6. 深度学习实践:深度前馈网络(续)
2018-01-11 18:14
295 查看
接上篇:6. 深度学习实践:深度前馈网络
该定理意味着:无论我们试图学习什么函数,一个大的MLP一定能够表示这个函数。很完美,是不是?
但是,我们不能保证训练算法能够学得这个函数。一是优化算法可能找不到用于期望函数的参数值。二是训练算法可能过拟合而选择了错误的函数。
no free lunch 告诉我们,不存在万能的过程,既能够验证训练集上的特殊样本,又能选择一个函数来扩展到训练集外的点。
具有单层的FNN足以表示任何函数,但是网络层可能大得无法实现,无法正确学习和泛化。怎么办?使用更深的模型,可以减少期望函数所需的单元的数量,同时可以减少泛化误差。
Montufar et al. (2014)指出:具有d个输入,深度为l,每个隐藏层n个单元的深度整流网络可以描述的线性区域的数量是:
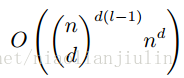
即其是深度的指数级的函数。那么增加深度就很好了。当然不保证所有都有这样的性质,但提供了某种方面的支撑。
隐含的先验:深度模型暗合了我们想要学得的函数应该是若干个更简单的函数的组合。
表示学习的角度:学习的问题包含着发现一组潜在的变差因素,可以根据其他更简单的潜在变差因素来描述。
计算机程序:每个步骤使用前一步骤的输出。中间值传递。
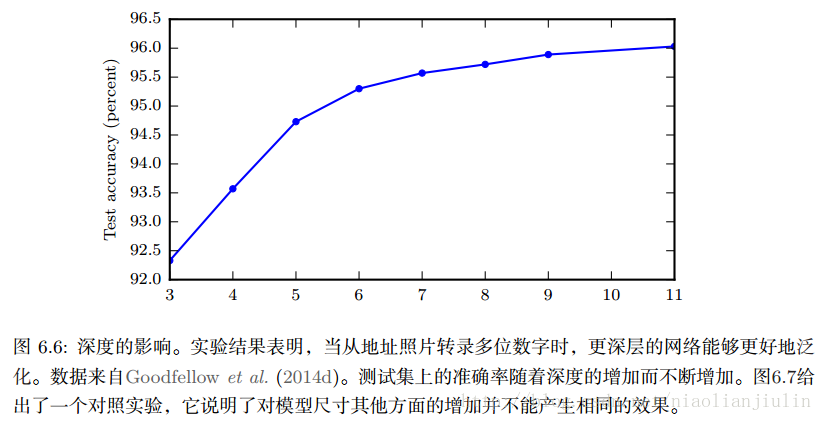
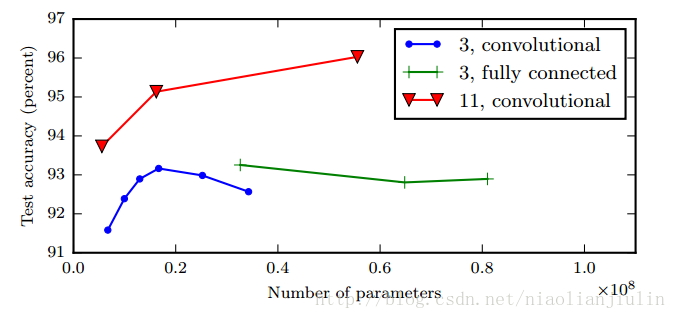
一图胜千言。根据经验,更深的模型似乎确实在广泛任务中泛化得更好,也算提供了先验。
特定任务上:用于CV的CNN,用于序列处理的RNN。有其自身考虑。
许多架构构建了一个主链,添加了额外的架构,比如从更高层的跳跃链接,使得梯度更容易从输出层流向浅层。(想起FCN了)
如何将层与层间连接起来?FNN用矩阵描述的线性变换。一些专用网络具有较少连接,减少了参数量,但通常高度依赖于问题。如CNN用于CV的稀疏连接。
误区1:BP算法是用于多层神经网络的整个学习算法?
