10. 深度学习实践:循环神经网络 RNN
2018-01-24 00:32
856 查看
循环神经网络(recurrent neural network,RNN)(1986),一类用于处理序列数据的NN。正如卷积网络可很容易地扩展到具有很大宽度和高度的图像,RNN可以很容易扩展到更长的序列、大多数RNN也可处理可变长度的序列。
在模型的不同部分共享参数。能够使得模型扩展到不同形式的样本并进行泛化。CNN中如何共享参数已经知道了,本节将看到如何在RNN上应用该思想。
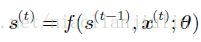
基本上任何涉及循环的函数可以被认为是一个循环神经网络。
为了表明状态是网络的隐藏单元,我们使用变量h代表状态重写上式:
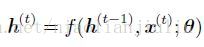
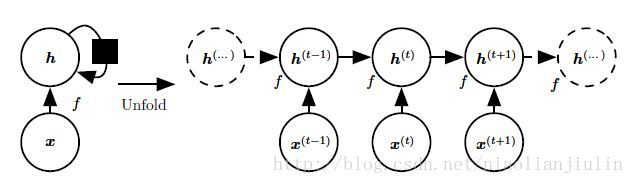
黑色方块表示单个时间步。左部是回路原理图,右部是展开的计算图,展开图的大小取决于序列长度。我们可以在每个时间步使用相同参数的相同转移函数f,不需要在所有可能时间步学习独立的模型。
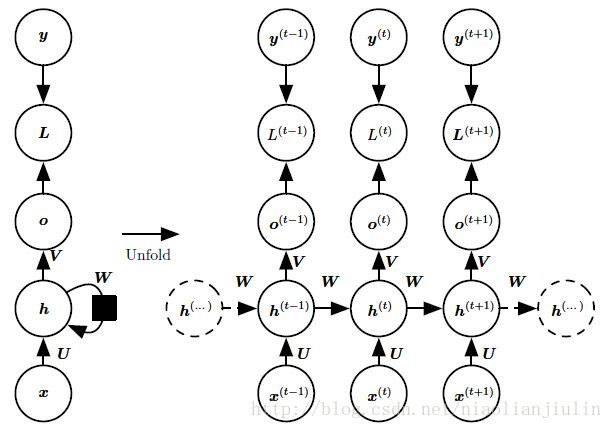
可以看到,参数在每个时间步共享的。该图中,每个时间步都有输出,并且隐藏单元之间有循环连接的循环网络。这是一种设计模式。
第2种模式:每个时间步都产生一个输出,只有当前时刻的输出到下个时刻的隐藏单元之间有循环连接的循环网络。如图示:
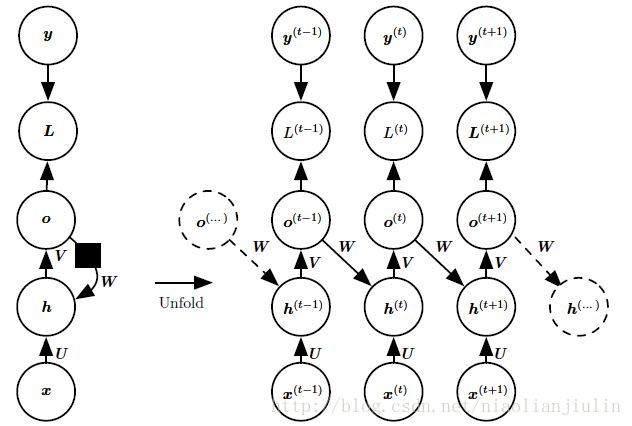
o是允许传播到未来的唯一信息。此处没有从h 前向传播的直接连接。之前的h 仅通过产生的预测间接地连接到当前。o 通常缺乏过去的重要信息,除非它非常高维且内容丰富。这使得该图中的RNN不那么强大,但是它更容易训练,因为每个时间步与其他时间步分离训练,允许训练期间更多的并行化。
第3中模式:隐藏单元之间存在循环连接,但读取整个序列后产生单个输出的循环网络。如下图示:
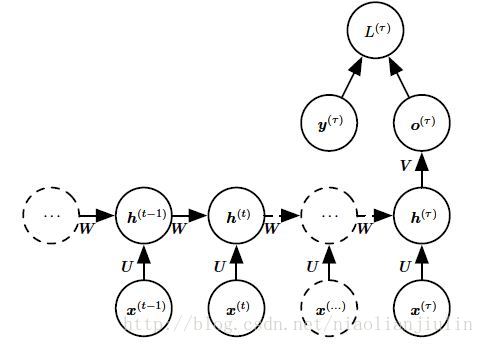
综上,第一种模式最常用,以下讨论主要基于此展开。
RNN的前向传播公式:
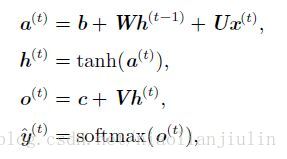
损失函数为:
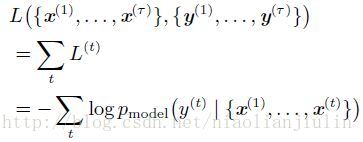
计算这个损失函数对各个参数的梯度是昂贵的操作。梯度计算涉及执行一次前向传播(如在展开图中从左到右的传播),接着是由右到左的反向传播。运行时间是O(t),并且不能通过并行化来降低,因为前向传播图是固有循序的。每个时间步只能一前一后地计算。前向传播中的各个状态必须保存,直到它们反向传播中被再次使用,因此内存代价也是O(t)。应用于展开图且代价为O(t) 的反向传播算法称为通过时间反向传播(back-propagation through time,BPTT)
