reis系列-持久化和同步机制
2018-01-11 14:31
148 查看
1 第一种: RDB持久化方式
1.1概述
默认redis是会以快照的形式将数据持久化到磁盘的(一个二进制文件,dump.rdb,这个文件名字可以指定),在配置文件中的格式是:save N M表示在N秒之内,redis至少发生M次修改则redis抓快照到磁盘。当然我们也可以手动执行save或者bgsave(异步)做快照。
1.2实现机制
当redis需要做持久化时,redis会fork一个子进程;子进程将数据写到磁盘上一个临时RDB文件中;当子进程完成写临时文件后,将原来的RDB替换掉,这样的好处就是可以copy-on-write
1.3 相关配置
redis.conf配置文件: 设置备份到磁盘的时间1)# save "" 默认的备份方式
save 900 1 #900秒内如果超过1个key被修改,则发起快照保存
save 300 10 #300秒内容如超过10个key被修改,则发起快照保存
save 60 10000
2)# The filename where to dump the DB 备份的文件名称
dbfilename dump.rdb
3)# Note that you must specify a directoryhere, not a file name.
dir ./
(一) 快照保存为rdb文件过程:
1. redis调用fork,现在有了子进程和父进程。
2. 父进程继续处理client请求,子进程负责将内存内容写入到临时文件。由于os的写时复制机制(copy
on write)父子进程会共享相同的物理页面,当父进程处理写请求时os会为父进程要修改的页面创建副本,而不是写共享的页面。所以子进程的地址空间内的数据是fork时刻整个数据库的一个快照。
3. 当子进程将快照写入临时文件完毕后,用临时文件替换原来的快照文件,然后子进程退出(fork一个进程入内在也被复制了,即内存会是原来的两倍)。
client 也可以使用save或者bgsave命令通知redis做一次快照持久化。save操作是在主线程中保存快照的,由于redis是用一个主线程来处理所有 client的请求,这种方式会阻塞所有client请求。所以不推荐使用。另一点需要注意的是,每次快照持久化都是将内存数据完整写入到磁盘一次,并不是增量的只同步脏数据。如果数据量大的话,而且写操作比较多,必然会引起大量的磁盘io操作,可能会严重影响性能。
另外由于快照方式是在一定间隔时间做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。如果应用要求不能丢失任何修改的话,可以采用aof持久化方式。下面介绍:
其实就是主从同步机制 就是aof策略。
(二)Append-only file
aof 比快照方式有更好的持久化性,是由于在使用aof持久化方式时,redis会将每一个收到的写命令都通过write函数追加到文件中(默认是appendonly.aof)。当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。当然由于os会在内核中缓存 write做的修改,所以可能不是立即写到磁盘上。这样aof方式的持久化也还是有可能会丢失部分修改。不过我们可以通过配置文件告诉redis我们想要通过fsync函数强制os写入到磁盘的时机。有三种方式如下(默认是:每秒fsync一次):
| appendonly yes #启用aof持久化方式 # appendfsync always #每次收到写命令就立即强制写入磁盘,最慢的,但是保证完全的持久化,不推荐使用 appendfsync everysec #每秒钟强制写入磁盘一次,在性能和持久化方面做了很好的折中,推荐 # appendfsync no #完全依赖os,性能最好,持久化没保证 |
test 100就够了。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。收到此命令redis将使用与快照类似的方式将内存中的数据以命令的方式保存到临时文件中,最后替换原来的文件。具体过程如下:
