemonitor "prometheus-operator" created prometheus "k8s" created servicemonitor "kubelet" created servicemonitor "prometheus" created service "prometheus-k8s" created servicemonitor "node-exporter" created servicemonitor "kube-scheduler" created servicemonitor "kube-controller-manager" created servicemonitor "kube-state-metrics" created configmap "prometheus-k8s-rules" created serviceaccount "prometheus-k8s" created servicemonitor "kube-apiserver" created role "prometheus-k8s" created role "prometheus-k8s" created role "prometheus-k8s" created clusterrole "prometheus-k8s" created rolebinding "prometheus-k8s" created rolebinding "prometheus-k8s" created rolebinding "prometheus-k8s" created clusterrolebinding "prometheus-k8s" created secret "alertmanager-main" created service "alertmanager-main" created alertmanager "main" created
4、由于事先准备好了镜像,很快就运行起来了。# kubectl get po -n monitoring NAME READY STATUS RESTARTS AGE alertmanager-main-0 2/2 Running 0 11h alertmanager-main-1 2/2 Running 0 11h alertmanager-main-2 2/2 Running 0 11h grafana-6b67b479d5-2hhnp 2/2 Running 0 11h kube-state-metrics-6f7b5c94f-r8hm7 2/2 Running 0 11h node-exporter-27744 1/1 Running 0 11h node-exporter-9vhlv 1/1 Running 0 11h node-exporter-rhjfb 1/1 Running 0 11h node-exporter-xpqr8 1/1 Running 0 11h prometheus-k8s-0 2/2 Running 0 11h prometheus-k8s-1 2/2 Running 0 11h prometheus-operator-8697c7fff9-mm8v5 1/1 Running 0 11h