从输出导致循环连接的模型可用Teacher Forcing进行训练。使用Teacher Forcing的最初动机:为了在缺乏隐藏到隐藏连接的模型中避免通过时间反向传播。
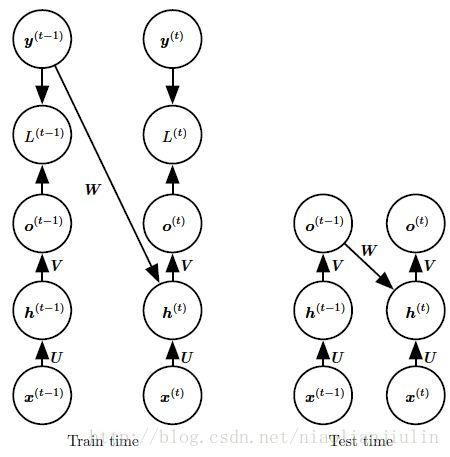
Teacher Forcing是一种训练技术,适用于输出与下一时间步的隐藏状态存在连接的RNN。(左) 训练时,我们将训练集中正确的输出y(t) 反馈到h(t+1)。(右) 当模型部署后,真正的输出通常是未知的。在这种情况下,我们用模型的输出o(t) 近似正确的输出y(t),并反馈回模型。
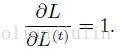
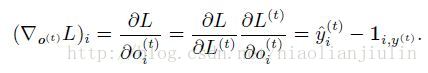
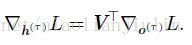
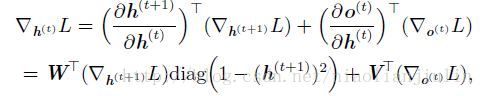
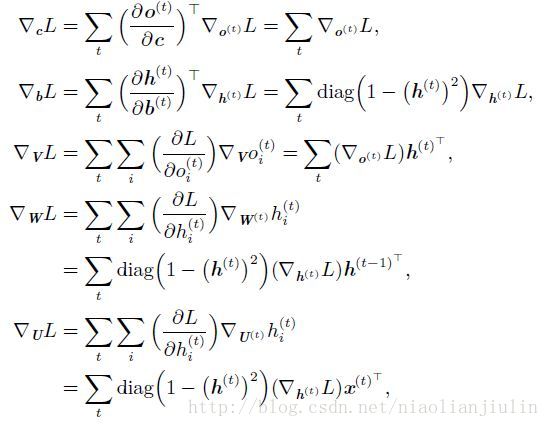
部分章节不展开。仅知其名。
(作者建议不要将递归神经网络缩写为RNN,以免与循环神经网络混淆)
存在多种同时构建粗细时间尺度的策略。这些策略包括:在时间轴增加跳跃连接,渗漏单元使用不同时间常数整合信号,并去除一些用于建模细粒度时间尺度的连接。
像渗漏单元一样,门控RNN想法也是基于生成通过时间的路径,其中导数既不消失也不发生爆炸。渗漏单元通过手动选择常量的连接权重或参数化的连接权重来达到这一目的。门控RNN将其推广为在每个时间步都 可变的连接权重。
渗漏单元允许网络在较长持续时间内积累信息(诸如用于特定特征或类的线索)。然而,一旦该信息被使用,让神经网络遗忘旧的状态可能是有用的。例如,如果一个序列是由子序列组成,我们希望渗漏单元能在各子序列内积累线索,我们需要将状态设置为0以 忘记旧状态 的机制。我们希望神经网络学会决定何时清除状态,而不是手动决定。这就是门控RNN要做的事。
LSTM中的单个细胞的结构是:
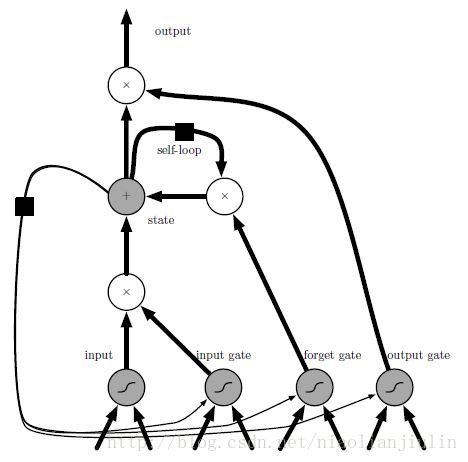
下面的两个输入,均是h(t−1)和x(t)。每个细胞,属于基本架构中的隐藏到隐藏那块的细节化描述。
遗忘门:
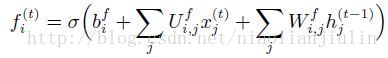
内部状态:
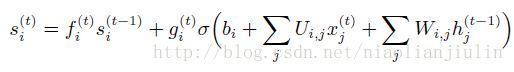
外部输入门:
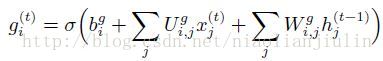
输出:

q(t)i代表输出门。门可以控制开关。里面用到了sigmoid函数。
LSTM网络比简单的循环架构更易于学习长期依赖。引入自循环的巧妙构思,以产生梯度长时间持续流动的路径。一个关键扩展是使自循环的权重视上下文而定,而不是固定的。
引导信息流的正则化