1. redis调用fork ,现在有父子两个进程
2. 子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令
3. 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。
4. 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。
5. 现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。
需要注意到是重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
RDB方法在redis异常死掉时,最近的数据会丢失(丢失数据的多少视你save策略的配置),所以这是它最大的缺点,当业务量很大时,丢失的数据是很多的。 Append-only方法可以做到全部数据不丢失,但redis的性能就要差些。AOF就可以做到全程持久化,只需要在配置文件中开启(默认是no),appendonly yes开启AOF之后,redis每执行一个修改数据的命令,都会把它添加到aof文件中,当redis重启时,将会读取AOF文件进行“重放”以恢复到red 11169 is关闭前的最后时刻。 redis启动装载: AOF优先于RDB RDB性能优于AOF,因为里面没有重复 Redis一次性将数据加载到内存中,一次性预热
介绍了这两种机制,下面说说主从同步。
Redis的主从同步机制可以确保redis的master和slave之间的数据同步。按照同步内容的多少可以分为全同步和部分同步;按照同步的时机可以分为slave刚启动时的初始化同步和正常运行过程中的数据修改同步;本文将对这两种机制的流程进行分析。
全备份过程中,在slave启动时,会向其master发送一条SYNC消息,master收到slave的这条消息之后,将可能启动后台进程进行备份,备份完成之后就将备份的数据发送给slave,初始时的全同步机制是这样的:
(1)slave启动后向master发送同步指令SYNC,master接收到SYNC指令之后将调用该命令的处理函数syncCommand()进行同步处理;
(2)在函数syncCommand中,将调用函数rdbSaveBackground启动一个备份进程用于数据同步,如果已经有一个备份进程在运行了,就不会再重新启动了。
(3)备份进程将执行函数rdbSave()完成将redis的全部数据保存为rdb文件。
(4)在redis的时间事件函数serverCron(redis的时间处理函数是指它会定时被redis进行操作的函数)中,将对备份后的数据进行处理,在serverCron函数中将会检查备份进程是否已经执行完毕,如果备份进程已经完成备份,则调用函数backgroundSaveDoneHandler完成后续处理。
(5)在函数backgroundSaveDoneHandler中,首先更新master的各种状态,例如,备份成功还是失败,备份的时间等等。然后调用函数updateSlavesWaitingBgsave,将备份的rdb数据发送给等待的slave。
(6)在函数updateSlavesWaitingBgsave中,将遍历所有的等待此次备份的slave,将备份的rdb文件发送给每一个slave。另外,这里并不是立即就把数据发送过去,而是将为每个等待的slave注册写事件,并注册写事件的响应函数sendBulkToSlave,即当slave对应的socket能够发送数据时就调用函数sendBulkToSlave(),实际发送rdb文件的操作都在函数sendBulkToSlave中完成。
(7)sendBulkToSlave函数将把备份的rdb文件发送给slave。
上述函数调用过程如下图1所示:
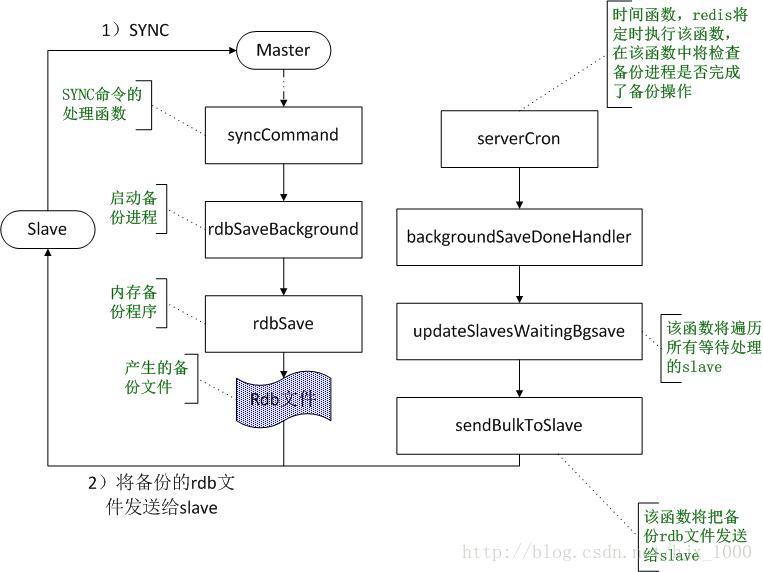
图1 redis全备份时master部分的的函数调用过程
二、数据修改操作的同步
