利用无参数的K近邻分类器KNeighborsClassifier进行三类分类(复习4)
2018-01-13 17:28
357 查看
本文是个人学习笔记,内容主要涉及KNN(KNeighborsClassifier)对sklearn内置的Iris数据集进行三类分类。
K近邻模型的大致决策方式如下图:
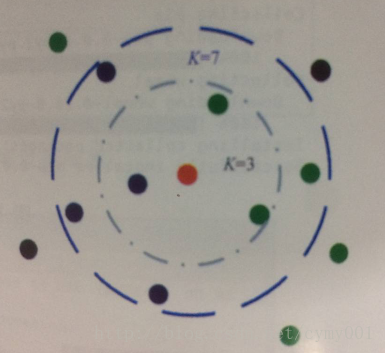
寻找与某个待分类样本在特征空间中距离最近的K个已标记样本作为参考,进而帮助做出分类决策。K取不同的值,会得到不同效果的分类器(比如上如K=3时红色点被分为绿色类,K=7时红色点被分为蓝色类)。
K近邻算法没有参数训练过程,即没有通过任何学习算法分析训练数据,只是根据测试样本在训练数据的分布直接做出分类决策,因此K近邻属于无参数模型,该模型的计算复杂度(平方级)和内存消耗非常高。该模型每处理一个测试样本,都需要对所有预先加载在内村的训练样本进行遍历,逐一计算相似度、排序并且选取K个最近邻训练样本的标记,进而做出分类决策。

K近邻模型的大致决策方式如下图:
寻找与某个待分类样本在特征空间中距离最近的K个已标记样本作为参考,进而帮助做出分类决策。K取不同的值,会得到不同效果的分类器(比如上如K=3时红色点被分为绿色类,K=7时红色点被分为蓝色类)。
K近邻算法没有参数训练过程,即没有通过任何学习算法分析训练数据,只是根据测试样本在训练数据的分布直接做出分类决策,因此K近邻属于无参数模型,该模型的计算复杂度(平方级)和内存消耗非常高。该模型每处理一个测试样本,都需要对所有预先加载在内村的训练样本进行遍历,逐一计算相似度、排序并且选取K个最近邻训练样本的标记,进而做出分类决策。
from sklearn.datasets import load_iris iris=load_iris() iris.data.shape #Output:(150,4)
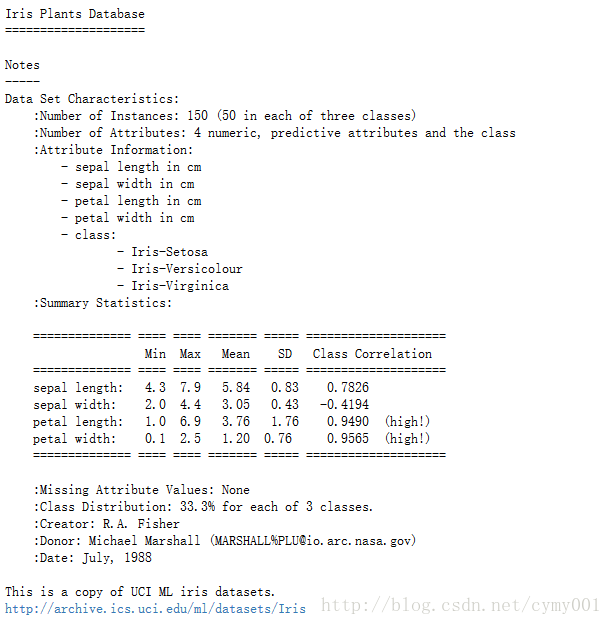
print(iris.DESCR) #查看数据说明
from distutils.version import LooseVersion as Version from sklearn import __version__ as sklearn_version from sklearn import datasets if Version(sklearn_version) < '0.18': from sklearn.cross_validation import train_test_split else: from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=33)
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
ss=StandardScaler()
X_train=ss.fit_transform(X_train)
X_test=ss.transform(X_test)
knc=KNeighborsClassifier()
knc.fit(X_train,y_train)
y_predict=knc.predict(X_test)
print('The accuracy of K-Nearest Neighbor Classifier is',knc.score(X_test,y_test))
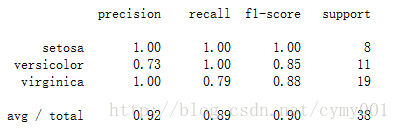
#Output:The accuracy of K-Nearest Neighbor Classifier is 0.894736842105from sklearn.metrics import classification_report print(classification_report(y_test,y_predict,target_names=iris.target_names))

相关文章推荐
- 利用平行坐标轴分类的决策树分类器DecisionTreeClassifier进行二类分类(复习5)
- 利用树的集成模型分类器RandomForestClassifier/GradientBoostingClassifier进行二类分类(复习6)
- 利用基于贝叶斯定理的朴素贝叶斯分类器MultinomialNB进行多类分类(复习3)
- 利用K近邻(回归)KNeighborsRegressor进行回归预测(复习9)
- 利用基于线性假设的线性分类器LogisticRegression/SGDClassifier进行二类分类(复习1)
- 利用基于线性假设的支持向量机分类器LinearSVC进行多类分类(复习2)
- 利用SVC(Support Vector Classifier)对digits数据进行分类
- 利用sklearn包中的k-近邻算法进行分类
- 数据挖掘-K-近邻分类器-Iris数据集分析-使用K-近邻分类器进行分类预测(四)
- 利用训练好的参数模型对图片进行分类
- 【Caffe的C++接口使用说明(三)】Ubuntu14.04下Caffe利用训练好的模型进行分类的C++接口使用说明(三)
- Tensorflow利用DNNClassifier分类有serving初级使用
- python中利用KNN实现对iris进行分类
- 利用工具箱进行分类实验
- 利用kmeans分类对重庆经济进行分析
- 利用K-NN通过PCA进行图片分类
- 利用参数宏进行角度与弧度转换
- python中K近邻分类器(无参训练)对数据进行类别预测 可视化
- 实习生的监控算法: 利用机器学习方法进行曲线分类
- 利用参数宏进行角度与弧度的转换