神经网络擅长存储隐性知识,但是他们很难记住事实。2014年有人推测这是因为神经网络缺乏工作存储(working memory) 系统,即类似人类为实现一些目标而明确保存和操作相关信息片段的系统。
为此,2014年引入了记忆网络。2014年出现了神经网络图灵机,不需要明确的监督指示采取哪些行动而能学习从记忆单元读写任意内容,允许端到端的训练。长期以来推理能力被认为是重要的,而不是对输入做出自动的、直观的反应。
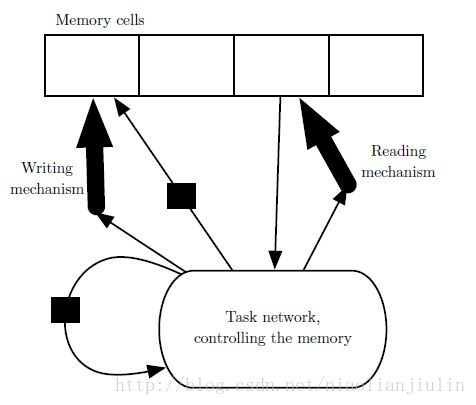
设计架构很像一个冯诺依曼架构的计算机。然而控制器由NN担当。想法非常nice。
在模型的不同部分共享参数。能够使得模型扩展到不同形式的样本并进行泛化。CNN中如何共享参数已经知道了,本节将看到如何在RNN上应用该思想。
1. 计算图展开
考虑由外部信号x(t)驱动的动态系统:基本上任何涉及循环的函数可以被认为是一个循环神经网络。
为了表明状态是网络的隐藏单元,我们使用变量h代表状态重写上式:
黑色方块表示单个时间步。左部是回路原理图,右部是展开的计算图,展开图的大小取决于序列长度。我们可以在每个时间步使用相同参数的相同转移函数f,不需要在所有可能时间步学习独立的模型。
2. 循环神经网络
第一种经典常用架构是:可以看到,参数在每个时间步共享的。该图中,每个时间步都有输出,并且隐藏单元之间有循环连接的循环网络。这是一种设计模式。
第2种模式:每个时间步都产生一个输出,只有当前时刻的输出到下个时刻的隐藏单元之间有循环连接的循环网络。如图示:
o是允许传播到未来的唯一信息。此处没有从h 前向传播的直接连接。之前的h 仅通过产生的预测间接地连接到当前。o 通常缺乏过去的重要信息,除非它非常高维且内容丰富。这使得该图中的RNN不那么强大,但是它更容易训练,因为每个时间步与其他时间步分离训练,允许训练期间更多的并行化。
第3中模式:隐藏单元之间存在循环连接,但读取整个序列后产生单个输出的循环网络。如下图示:
综上,第一种模式最常用,以下讨论主要基于此展开。
RNN的前向传播公式:
损失函数为:
计算这个损失函数对各个参数的梯度是昂贵的操作。梯度计算涉及执行一次前向传播(如在展开图中从左到右的传播),接着是由右到左的反向传播。运行时间是O(t),并且不能通过并行化来降低,因为前向传播图是固有循序的。每个时间步只能一前一后地计算。前向传播中的各个状态必须保存,直到它们反向传播中被再次使用,因此内存代价也是O(t)。应用于展开图且代价为O(t) 的反向传播算法称为通过时间反向传播(back-propagation through time,BPTT)
2.1 Teacher Focing
消除隐藏到隐藏循环(第2种模式)的优点在于,任何基于比较时刻t 的预测和时刻t 的训练目标的损失函数中的所有时间步都解耦了。因此训练可以并行化,即在各时刻t 分别计算梯度。因为训练集提供输出的理想值,所以没有必要先计算前一时刻的输出。从输出导致循环连接的模型可用Teacher Forcing进行训练。使用Teacher Forcing的最初动机:为了在缺乏隐藏到隐藏连接的模型中避免通过时间反向传播。
