ElasticSearch的配置和使用
2018-01-12 10:45
134 查看
前面的一篇文章关于Lucene的文章我们讲了Lucene的一些基本使用,接下去我们讲一讲ElasticSearch。那么什么是ES?ES是基于Lucene的一个搜索引擎,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。我们知道Lucene其实就是一些工具包,一些API,来给我们调用做搜索。而ES它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,当然也有java还有其他语言的接口并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。就好像Lucene是发动机,是轮子,而ES就是汽车。类似基于Lucene的搜索引擎还有solr,它相比solr,在实时搜索方面更快。
一、部署
这里用的elasticsearch-2.2.0的版本,需要jdk1.7的支持,es5需要jdk1.8的支持,其他es版本下载地址
1. elasticsearch-2.2.0
2. jdk1.7以上
3. maven3.5.2
解压。
需要JAVA_HOME 1.7的支持

找到bin目录下的 elasticsearch.bat,双击
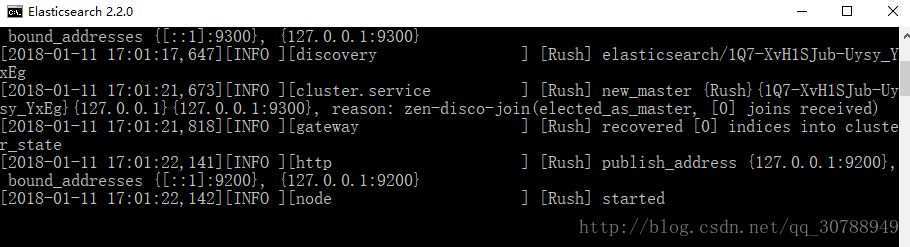
启动成功!
接下去我们安装一下head插件,head插件为我们提供了一个管理界面,可以很好的管理集群,索引等,方便我们练习。因为这个插件可以直接操作索引,所以一般生产环境不安装。
二、安装head插件
进入es/bin目录
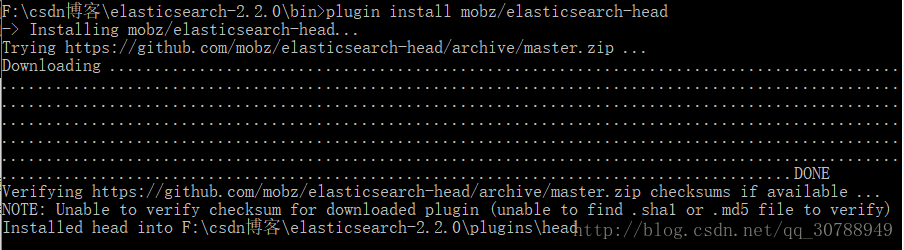
这样就安装好head插件了,进入 http://localhost:9200/_plugin/head/ , head默认的端口是9200

这个就是es给我们提供的一个管理界面
4000
,具体的一些功能就不多叙述了,用用就会了~
二、安装ik分词
分词器就是将单词分开,英文很好分,就是按照空格或者其他分,但是中文就比较复杂。es默认给我们提供了分词器,就是standard分词器,我们先试一下:
http://localhost:9200/_analyze?analyzer=standard&pretty=true&text=Hello World,今天星期几_analyze分词,analyzer=standard用standard分词器,pretty=true结果优雅的显示,text=今天星期几 , 需要分词的文本。结果:

发现英文确实是分开的,但是中文词语分成一个个单词了。 ik分词是一款支持中文的分词插件,我们现在安装ik分词来试试。
下载地址:ik分词下载,这里要注意和es的版本匹配,因为我们用是es2.2.0的,所以下了1.8.0.zip,下载解压。
进入解压目录,用maven打包,打包挺慢的。

好了以后我们进入ik目录\elasticsearch-analysis-ik-1.8.0\target\releases,有一个elasticsearch-analysis-ik-1.8.0.zip,这个就是我们需要的文件,解压。然后在es的目录的plugins目录下建一个ik目录,elasticsearch-2.2.0\plugins\ik,将刚才解压后的几个文件放到这个ik目录中,如图。

ok,ik分词安装完成,我们重启一下es。
我们再试一下:http://localhost:9200/_analyze?analyzer=standard&pretty=true&text=Hello World,今天星期几

