CNN入门教程与实战
2018-01-11 21:51
113 查看
一 基本概念
1 全连接,局部连接,权值共享
全连接:所有输入点都需要与下一个节点相连接
局部连接:每个节点只与部分节点相连接
权值共享:每个与输出节点相连接的参数公用
假定:w*h的输入通道数c照片,下一层节点个数:node个,提取的特征个数feat,卷积核大小c_w*c_h,部分连接个数node_part
则参数个数:
全连接: feat*(c_w*c_h*c+1)*node
局部连接:feat*(c_w*c_h*c+1)*node_part
权值共享:feat*(c_w*c_h+1)
说明:+1 在于有一个偏置
个人理解:可以将输入照片的通道理解为输入层的特征数,每一个特征数就是一个特征的图
2 网络结构
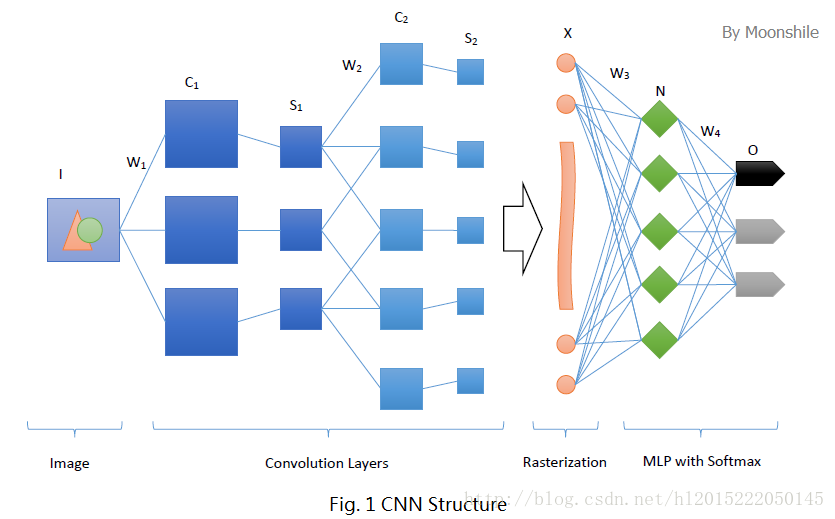
卷积层:将输入的层通过局部连接并在输入特征图上经过卷积核大小的模板进行滑动生成的特征。对应像素值=核以及对应的窗口相对应的点的积的累加如下图:

随着模板的移动,生成的特征图大小在不断的缩小,假定卷积核大小为W*W(一般宽高一致),其缩小的大小为:2*((int)W/2)。因此在需要大小保持不变时候,需要在卷积后填充0,具体为tf.nn.conv2d函数的padding的SAME就能填充后保持特征图大小不变。
感受野:类比于人的眼睛聚焦范围,说白了就是卷积核的大小
池化层:也叫做下采样层;实质就是将一个卷积层,用同样大小的卷积核卷积然后选择部分作为连接或者不连接。假定采用tf.nn.max_pool的ksize参数为[1,
2, 2, 1]时候:
图像宽高分别为减少1/2;相当与在X和Y轴分别二选一;
所以参数总个数:(2*2+1)*特征图宽*特征图高*特征数
注:+1是偏置
全连接层:将所有节点都与输出特征图中点连接,但是权值共享
DropOut层:该层能够有效降低过拟合。其做法是:在训练时候,随机的按照一定比例暂时将神经元抛弃。实际做法是将神经元的激活值按照一定概率变为0。一般地:在多层卷积之后需要采用该层。
与L范式正则不同在于:
1 DropOut是将激活值按照概率变为0,而范式正则化是将激活值变化抑制
2 DropOut 改变网络深度,范式正则化改变代价函数
结构图(w:权值 C:卷积层 S:下采样层 X:光栅化 N:感知器O:输出)
二 相关函数
tf.placeholder:定义变量为形参,在执行时候具体赋值
参数:
dtype:数据类型。常用的是tf.float32,tf.float64等数值类型
shape:数据形状。默认是None,就是一维值,也可以是多维,比如[2,3], [None, 3]表示列是3,行不定
name:名称。
tf.cast:强制类型转换函数
参数:x:输入
dtype:转换目标类型
name:名称
返回:Tensor
tf.reduce_mean:沿着张量不同的数轴进行计算平均值。
参数:
input_tensor: 被计算的张量,确保为数字类型。
axis: 方向数轴,如果没有指明,默认:所有值的均值 0:纵向计算 1横向计算
keep_dims: 如果定义true, 则维数不变,但是只有一个有数据.