这里曝光了三个服务:
Prometheus UI on node port30900
Alertmanager UI on node port30903
Grafana on node port30902
通过相应地端口就能访问对应的服务。
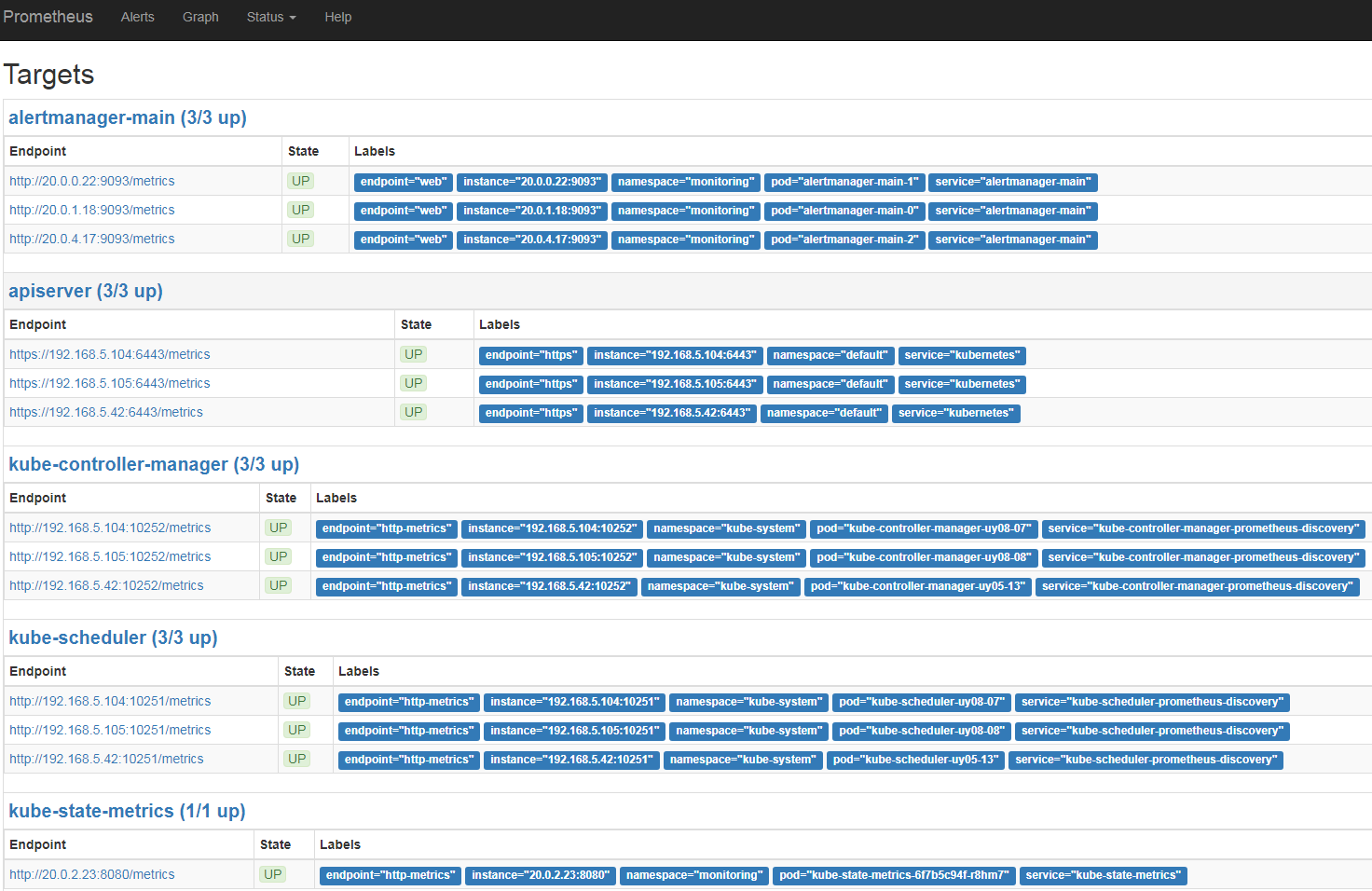
5、添加controller-manager和scheduler的监控。# kubectl apply -f -f manifests/k8s/ -n kube-system
这里其实是添加了2个service,注意namespace是kube-system,而不是monitoring:# kubectl get ep -n kube-system | grep discovery kube-controller-manager-prometheus-discovery 192.168.5.104:10252,192.168.5.105:10252,192.168.5.42:10252 3d kube-scheduler-prometheus-discovery 192.168.5.104:10251,192.168.5.105:10251,192.168.5.42:10251 3d
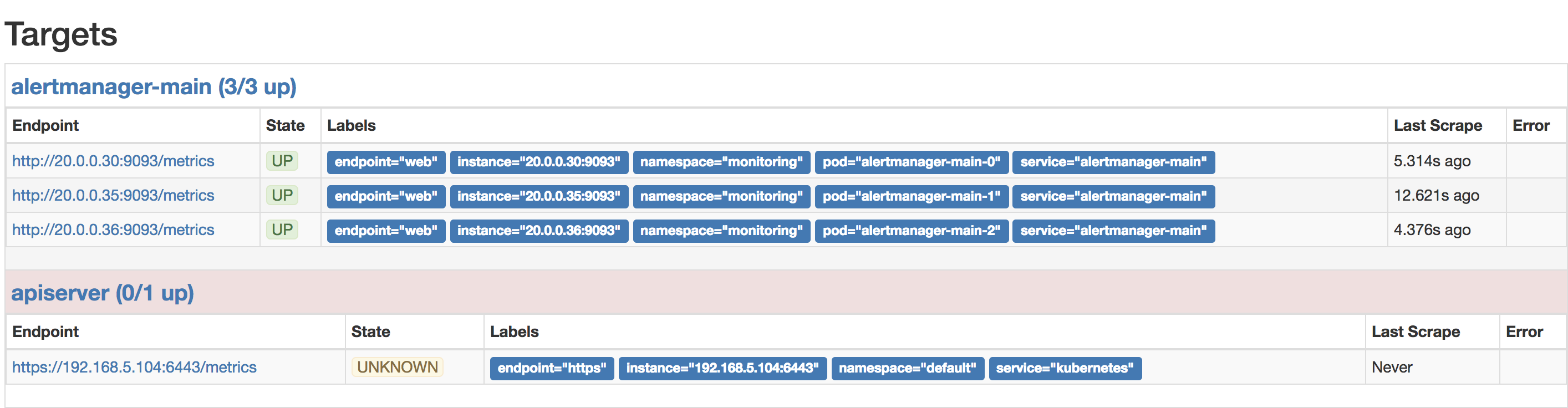
6、由于我的kubernetes是高可用架构,有三个apiserver,这里有个bug有个需要处理。apiserver是无状态的,三个endpoint会自身冲突,需要是在kubernetes1.9以上,通过给apiserver传递一个参数--endpoint-reconciler-type=lease解决该问题。
默认是这个样子:
解决完是这个样子:
7、添加邮件报警规则。这个配置是用base64加密过的。# vim manifests/alertmanager/alertmanager-config.yaml apiVersion: v1 kind: Secret metadata: name: alertmanager-main data: alertmanager.yaml: Z2xvYmFsOgogIHJlc29sdmVfdGltZW91dDogNW0KICBzbXRwX3NtYXJ0aG9zdDogIm1haWwub3VwZW5nLmNvbToyNSIKICBzbXRwX2Zyb206ICJuYWdpb3NfbW9uaXRvckBvdXBlbmcuY29tIgogIHNtdHBfYXV0aF91c2VybmFtZTogIm5hZ2lvc19tb25pdG9yQG91cGVuZy5jb20iCiAgc210cF9hdXRoX3Bhc3N3b3JkOiAiZGVsbGRlbGwiCnJvdXRlOgogIGdyb3VwX2J5OiBbJ2FsZXJ0bmFtZScsICdjbHVzdGVyJywgJ3NlcnZpY2UnXQogIGdyb3VwX3dhaXQ6IDMwcwogIGdyb3VwX2ludGVydmFsOiA1bQogIHJlcGVhdF9pbnRlcnZhbDogM2gKICByZWNlaXZlcjogdGVhbS1YLW1haWxzCiAgcm91dGVzOgogIC0gbWF0Y2hfcmU6CiAgICAgIGFsZXJ0bmFtZTogXihob3N0X2NwdV91c2FnZXxub2RlX2ZpbGVzeXN0ZW1fZnJlZXxob3N0X2Rvd24pJAogICAgcmVjZWl2ZXI6IHRlYW0tWC1tYWlscwogICAgcm91dGVzOgogICAgLSBtYXRjaDoKICAgICAgICBzZXZlcml0eTogY3JpdGljYWwKICAgICAgcmVjZWl2ZXI6IHRlYW0tWC1tYWlscwpyZWNlaXZlcnM6Ci0gbmFtZTogInRlYW0tWC1tYWlscyIKICBlbWFpbF9jb25maWdzOgogIC0gdG86ICJuaG9yaXpvbi1zYUBvdXBlbmcuY29tIgo=
要拿到配置内容,用base64反解一下就可以了,默认配置是这样:# echo "加密的内容" | base64 -d global: resolve_timeout: 5m route: group_by: ['job'] group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: 'null' routes: - match: alertname: DeadMansSwitch receiver: 'null' receivers: - name: 'null'
添加自己的邮件设置:global: resolve_timeout: 5m smtp_smarthost: "mail.xxxx.com:25" smtp_from: "example@xxxx.com" smtp_auth_username: "expample@xxxx.com" smtp_auth_password: "pass" route: group_by: ['alertname', 'cluster', 'service'] group_wait: 30s group_interval: 5m repeat_interval: 15m receiver: team-X-mails routes: - match_re: alertname: ^(host_cpu_usage|node_filesystem_free|host_down)$ receiver: team-X-mails routes: - match: severity: critical receiver: team-X-mails receivers: - name: "team-X-mails" email_configs: - to: "example@xxxx.com"
定义好之后,用base64加密一下,替换掉之前的地方。然后应用配置:# kubectl apply -f manifests/alertmanager/alertmanager-config.yaml -n monitoring