很明显发现不再是一个个中文字,而是一个个词语。
es的基本使用就这么写,我们知道es可以通过RESTful接口去调用,当然也支持java接口,接下去我们就讲一下restful和java接口调用
一、部署
这里用的elasticsearch-2.2.0的版本,需要jdk1.7的支持,es5需要jdk1.8的支持,其他es版本下载地址
1. elasticsearch-2.2.0
2. jdk1.7以上
3. maven3.5.2
解压。
需要JAVA_HOME 1.7的支持
找到bin目录下的 elasticsearch.bat,双击
启动成功!
接下去我们安装一下head插件,head插件为我们提供了一个管理界面,可以很好的管理集群,索引等,方便我们练习。因为这个插件可以直接操作索引,所以一般生产环境不安装。
二、安装head插件
进入es/bin目录
这样就安装好head插件了,进入 http://localhost:9200/_plugin/head/ , head默认的端口是9200
这个就是es给我们提供的一个管理界面
4000
,具体的一些功能就不多叙述了,用用就会了~
二、安装ik分词
分词器就是将单词分开,英文很好分,就是按照空格或者其他分,但是中文就比较复杂。es默认给我们提供了分词器,就是standard分词器,我们先试一下:
http://localhost:9200/_analyze?analyzer=standard&pretty=true&text=Hello World,今天星期几_analyze分词,analyzer=standard用standard分词器,pretty=true结果优雅的显示,text=今天星期几 , 需要分词的文本。结果:
发现英文确实是分开的,但是中文词语分成一个个单词了。 ik分词是一款支持中文的分词插件,我们现在安装ik分词来试试。
下载地址:ik分词下载,这里要注意和es的版本匹配,因为我们用是es2.2.0的,所以下了1.8.0.zip,下载解压。
进入解压目录,用maven打包,打包挺慢的。
好了以后我们进入ik目录\elasticsearch-analysis-ik-1.8.0\target\releases,有一个elasticsearch-analysis-ik-1.8.0.zip,这个就是我们需要的文件,解压。然后在es的目录的plugins目录下建一个ik目录,elasticsearch-2.2.0\plugins\ik,将刚才解压后的几个文件放到这个ik目录中,如图。
ok,ik分词安装完成,我们重启一下es。
我们再试一下:http://localhost:9200/_analyze?analyzer=standard&pretty=true&text=Hello World,今天星期几
很明显发现不再是一个个中文字,而是一个个词语。
es的基本使用就这么写,我们知道es可以通过RESTful接口去调用,当然也支持java接口,接下去我们就讲一下restful和java接口调用

相关文章推荐
- ElasticSearch-2.0.0集群安装配置与API使用实践
- Elasticsearch初步使用(安装、Head配置、分词器配置)
- mongodb使用ElasticSearch 进行检索配置
- Elasticsearch初步使用(安装、Head配置、分词器配置)
- ElasticSearch速学 - 简单集群、初步配置和使用
- elasticsearch安装与使用(5)-- search guard安装与配置
- elasticsearch 1.5 + mysql安装配置与简单使用
- Elasticsearch初步使用(安装、Head配置、分词器配置)
- elasticsearch-river-kafka 插件的环境配置和使用
- 四、ElasticSearch5.5.2安装使用Kibana监控及配置
- Elasticsearch 中文分词器 IK 配置和使用
- Elasticsearch 默认配置 IK 及 Java AnalyzeRequestBuilder 使用
- 网站用户行为数据统计与分析之六:elasticsearch的配置和使用
- Elasticsearch初步使用(安装、Head配置、分词器配置)
- Elasticsearch 中文分词器 IK 配置和使用
- elasticsearch-river-kafka 插件的环境配置和使用
- Elasticsearch 中文分词器 IK 配置和使用
- Elasticsearch初步使用(安装、Head配置、分词器配置)