name: 操作过程的名称。
reduction_indices: 为了旧函数兼容的数轴。
返回值:降低维数的平均值。
tf.equal(A, B):对比这两个矩阵或者向量的相等的元素
返回与矩阵A相同的数组,同时相等的下标处为true
tf.argmax:按行或者列计算最大值
参数:
input:输入Tensor
axis:0表示按列,1表示按行
name:名称
dimension:和axis功能一样,默认axis取值优先。新加的字段
返回值:行或列的最大值下标向量
tf.nn.softmax_cross_entropy_with_logits:计算损失值
参数:
Logits:输出层
Labels:标签
返回值:损失值
tf.train.AdamOptimizer:采用Adam算法寻找全局最优点,引入了二次梯度矫正
参见:
https://www.jianshu.com/p/e6e8aa3169ca
http://blog.csdn.net/mzpmzk/article/details/78647654
tf.nn.conv2d:卷积
input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4 :分别对应input的4个维度,强制:strides[0]=strides[3]=1 [batch, in_height, in_width, in_channels]分别滑动多少。Batch可以理解为特征图
padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式。SAME:不足部分用0或者1填充;VALID:丢弃
use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
data_format:string类型的量,'NHWC'和'NCHW'其中之一,这是tensorflow新版本中新加的参数,它说明了value参数的数据格式。'NHWC'指tensorflow标准的数据格式[batch, height, width, in_channels],
'NCHW'指Theano的数据格式,[batch, in_channels,height, width],当然默认值是'NHWC'
返回值:Tensor,这个输出,就是我们常说的featuremap,shape仍然是[batch, height, width, channels]这种形式。
tf.nn.max_pool:池化
参数:
value:以tf.nn.conv2d()函数的参数input理解即可。
ksize:滑动窗口(pool)的大小尺寸,这里注意这个大小尺寸并不仅仅指2维上的高和宽,ksize的每个维度同样对应input
的各个维度(只是大小,不是滑动步长),同样的,batch(特征)和in_channels维度多设置为1。如pooling层1的ksize即为
[1, 2, 2, 1],即用一个2*2的窗口做pooling。
strides:同tf.nn.conv2d()函数的参数strides。
padding:SAME 会填充卷积 否则不会
参见:https://www.cnblogs.com/willnote/p/6874699.html
tf.matmul:矩阵相乘(全连接)
tf.nn.dropout:下采样层
参数:
X:上一层(全连接层返回值)
keep_prob:占多少几率存活;1=100%
tf.nn.relu():采用relu激活函数
三 搭建Mnist
步骤:
1 搭建模型
定义模型输入输出参数个数:
搭建具体模型:
2 运行
四 相关问题
4.1 过拟合
1) 定义
假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据集上却不能很好的拟合数据。表现在:很好的照顾了训练集中每个点,导致模型的复杂,使得泛化能力不够。
2) 原因
1 模型复杂,维度过高(等价于并不是特征越多越好),参数多同时过训练
2数据噪声影响
3 数据量不够
3) 解决办法
1 交叉验证法
原理:将训练样本分为K份,将其中一份当做验证集,剩下作为训练集(在数据少时候有效)
2 正则化
防止过拟合,用合理的数量的验证集的准确率动态改变学习率
1 权重衰减(L2)

原理:在用梯度下降更新w时候,对w求导会出现一个负数的权重,使得对w进行了衰减。其实就是减少波动弧度。
2 其他(L1、L3等):原理类似
3 Early Stopping
即在每一个epoch结束时(一个epoch即对所有训练数据的一轮遍历)计算 validation data的accuracy,当accuracy不再提高时,就停止训练。
4 增加dropout层
使用该层能够有效的防止过拟合
5 数据集扩增
深度学习最后都是拼数据了…………大公司的优势
