R语言笔记之模型评估度量
2018-01-13 17:02
357 查看
1.回归模型评估度量
回归模型的表现度量方式:RMSE:均方误差平方根
校正R^2:对 原始R^2的改进
Cp:在训练集的RSS上加上惩罚
AIC和BIC:基于最大似然值,对参数进行惩罚
2.分类模型评估度量
分类是指对给定观测样本预测其所属类别,而且类别空间已知,它是有监督学习。> library(dplyr)
> library(randomForest)
> library(caret)
> library(readr)
Warning message:
程辑包‘readr’是用R版本3.4.3 来建造的
>
> disease_dat=read.csv("https://raw.githubusercontent.com/happyrabbit/DataScientistR/master/Data/sim1_da1.csv")
> glimpse(disease_dat)
Observations: 800
Variables: 241
$ Q1.A <int> 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0...
$ Q1.B <int> 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1...
$ Q2.A <int> 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0...
$ Q2.B <int> 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1...
> set.seed(2016)
> trainIndex=createDataPartition(disease_dat$y,p=0.8,list=F,times=1)
> xTrain=disease_dat[trainIndex,]%>%
+ dplyr::select(-y)
> xTest=disease_dat[-trainIndex,]%>%
+ dplyr::select(-y)
> yTrain=disease_dat$y[trainIndex]%>%as.factor()
> yTest=disease_dat$y[-trainIndex]%>%as.factor()
> train_rf=randomForest(yTrain~.,data=xTrain,mty=trunc(sqrt(ncol(xTrain)-1)),ntree=1000,importance=T)
> yhatprob=predict(train_rf,xTest,"prob")
> set.seed(100)
> car::some(yhatprob)
0 1
45 0.592 0.408
158 0.455 0.545
255 0.575 0.425
291 0.513 0.487
314 0.620 0.380
392 0.538 0.462
402 0.472 0.528
443 0.542 0.458
462 0.620 0.380
626 0.586 0.414
> yhat=predict(train_rf,xTest)
> car::some(yhat)
206 273 305 348 519 524 525 599 701 780
1 0 0 0 0 0 0 0 1 0
Levels: 0 1
>(1)Kappa统计量(一致性检验方法)
> table(yhat,yTest) yTest yhat 0 1 0 68 56 1 3 33 > kt=fmsb::Kappa.test(table(yhat,yTest)) > kt$Result$estimate [1] 0.3054738 > kt$Judgement [1] "Fair agreement"
Kappa<0:无一致性
Kappa 0~0.2:略微一致
Kappa 0.2~0.4:轻度一致
Kappa 0.4~0.6:适度一致
Kappa 0.6~0.8:强一致
Kappa 0.8~1.0:几乎完全一致
(2)ROC曲线(和线下面积AUC)
> library(pROC) > rocCurve=roc(response=yTest,predictor=yhatprob[,2]) > plot(rocCurve,legacy.axes=T)
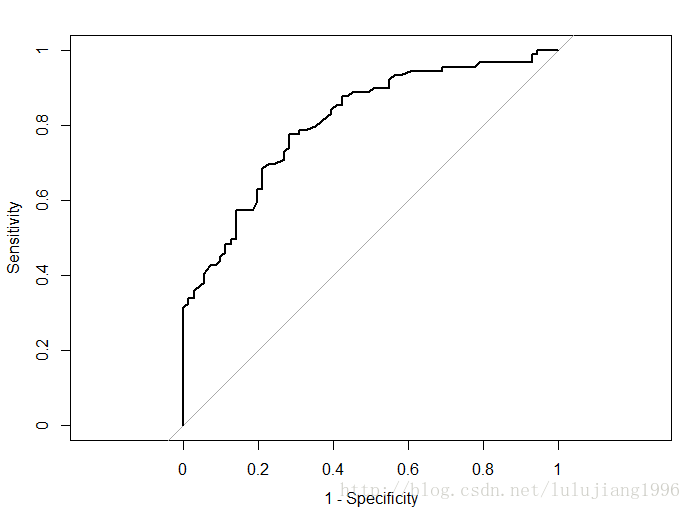
如上图,ROC曲线为通过(0,0)和(1,1)的曲线,完美模型对应的曲线还通过(0,1)点,对应的曲线下面积为1。
完全无效的模型对应的曲线趋近于45度对角线,曲线下面积为0.5.