Teacher Forcing是一种训练技术,适用于输出与下一时间步的隐藏状态存在连接的RNN。(左) 训练时,我们将训练集中正确的输出y(t) 反馈到h(t+1)。(右) 当模型部署后,真正的输出通常是未知的。在这种情况下,我们用模型的输出o(t) 近似正确的输出y(t),并反馈回模型。
2.2 计算梯度
无需特殊对待,仍是反向传播思想。部分章节不展开。仅知其名。
3. 双向RNN
4. 编解码的序列到序列
5. 深度RNN
6. 递归神经网络
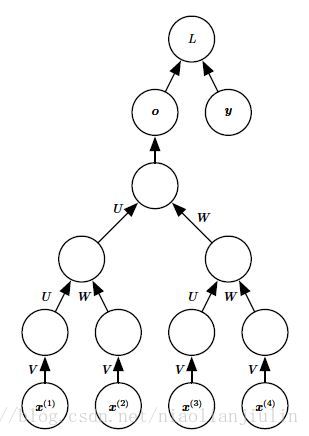
递归神经网络代表循环网络的另一个扩展,它被构造为深的树状结构而不是RNN的链状结构,因此是不同类型的计算图。如下图示:(作者建议不要将递归神经网络缩写为RNN,以免与循环神经网络混淆)
7. 长期依赖
长期依赖:经过许多阶段传播后的梯度倾向于消失(大部分时间)或爆炸(很少,但对优化过程影响很大)。循环神经网络所使用的函数组合有点像矩阵乘法,连乘后导致不与最大特征向量对齐的部分最终丢弃。(此前已讨论过)8. 回声状态网络
9. 渗漏单元和其他多时间尺度的策略
处理长期依赖的一种方法是设计工作在多个时间尺度的模型,使模型的某些部分在细粒度时间尺度上操作并能处理小细节,而其他部分在粗时间尺度上操作并能把遥远过去的信息更有效地传递过来。存在多种同时构建粗细时间尺度的策略。这些策略包括:在时间轴增加跳跃连接,渗漏单元使用不同时间常数整合信号,并去除一些用于建模细粒度时间尺度的连接。
10. LSTM、门控RNN
实际应用中比较有效的序列模型称为门控RNN (gated RNN)。包括基于长短期记忆(long short-term memory,LSTM)和基于门控循环单元(gated recurrent unit,GRU)的网络。像渗漏单元一样,门控RNN想法也是基于生成通过时间的路径,其中导数既不消失也不发生爆炸。渗漏单元通过手动选择常量的连接权重或参数化的连接权重来达到这一目的。门控RNN将其推广为在每个时间步都 可变的连接权重。
渗漏单元允许网络在较长持续时间内积累信息(诸如用于特定特征或类的线索)。然而,一旦该信息被使用,让神经网络遗忘旧的状态可能是有用的。例如,如果一个序列是由子序列组成,我们希望渗漏单元能在各子序列内积累线索,我们需要将状态设置为0以 忘记旧状态 的机制。我们希望神经网络学会决定何时清除状态,而不是手动决定。这就是门控RNN要做的事。
10.1 LSTM
基本架构图:LSTM中的单个细胞的结构是:
下面的两个输入,均是h(t−1)和x(t)。每个细胞,属于基本架构中的隐藏到隐藏那块的细节化描述。
遗忘门:
内部状态:
外部输入门:
输出:
q(t)i代表输出门。门可以控制开关。里面用到了sigmoid函数。
