python爬虫下载文件
2018-01-12 22:28
302 查看
python爬虫下载文件
下载东西和访问网页差不多,这里以下载我以前做的一个安卓小游戏为例地址为:http://hjwachhy.site/game/only_v1.1.1.apk
首先下载到内存
# coding: UTF-8 import requests url="http://hjwachhy.site/game/only_v1.1.1.apk" r=requests.get(url) print "ok" print len(r.content)
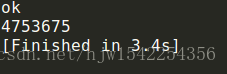
这里是下载到内存,由于是二进制.所以是不能输出text的.
保存文件
# coding: UTF-8 import requests url="http://hjwachhy.site/game/only_v1.1.1.apk" path="only.apk" r=requests.get(url) print "ok" with open(path,"wb") as f: f.write(r.content) f.close()
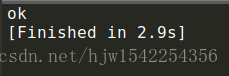
这里是保存到代码目录了,文件名为only.apk
然后看一下文件夹
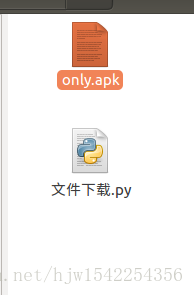
下载成功了!
下首歌听听
写了这么久代码,是时候放松一下了,让我们来下载一首歌听听。只要修改上面代码的url和path变量就行了。如下:
# coding: UTF-8 import requests url="http://hjwachhy.site/music.mp3" path="music.mp3" r=requests.get(url) print "ok" with open(path,"wb") as f: f.write(r.content) f.close()
好了,现在可以打开文件夹听下音乐了。
4000

相关文章推荐
- 解决Python爬虫在爬资源过程中使用urlretrieve函数下载文件不完全且避免下载时长过长陷入死循环,并在下载文件的过程中显示下载进度
- python爬虫:selenuim+phantomjs模拟浏览器操作,用BeautifulSoup解析页面,用requests下载文件
- mac os平台使用python爬虫自动下载巨潮网络文件
- Python爬虫框架scrapy实现的文件下载功能示例
- python爬虫(Python读取TXT文件中的URL并下载文件)
- Python爬虫下载PDF文件
- Python爬虫之下载媒体文件
- python爬虫下载网站所有文件
- Python爬虫判断url链接的是下载文件还是html文件
- python爬虫(3.下载文件)
- python网络爬虫之使用scrapy下载文件
- github 资源文件下载(python 爬虫)
- python爬虫下载文件
- 【用Python写爬虫】获取html的方法【四】:使用urllib下载文件
- Python下载文件的方法
- Python+django实现文件下载
- Python之FTP多线程下载文件之多线程分块下载文件
- Python小爬虫-自动下载三亿文库文档
- python脚本工具-1 制作爬虫下载网页图片
- 下载远程文件, 加入一个进度显示 分类: python 2013-06-09 12:09 314人阅读 评论(0) 收藏