可以把不同模型结果对应的ROC曲线放一张图中,直观对比模型效果,或者通过曲线下面积(AUC)量化比较模型,对应面积越大的模型越有效。
#得到AUC的估计 > auc(rocCurve) Area under the curve: 0.8083 #DeLong方法得到的AUC置信区间 > ci.auc(rocCurve) 95% CI: 0.7419-0.8746 (DeLong)
以上即为用R语言得到基于DeLong提出的非参数方法得到的AUC的估计和置信区间
ROC曲线主要针对二分类定义,但之后好几位研究人员将其扩展到了多分类的情况
(3)提升图
即一种对分类结果评估的可视化工具
它以图形的形式表示模型预测与随机预测相比带来的改进
> modelscore=yhatprob[,2] > randomscore=rnorm(length(yTest)) > labs=c(modelscore="Random Forest",randomscore="Random Number") > liftCurve=lift(yTest~modelscore+randomscore,class="1",labels=labs) > xyplot(liftCurve,auto.key=list(columns=2,lines=T,points=F)) >
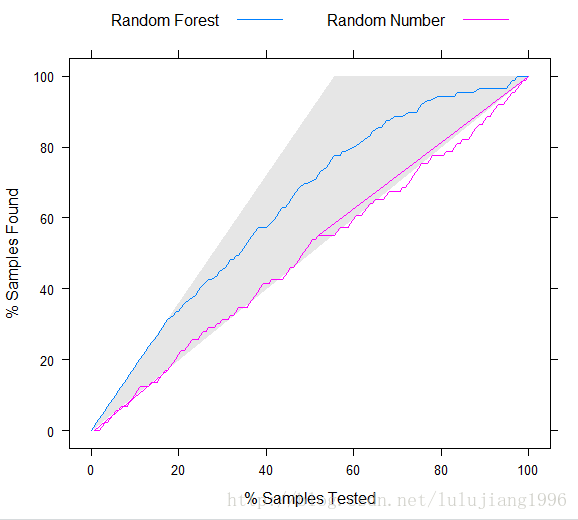
如上图,横轴是累计样本百分点,纵轴是累计获取的目标类样本百分比
3.模型评估总结
(1)尝试尽可能多的模型(2)检查模型的稳定性
(3)模型评估选择通常在模型精确度,稳定性和复杂度这三者之间权衡

相关文章推荐
- 机器学习实战笔记(Python实现)-07-模型评估与分类性能度量
- OCR技术浅探: 语言模型和综合评估(4)
- 机器学习笔记之模型评估与选择
- 第2章 模型评估与选择学习笔记
- 统计语言模型学习笔记
- coursera NLP学习笔记之week2 语言模型
- 机器学习笔记-模型评估与选择, Training set、Validation set 和 Testing set的区别与作用
- 机器学习笔记(III)模型评估与选择(II)
- 机器学习(周志华)- 第2章模型评估与选择笔记
- 斯坦福大学自然语言处理第四课 语言模型(Language Modeling)笔记
- 语言模型的评估-困惑度
- 笔记︱多种常见聚类模型以及分群质量评估(聚类注意事项、使用技巧)
- tensorflow38《TensorFlow实战》笔记-07-02 TensorFlow实现基于LSTM的语言模型 code
- 机器学习笔记(PART II)模型的评估和选择(I)
- 机器学习 —— 性能度量和比较检验、模型评估方法
- 机器学习之模型评估与模型选择(学习笔记)
- 数据挖掘笔记(5)——数据处理、模型评估、可视化、十大经典算法
- 机器学习笔记2——模型评估与选择(一)
- 学习笔记TF035:实现基于LSTM语言模型
- OCR技术浅探: 语言模型和综合评估(4)