Redis的正常部署中一般都是一个master用于写操作,若干个slave用于读操作,另外定期的数据备份操作也是单独选址一个slave完成,这样可以最大程度发挥出redis的性能。在部署完成,各master\slave程序启动之后,首先进行第一阶段初始化时的全同步操作,全同步操作完成之后,后续所有写操作都是在master上进行,所有读操作都是在slave上进行,因此用户的写操作需要及时扩散到所有的slave以便保持数据最大程度上的同步。Redis的master-slave进程在正常运行期间更新操作(包括写、删除、更改操作)的同步方式如下:
(1)master接收到一条用户的操作后,将调用函数call函数来执行具体的操作函数(此过程可参考另一文档《redis命令执行流程分析》),在该函数中首先通过proc执行操作函数,然后将判断操作是否需要扩散到各slave,如果需要则调用函数propagate()来完成此操作。
(2)propagate()函数完成将一个操作记录到aof文件中或者扩散到其他slave中;在该函数中通过调用feedAppendOnlyFile()将操作记录到aof中,通过调用replicationFeedSlaves()将操作扩散到各slave中。
(3)函数feedAppendOnlyFile()中主要保存操作到aof文件,在该函数中首先将操作转换成redis内部的协议格式,并以字符串的形式存储,然后将字符串存储的操作追加到aof文件后。
(4)函数replicationFeedSlaves()主要将操作扩散到每一个slave中;在该函数中将遍历自己下面挂的每一个slave,以此对每个slave进行如下两步的处理:将slave的数据库切换到本操作所对应的数据库(如果slave的数据库id与当前操作的数据id不一致时才进行此操作);将命令和参数按照redis的协议格式写入到slave的回复缓存中。写入切换数据库的命令时将调用addReply,写入命令和参数时将调用addReplyMultiBulkLen和addReplyBulk,函数addReplyMultiBulkLen和addReplyBulk最终也将调用函数addReply。
(5)在函数addReply中将调用prepareClientToWrite()设置slave的socket写入事件处理函数sendReplyToClient(通过函数aeCreateFileEvent进行设置),这样一旦slave对应的socket发送缓存中有空间写入数据,即调用sendReplyToClient进行处理。
(6)函数sendReplyToClient()的主要功能是将slave中要发送的数据通过socket发出去。
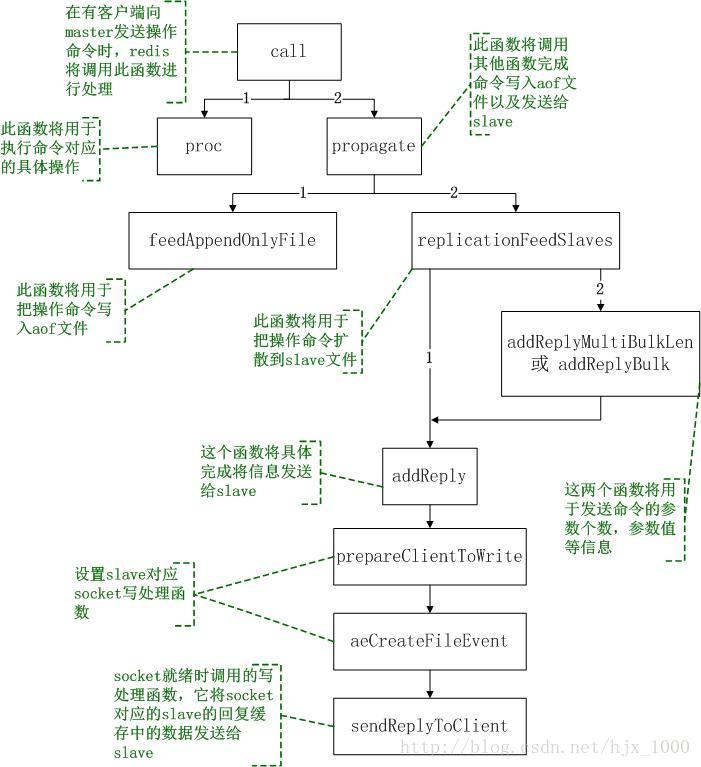
图2、redis操作过程中数据同步的函数调用关系
注意问题:
当主服务器不进行持久化时复制的安全性

相关文章推荐
- 【Linux基础系列之】同步机制介绍
- Innodb 锁系列1 同步机制
- 淘淘商城系列——添加商品同步到索引库以及消息机制测试
- Java的多线程机制系列:(三)synchronized的同步原理
- java多线程、并发系列之 (synchronized)同步与加锁机制
- 音视频同步系列文章之-----Windows同步机制
- MySQL系列:innodb源码分析之线程并发同步机制
- Linux内核源码系列(二):探究内核基础层数据结构,同步机制的应用
- MySQL系列:innodb源码分析之线程并发同步机制
- MySQL系列:innodb源代码分析之线程并发同步机制
- 并发编程实战学习笔记(十一)-原子变量与非阻塞同步机制
- java 同步机制
- GoldenGate 12.3 MA架构介绍系列(2) - 数据同步测试
- Java线程同步机制_动力节点Java学院整理
- 多线程系列001---Volatile总结之同步问题
- WPF快速入门系列(3)——深入解析WPF事件机制
- memcached源码剖析系列之内存存储机制(二)
- Linux内核的同步机制(转)
- ASIHTTPRequest系列(一):同步和异步请求 .
- Android事件处理机制系列-----------Touch事件处理机制