4.2 数据集不平衡
1 数据的分布对模型训练影响很大
2 提升准确率:过采样(有放回的抽样)可能带来过拟合
4.3 batch size影响
batch size的大小影响模型的优化程度和速度。
1 batch size越大
内存利用率提高,相同数据量处理越快;同时,梯度下降的方向越准确,也就是模型的大方向不易错;
但是:达到相同的精度,迭代次数就会增大,也就是训练时间长一些
2 batch size越小
在很短的迭代次数中很难收敛;
3 具体
在计算梯度时候,将mini-batch个做了损失值的均值。
4.4 梯度弥散与梯度爆炸
1 梯度弥散
a) 现象
使用反向传播算法传播梯度的时候,随着传播深度的增加,梯度的幅度会急剧减小,会导致浅层神经元的权重更新非常缓慢,不能有效学习。
b) 如何抑制(不是解决)
批规范化:在每次计算SGD(梯度下降)时,将每次的mini-batch的激励做规范化,使得就、激励均值为0,方差为1。最后通过scale andshift加入一个BN(平衡网络)还原最初的输入,从而保证整个网络的激励。
参考文献《Batch Normalization: Accelerating DeepNetwork Training by Reducing Internal Covariate Shift》
2 梯度爆炸
a) 现象
使用反向传播算法传播梯度的时候,中间反向传播的值出现大于1的时候,使得激励函数过大,导致神经元变化剧烈。
b) 抑制办法(基本能解决)
梯度裁剪:当参量的L2范数(参见:权值衰减)超过特定的阈值就对参数进行标准化。
新梯度=梯度 * 阈值 / 梯度L2范数
五 模型保存与恢复
先谈模型恢复:
模型恢复有两种方式:
1 自己构造graph,恢复图中变量
该方式:
a) 按照训练的graph构造相同的graph
b) 获得Saver 例如: model_saver = tf.train.Saver()
c) model_saver.restore(sess,model_path)
demo:
2 连同graph和数据一起恢复
该方式:
a) saver =tf.train.import_meta_graph(model_file+'.meta')
b) saver.restore(sess, model_file)
c) graph = tf.get_default_graph()
d) 获取graph的输入tensor和输出层的tensor
Demo:
获取tensor方式:
1 graph.get_operation_by_name('keep_prob').outputs[0]
2 graph.get_tensor_by_name("input:0")
3 tf.get_collection('pred_network')[0]
注:1和2方式等价。
模型保存:
1 定义需要层的name,一般为输出层(要预测嘛,当然也可以获取中间层),同时还可以构造一个layer:
如:
b = tf.constant(value=1,dtype=tf.float32)
logits_eval = tf.multiply(pred,b,name='logits_eval')# pred为输出层
2构造Saver
model_saver = tf.train.Saver(max_to_keep=3)
max_to_keep:表示保存最新的三次模型。
3 执行保存
model_saver.save(sess,os.path.join(model_dir,model_name))
模型保存说明:
checkpoint文件会记录保存信息,通过它可以定位最新保存的模型:
.meta文件保存了当前图结构;
.index文件保存了当前参数名;
.data文件保存了当前参数值。
相关demo链接(mnist 训练 模型保存以及两种方式恢复代码):http://download.csdn.net/download/hl2015222050145/10201321
1 全连接,局部连接,权值共享
全连接:所有输入点都需要与下一个节点相连接
局部连接:每个节点只与部分节点相连接
权值共享:每个与输出节点相连接的参数公用
假定:w*h的输入通道数c照片,下一层节点个数:node个,提取的特征个数feat,卷积核大小c_w*c_h,部分连接个数node_part
则参数个数:
全连接: feat*(c_w*c_h*c+1)*node
局部连接:feat*(c_w*c_h*c+1)*node_part
权值共享:feat*(c_w*c_h+1)
说明:+1 在于有一个偏置
个人理解:可以将输入照片的通道理解为输入层的特征数,每一个特征数就是一个特征的图
2 网络结构
卷积层:将输入的层通过局部连接并在输入特征图上经过卷积核大小的模板进行滑动生成的特征。对应像素值=核以及对应的窗口相对应的点的积的累加如下图:
随着模板的移动,生成的特征图大小在不断的缩小,假定卷积核大小为W*W(一般宽高一致),其缩小的大小为:2*((int)W/2)。因此在需要大小保持不变时候,需要在卷积后填充0,具体为tf.nn.conv2d函数的padding的SAME就能填充后保持特征图大小不变。
感受野:类比于人的眼睛聚焦范围,说白了就是卷积核的大小
池化层:也叫做下采样层;实质就是将一个卷积层,用同样大小的卷积核卷积然后选择部分作为连接或者不连接。假定采用tf.nn.max_pool的ksize参数为[1,
2, 2, 1]时候:
图像宽高分别为减少1/2;相当与在X和Y轴分别二选一;
所以参数总个数:(2*2+1)*特征图宽*特征图高*特征数
注:+1是偏置
全连接层:将所有节点都与输出特征图中点连接,但是权值共享
DropOut层:该层能够有效降低过拟合。其做法是:在训练时候,随机的按照一定比例暂时将神经元抛弃。实际做法是将神经元的激活值按照一定概率变为0。一般地:在多层卷积之后需要采用该层。
与L范式正则不同在于:
1 DropOut是将激活值按照概率变为0,而范式正则化是将激活值变化抑制
2 DropOut 改变网络深度,范式正则化改变代价函数
结构图(w:权值 C:卷积层 S:下采样层 X:光栅化 N:感知器O:输出)
二 相关函数
tf.placeholder:定义变量为形参,在执行时候具体赋值
参数:
dtype:数据类型。常用的是tf.float32,tf.float64等数值类型
shape:数据形状。默认是None,就是一维值,也可以是多维,比如[2,3], [None, 3]表示列是3,行不定
name:名称。
tf.cast:强制类型转换函数
参数:x:输入
dtype:转换目标类型
name:名称
返回:Tensor
tf.reduce_mean:沿着张量不同的数轴进行计算平均值。
参数:
input_tensor: 被计算的张量,确保为数字类型。
axis: 方向数轴,如果没有指明,默认:所有值的均值 0:纵向计算 1横向计算
keep_dims: 如果定义true, 则维数不变,但是只有一个有数据.
name: 操作过程的名称。
reduction_indices: 为了旧函数兼容的数轴。
返回值:降低维数的平均值。
tf.equal(A, B):对比这两个矩阵或者向量的相等的元素
返回与矩阵A相同的数组,同时相等的下标处为true
tf.argmax:按行或者列计算最大值
参数:
input:输入Tensor
axis:0表示按列,1表示按行
name:名称
dimension:和axis功能一样,默认axis取值优先。新加的字段
返回值:行或列的最大值下标向量
tf.nn.softmax_cross_entropy_with_logits:计算损失值
参数:
Logits:输出层
Labels:标签
返回值:损失值
tf.train.AdamOptimizer:采用Adam算法寻找全局最优点,引入了二次梯度矫正
参见:
https://www.jianshu.com/p/e6e8aa3169ca
http://blog.csdn.net/mzpmzk/article/details/78647654
tf.nn.conv2d:卷积
input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4 :分别对应input的4个维度,强制:strides[0]=strides[3]=1 [batch, in_height, in_width, in_channels]分别滑动多少。Batch可以理解为特征图
padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式。SAME:不足部分用0或者1填充;VALID:丢弃
use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
data_format:string类型的量,'NHWC'和'NCHW'其中之一,这是tensorflow新版本中新加的参数,它说明了value参数的数据格式。'NHWC'指tensorflow标准的数据格式[batch, height, width, in_channels],
'NCHW'指Theano的数据格式,[batch, in_channels,height, width],当然默认值是'NHWC'
返回值:Tensor,这个输出,就是我们常说的featuremap,shape仍然是[batch, height, width, channels]这种形式。
tf.nn.max_pool:池化
参数:
value:以tf.nn.conv2d()函数的参数input理解即可。
ksize:滑动窗口(pool)的大小尺寸,这里注意这个大小尺寸并不仅仅指2维上的高和宽,ksize的每个维度同样对应input