实际上BP仅仅指用于计算梯度的方法。另一种算法,如SGD算法,则利用该梯度进行学习。
误区2:BP仅适用于多层神经网络?
原则上BP可以计算任何函数的导数。在学习算法中,最常需要的梯度是代价函数关于参数的梯度,BP可算但不局限于此。
P(A1A2...An)=P(An|A1A2...An−1)...P(A2|A1)P(A1)
此处讨论的是微积分中的链式法则,用于计算复合函数的导数。
y=g(x),z=f(y),则链式法则就是:dzdx=dzdydydx。
将标量进行推广:
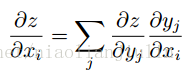
向量记法就是:

αyαx是 g 的 n×m的雅克比矩阵(一阶排列的)。BP算法由每一个这样的雅克比矩阵与梯度的乘积操作所组成。
BP算法可应用于任意维度的张量。与向量唯一区别在于如何将数字排列成网格以形成张量。所以本质上,BP仍然只是将雅克比矩阵乘以梯度。
紧跟着论述的几节,内容上比CS231n讨论的多。但描述上没有后者清晰。对初学者来讲,看CS231n可能更容易理解到BP的精华和方便。这就是写书者(学者)和老师者的不同。
FNN的核心思想自20世纪80年代以来没有发生重大变化,相同的BP算法和相同的梯度下降法。其进步在于:
较大的数据集:减少了统计泛化对NN的挑战
NN由于更强大的计算机和更好的软件基础变得更大
少量算法上的变化也显著改善了性能
算法变化一: 损失函数的交叉熵,代替均方误差。后者上世纪较流行,逐渐被前者代替。最大似然原理广泛传播。使用交叉熵损失,大大提高了具有sigmoid函数和softmax输出的模型的性能。使用均方误差损失会存在饱和、学习缓慢的问题。
算法变化二:分段线性隐藏单元来替代sigmoid隐藏单元。例如整流线性单元。也是命运翻覆,大器晚成。
FNN的很多亮点,从被人舍弃,到今天又被拣起,大放异彩。印证了计算机操作系统那位前辈的话:计算机界的东西反反复复。
5. 架构设计
5.1 深度
万能近似定理:一个FNN如果具有线性输出层和至少一层具有任何一种挤压性质的激活函数的隐藏层,只要给予网络足够数量的隐藏单元,它能够以任意精度来近似任何从一个有限维空间到另一个有限维空间的Borel可测函数。该定理意味着:无论我们试图学习什么函数,一个大的MLP一定能够表示这个函数。很完美,是不是?
但是,我们不能保证训练算法能够学得这个函数。一是优化算法可能找不到用于期望函数的参数值。二是训练算法可能过拟合而选择了错误的函数。
no free lunch 告诉我们,不存在万能的过程,既能够验证训练集上的特殊样本,又能选择一个函数来扩展到训练集外的点。
具有单层的FNN足以表示任何函数,但是网络层可能大得无法实现,无法正确学习和泛化。怎么办?使用更深的模型,可以减少期望函数所需的单元的数量,同时可以减少泛化误差。
Montufar et al. (2014)指出:具有d个输入,深度为l,每个隐藏层n个单元的深度整流网络可以描述的线性区域的数量是:
即其是深度的指数级的函数。那么增加深度就很好了。当然不保证所有都有这样的性质,但提供了某种方面的支撑。
隐含的先验:深度模型暗合了我们想要学得的函数应该是若干个更简单的函数的组合。
表示学习的角度:学习的问题包含着发现一组潜在的变差因素,可以根据其他更简单的潜在变差因素来描述。
计算机程序:每个步骤使用前一步骤的输出。中间值传递。
一图胜千言。根据经验,更深的模型似乎确实在广泛任务中泛化得更好,也算提供了先验。
5.2 其他考虑
杂谈。特定任务上:用于CV的CNN,用于序列处理的RNN。有其自身考虑。
许多架构构建了一个主链,添加了额外的架构,比如从更高层的跳跃链接,使得梯度更容易从输出层流向浅层。(想起FCN了)
如何将层与层间连接起来?FNN用矩阵描述的线性变换。一些专用网络具有较少连接,减少了参数量,但通常高度依赖于问题。如CNN用于CV的稀疏连接。
6. BP算法及其他
关于BP算法,在CS231n课程中已学习,并手推、程序伪代码都已见识过。应该说讲得很清楚。此处浏览下书的内容做补充。误区1:BP算法是用于多层神经网络的整个学习算法?