LSTM网络比简单的循环架构更易于学习长期依赖。引入自循环的巧妙构思,以产生梯度长时间持续流动的路径。一个关键扩展是使自循环的权重视上下文而定,而不是固定的。
10.2 其他门控RNN
LSTM架构中哪些部分是真正必须的?还可以设计哪些其他成功架构允许网络动态地控制时间尺度和不同单元的遗忘行为?2014-2015年出现的GRU,门控循环单元。其和LSTM有设计上的不同,但师出同门。11. 优化长期依赖
截断梯度引导信息流的正则化
12. 外显记忆
AI需要知识并且可以通过学习获取知识,这已促使大型深度架构的发展。然而,存在不同种类的知识。有些知识是隐含的、潜意识的并且难以用语言表达。神经网络擅长存储隐性知识,但是他们很难记住事实。2014年有人推测这是因为神经网络缺乏工作存储(working memory) 系统,即类似人类为实现一些目标而明确保存和操作相关信息片段的系统。
为此,2014年引入了记忆网络。2014年出现了神经网络图灵机,不需要明确的监督指示采取哪些行动而能学习从记忆单元读写任意内容,允许端到端的训练。长期以来推理能力被认为是重要的,而不是对输入做出自动的、直观的反应。
设计架构很像一个冯诺依曼架构的计算机。然而控制器由NN担当。想法非常nice。
本章小结
RNN提供了将DL扩展到序列数据的一种方法,其是DL工具箱中最后一个主要的工具。后续关注:如何选择和使用这些工具,如何在真实世界的任务中应用它们。
相关文章推荐
- 深度学习笔记(七) RNN循环神经网络
- 深度学习框架TensorFlow学习与应用(七)——循环神经网络(RNN)应用于MNIST数据集分类
- TensorFlow深度学习笔记 循环神经网络实践
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
- MXNet动手学深度学习笔记:循环神经网络RNN实现
- 【深度学习】RNN(循环神经网络)
- 循环神经网络RNN(二)深度学习之父的神经网络第八课(中文字幕)
- [置顶] 【深度学习】RNN循环神经网络Python简单实现
- 深度学习 - 循环神经网络RNN
- 深度学习——循环神经网络/递归神经网络(RNN)及其改进的长短时记忆网络(LSTM)
- 深度学习-note-RNN(循环神经网络)
- 深度学习(08)_RNN-LSTM循环神经网络-03-Tensorflow进阶实现
- 深度学习笔记七:循环神经网络RNN(基本理论)
- 深度学习(08)_RNN-LSTM循环神经网络-03-Tensorflow进阶实现
- 深度学习:循环神经网络RNN
- TensorFlow深度学习笔记 循环神经网络实践
- 王小草【深度学习】笔记第六弹--循环神经网络RNN和LSTM
- 深度学习(Deep Learning)读书思考八:循环神经网络三(RNN应用)
- 【深度学习】RNN(循环神经网络)之LSTM(长短时记忆)
- July深度学习之RNN循环神经网络