的各个维度(只是大小,不是滑动步长),同样的,batch(特征)和in_channels维度多设置为1。如pooling层1的ksize即为
[1, 2, 2, 1],即用一个2*2的窗口做pooling。
strides:同tf.nn.conv2d()函数的参数strides。
padding:SAME 会填充卷积 否则不会
参见:https://www.cnblogs.com/willnote/p/6874699.html
tf.matmul:矩阵相乘(全连接)
tf.nn.dropout:下采样层
参数:
X:上一层(全连接层返回值)
keep_prob:占多少几率存活;1=100%
tf.nn.relu():采用relu激活函数
三 搭建Mnist
步骤:
1 搭建模型
定义模型输入输出参数个数:
weights={
'conv1':tf.Variable(tf.random_normal([5,5,1,32])),
'conv2':tf.Variable(tf.random_normal([5,5,32,64])),
'fc1':tf.Variable(tf.random_normal([7*7*64,1024])),
'out':tf.Variable(tf.random_normal([1024,n_classes]))
}
biases={
'conv_b1':tf.Variable(tf.random_normal([32])),
'conv_b2':tf.Variable(tf.random_normal([64])),
'fc1_b':tf.Variable(tf.random_normal([1024])),
'out_b':tf.Variable(tf.random_normal([n_classes]))
}搭建具体模型:
#将输入图像格式化到28*28大小 x_image=tf.reshape(x,[-1,28,28,1]) #卷积后采用relu函数作为激励层 h_conv1=tf.nn.relu(conv2d(x_image,weights['conv1'])+biases['conv_b1']) #下采样层 14*14 h_pool1=max_pool_2x2(h_conv1) # 卷积后采用relu函数作为激励层 h_conv2=tf.nn.relu(conv2d(h_pool1,weights['conv2'])+biases['conv_b2']) #下采样层 7*7 h_pool2=max_pool_2x2(h_conv2) #将64个7*7的矩阵转变为7*7*64一维数组 [维数,每维个数] h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64]) # matmul全连接后采用relu函数作为激励层 h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,weights['fc1'])+biases['fc1_b']) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # dropout层 # matmul全连接输出 out_layer = tf.matmul(h_fc1_drop, weights['out']) + biases['out_b'] #定义损失函数以及优化函数 cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y)) optimizer=tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
2 运行
with tf.Session() as sess:
sess.run(init)
#Training cycle
for epoch in range(training_epochs):
# 获取下一批次的数据 数据和标签
batch_x, batch_y =mnist.train.next_batch(batch_size)
# 先预测后训练 训练100次,验证一次
if epoch % 100 == 0:
train_acc=accuracy.eval(feed_dict={x:batch_x,y:batch_y,keep_prob:1.0})
print('step', epoch, 'training accuracy', train_acc)
# 执行优化算法BP和损失函数以获取损失值
sess.run([optimizer, cost], feed_dict={x:batch_x,y:batch_y, keep_prob: 0.5})
print("OptimizationFinished!")