实际上BP仅仅指用于计算梯度的方法。另一种算法,如SGD算法,则利用该梯度进行学习。
误区2:BP仅适用于多层神经网络?
原则上BP可以计算任何函数的导数。在学习算法中,最常需要的梯度是代价函数关于参数的梯度,BP可算但不局限于此。
6.1 链式法则
概率中的链式法则:P(A1A2...An)=P(An|A1A2...An−1)...P(A2|A1)P(A1)
此处讨论的是微积分中的链式法则,用于计算复合函数的导数。
y=g(x),z=f(y),则链式法则就是:dzdx=dzdydydx。
将标量进行推广:
向量记法就是:
αyαx是 g 的 n×m的雅克比矩阵(一阶排列的)。BP算法由每一个这样的雅克比矩阵与梯度的乘积操作所组成。
BP算法可应用于任意维度的张量。与向量唯一区别在于如何将数字排列成网格以形成张量。所以本质上,BP仍然只是将雅克比矩阵乘以梯度。
紧跟着论述的几节,内容上比CS231n讨论的多。但描述上没有后者清晰。对初学者来讲,看CS231n可能更容易理解到BP的精华和方便。这就是写书者(学者)和老师者的不同。
7. 历史小记
FNN可以看做是一种高效的非线性函数近似器。使用梯度下降来最小化函数近似误差。从这个角度看,现代前馈网络是一般函数近似任务的几个世纪进步的结晶。FNN的核心思想自20世纪80年代以来没有发生重大变化,相同的BP算法和相同的梯度下降法。其进步在于:
较大的数据集:减少了统计泛化对NN的挑战
NN由于更强大的计算机和更好的软件基础变得更大
少量算法上的变化也显著改善了性能
算法变化一: 损失函数的交叉熵,代替均方误差。后者上世纪较流行,逐渐被前者代替。最大似然原理广泛传播。使用交叉熵损失,大大提高了具有sigmoid函数和softmax输出的模型的性能。使用均方误差损失会存在饱和、学习缓慢的问题。
算法变化二:分段线性隐藏单元来替代sigmoid隐藏单元。例如整流线性单元。也是命运翻覆,大器晚成。
FNN的很多亮点,从被人舍弃,到今天又被拣起,大放异彩。印证了计算机操作系统那位前辈的话:计算机界的东西反反复复。

相关文章推荐
- 深度学习算法实践9---用Theano实现多层前馈网络
- 6. 深度学习实践:深度前馈网络
- 深度学习算法实践9---用Theano实现多层前馈网络
- 深度学习算法实践3---神经网络常用操作实现
- 深度学习之二:神经网络的实践与优化
- 9. 深度学习实践:卷积网络
- 10. 深度学习实践:循环神经网络 RNN
- 深度学习算法实践7---前向神经网络算法原理
- TensorFlow深度学习笔记 循环神经网络实践
- 深度学习实践系列(3)- 使用Keras搭建notMNIST的神经网络
- 深度学习:前馈网络
- 深度学习算法实践7---前向神经网络算法原理
- 【原创 深度学习与TensorFlow 动手实践系列 - 2】第二课:传统神经网络
- 深度学习入门实践_十行搭建手写数字识别神经网络
- 深度学习算法实践3---神经网络常用操作实现
- TensorFlow深度学习笔记 循环神经网络实践
- 9. 深度学习实践:卷积网络(续)
- arxiv | 技术概述深度学习:详解前馈、卷积和循环神经网络
- 深度学习算法实践3---神经网络常用操作实现