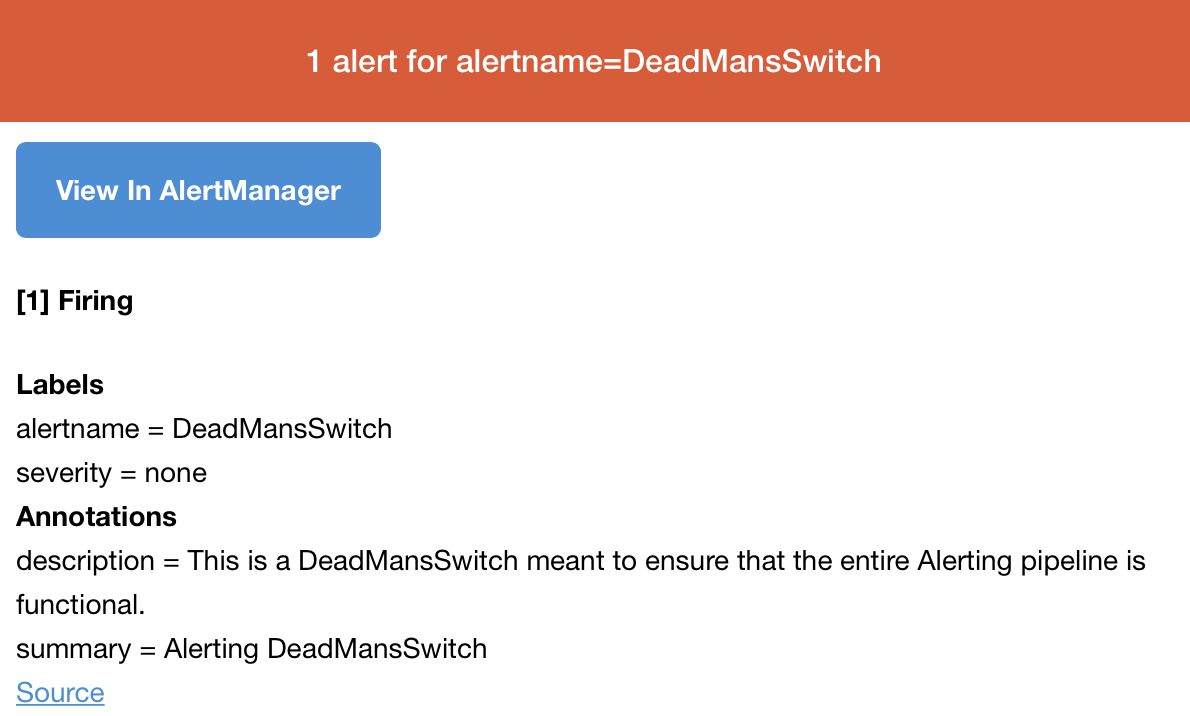
这时候就能收到报警了:
8、到这里部署就完成了,贴一下几个页面:
grafana
prometheus
alertmanager
补充
正常情况下,DeadMansSwitch会一直存在,为了让它不报警,这里我添加了一条匹配规则和一个receivernull,并将报警发送到null:global: resolve_timeout: 5m smtp_smarthost: "mail.xxxx.com:25" smtp_from: "example@xxxx.com" smtp_auth_username: "expample@xxxx.com" smtp_auth_password: "pass" route: group_by: ['alertname', 'cluster', 'service'] group_wait: 30s group_interval: 5m repeat_interval: 15m receiver: team-X-mails routes: - match_re: alertname: ^(host_cpu_usage|node_filesystem_free|host_down)$ receiver: team-X-mails routes: - match: severity: critical receiver: team-X-mails - match: alertname: DeadMansSwitch receiver: 'null' receivers: - name: "team-X-mails" email_configs: - to: "example@xxxx.com" - name: 'null'
这样就不会一直收到报警了。


相关文章推荐
- zabbix 邮件报警部署
- Event Handler的开发与部署--扩展练习:上传文档后,指定用户,添加发送邮件通知操作
- Zabbix添加监控项及配置邮件报警
- Prometheus智能化报警流程避免邮件轰炸
- zabbix告警(一)---添加邮件报警
- Zabbix添加监控项及配置邮件报警
- Zabbix添加监控项及配置邮件报警
- 在LAMP架构中部署zabbix监控系统及邮件报警机制
- 企业级监控软件Zabbix搭建部署之zabbix集成应用邮件报警
- Zabbix搭建部署之使用mutt+msmtp配置Zabbix邮件报警
- zabbix添加邮件报警机制
- 分布式监控系统Zabbix-3.0.3-完整安装记录(5)-邮件报警部署
- 给zabbix添加短信、微信、邮件报警
- 企业级监控软件Zabbix搭建部署之使用mutt+msmtp配置Zabbix邮件报警 推荐
- 分布式监控系统Zabbix3.2给异常添加邮件报警
- nagios添加139邮件短信通知报警
- zabbix3.0.4安装部署文档(四)--邮件报警
- nagios部署+短信和邮件报警
- 分布式监控系统Zabbix3.2给异常添加邮件报警
- Centos7下zabbix部署(四)定义报警媒介-邮件