#保存模型
model_dir = "mnist"
model_name = "cpk"
if not os.path.exists(model_dir):
os.makedirs(model_dir)
model_saver.save(sess,os.path.join(model_dir,model_name))
print("model saved sucessfully")四 相关问题
4.1 过拟合
1) 定义
假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据集上却不能很好的拟合数据。表现在:很好的照顾了训练集中每个点,导致模型的复杂,使得泛化能力不够。
2) 原因
1 模型复杂,维度过高(等价于并不是特征越多越好),参数多同时过训练
2数据噪声影响
3 数据量不够
3) 解决办法
1 交叉验证法
原理:将训练样本分为K份,将其中一份当做验证集,剩下作为训练集(在数据少时候有效)
2 正则化
防止过拟合,用合理的数量的验证集的准确率动态改变学习率
1 权重衰减(L2)
原理:在用梯度下降更新w时候,对w求导会出现一个负数的权重,使得对w进行了衰减。其实就是减少波动弧度。
2 其他(L1、L3等):原理类似
3 Early Stopping
即在每一个epoch结束时(一个epoch即对所有训练数据的一轮遍历)计算 validation data的accuracy,当accuracy不再提高时,就停止训练。
4 增加dropout层
使用该层能够有效的防止过拟合
5 数据集扩增
深度学习最后都是拼数据了…………大公司的优势
4.2 数据集不平衡
1 数据的分布对模型训练影响很大
2 提升准确率:过采样(有放回的抽样)可能带来过拟合
4.3 batch size影响
batch size的大小影响模型的优化程度和速度。
1 batch size越大
内存利用率提高,相同数据量处理越快;同时,梯度下降的方向越准确,也就是模型的大方向不易错;
但是:达到相同的精度,迭代次数就会增大,也就是训练时间长一些
2 batch size越小
在很短的迭代次数中很难收敛;
3 具体
在计算梯度时候,将mini-batch个做了损失值的均值。
4.4 梯度弥散与梯度爆炸
1 梯度弥散
a) 现象
使用反向传播算法传播梯度的时候,随着传播深度的增加,梯度的幅度会急剧减小,会导致浅层神经元的权重更新非常缓慢,不能有效学习。
b) 如何抑制(不是解决)
批规范化:在每次计算SGD(梯度下降)时,将每次的mini-batch的激励做规范化,使得就、激励均值为0,方差为1。最后通过scale andshift加入一个BN(平衡网络)还原最初的输入,从而保证整个网络的激励。
参考文献《Batch Normalization: Accelerating DeepNetwork Training by Reducing Internal Covariate Shift》
2 梯度爆炸
a) 现象
使用反向传播算法传播梯度的时候,中间反向传播的值出现大于1的时候,使得激励函数过大,导致神经元变化剧烈。
b) 抑制办法(基本能解决)
梯度裁剪:当参量的L2范数(参见:权值衰减)超过特定的阈值就对参数进行标准化。
新梯度=梯度 * 阈值 / 梯度L2范数
五 模型保存与恢复
先谈模型恢复:
模型恢复有两种方式:
1 自己构造graph,恢复图中变量
该方式:
a) 按照训练的graph构造相同的graph
b) 获得Saver 例如: model_saver = tf.train.Saver()
c) model_saver.restore(sess,model_path)
demo:
#Create model
def multilayer_preceptron(x,weights,biases):
x_image=tf.reshape(x,[-1,28,28,1])
h_conv1=tf.nn.relu(conv2d(x_image,weights['conv1'])+biases['conv_b1'])
h_pool1=max_pool_2x2(h_conv1)
h_conv2=tf.nn.relu(conv2d(h_pool1,weights['conv2'])+biases['conv_b2'])
h_pool2=max_pool_2x2(h_conv2)
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,weights['fc1'])+biases['fc1_b'])
out_layer=tf.matmul(h_fc1,weights['out'])+biases['out_b']
return out_layer
weights={
'conv1':tf.Variable(tf.random_normal([5,5,1,32])),
'conv2':tf.Variable(tf.random_normal([5,5,32,64])),
'fc1':tf.Variable(tf.random_normal([7*7*64,1024])),
'out':tf.Variable(tf.random_normal([1024,n_classes]))
}
biases={
'conv_b1':tf.Variable(tf.random_normal([32])),
'conv_b2':tf.Variable(tf.random_normal([64])),
'fc1_b':tf.Variable(tf.random_normal([1024])),
'out_b':tf.Variable(tf.random_normal([n_classes]))
}
pred = multilayer_preceptron(x,weights,biases)
#create class Saver
model_saver = tf.train.Saver()
#Launch the gtrph
with tf.Session() as sess:
#create dir for modelsaver
model_dir ="mnist"
model_name ="cpk"
model_path=os.path.join(model_dir,model_name)
model_saver.restore(sess,model_path)
print("模型恢复成功")
"""测试一个测试集"""
img=mnist.test.images[100].reshape(-1,784)
img_label=sess.run(tf.argmax(mnist.test.labels[100]))
ret=sess.run(pred,feed_dict={x:img})
num_pred=sess.run(tf.argmax(ret,1))
print("预测值:%d"% num_pred)
print("真实值:%d"% img_label)2 连同graph和数据一起恢复
该方式:
a) saver =tf.train.import_meta_graph(model_file+'.meta')
b) saver.restore(sess, model_file)
c) graph = tf.get_default_graph()
d) 获取graph的输入tensor和输出层的tensor
Demo:
model_file = tf.train.latest_checkpoint('./mnist/')
saver = tf.train.import_meta_graph(model_file+'.meta')
with tf.Session() as sess:
saver.restore(sess,model_file)
graph= tf.get_default_graph()
#x= graph.get_tensor_by_name("input:0")
x= graph.get_operation_by_name("input").outputs[0]
img=mnist.test.images[100].reshape(-1,784)
#y= tf.get_collection('pred_network')[0]
logits= graph.get_tensor_by_name("logits_eval:0")
keep_prob= graph.get_operation_by_name('keep_prob').outputs[0]
#classification_result= sess.run(y, feed_dict={x:img,keep_prob:1.0})
classification_result= sess.run(logits, feed_dict={x:img,keep_prob:1.0})
num_pred=sess.run(tf.argmax(classification_result,1))
img_label=sess.run(tf.argmax(mnist.test.labels[100]))
print("预测值:%d"% num_pred)
print("真实值:%d"% img_label)获取tensor方式:
1 graph.get_operation_by_name('keep_prob').outputs[0]
2 graph.get_tensor_by_name("input:0")
3 tf.get_collection('pred_network')[0]
注:1和2方式等价。
模型保存:
1 定义需要层的name,一般为输出层(要预测嘛,当然也可以获取中间层),同时还可以构造一个layer:
如:
b = tf.constant(value=1,dtype=tf.float32)
logits_eval = tf.multiply(pred,b,name='logits_eval')# pred为输出层
2构造Saver
model_saver = tf.train.Saver(max_to_keep=3)
max_to_keep:表示保存最新的三次模型。
3 执行保存
model_saver.save(sess,os.path.join(model_dir,model_name))
模型保存说明:
checkpoint文件会记录保存信息,通过它可以定位最新保存的模型:
.meta文件保存了当前图结构;
.index文件保存了当前参数名;
.data文件保存了当前参数值。
相关demo链接(mnist 训练 模型保存以及两种方式恢复代码):http://download.csdn.net/download/hl2015222050145/10201321

相关文章推荐
- mybatis教程:入门>>精通>>实战
- TensorFlow人工智能引擎入门教程之二 CNN卷积神经网络的基本定义理解。
- mybatis实战教程- 入门到精通
- CMake快速入门教程-实战
- mybatis实战教程- 入门到精通
- 云星数据---Scala实战系列(精品版)】:Scala入门教程002-Scala数组详解001
- 云星数据---Scala实战系列(精品版)】:Scala入门教程016-Scala实战源码-Scala 判断语句 、循环与java的比较
- NGUI快速入门 — —《Unity3D+NGUI 实战教程》
- 超全整理】《Linux云计算从入门到精通》linux学习入门教程系列实战笔记全放送
- mybatis实战教程(mybatis in action),mybatis入门到精通
- 云星数据---Scala实战系列(精品版)】:Scala入门教程029-Scala实战源码-Scala 的特质 (接口)05
- 硬盘数据恢复入门教程[四]----实战数据恢复篇
- 云星数据---Scala实战系列(精品版)】:Scala入门教程038-Scala实战源码-Scala match语句03 类型匹配
- mybatis实战教程(mybatis in action),mybatis入门到精通
- 云星数据---Scala实战系列(精品版)】:Scala入门教程047-Scala实战源码-Scala method操作
- 基于Asp.Net Core Mvc和EntityFramework Core 的实战入门教程系列-2
- yii2实战教程之新手入门指南-简单博客管理系统
- 云星数据---Scala实战系列(精品版)】:Scala入门教程050-Scala实战源码-Scala implicit 操作01
- 【备忘】【No5】微信公众平台开发入门到实战开发视频教程(Java+PHP)
- Postman入门教程【没有废话,直入实战,绝对给力!】