损失函数改进总结
2018-01-11 14:00
120 查看
深度学习交流QQ群:116270156
这篇博客主要列个引导表,简单介绍在深度学习算法中损失函数可以改进的方向,并给出详细介绍的博客链接,会不断补充。
1、Large Marge Softmax Loss
ICML2016提出的Large Marge Softmax Loss(L-softmax)通过在传统的softmax loss公式中添加参数m,加大了学习的难度,逼迫模型不断学习更具区分性的特征,从而使得类间距离更大,类内距离更小。核心内容可以看下图:
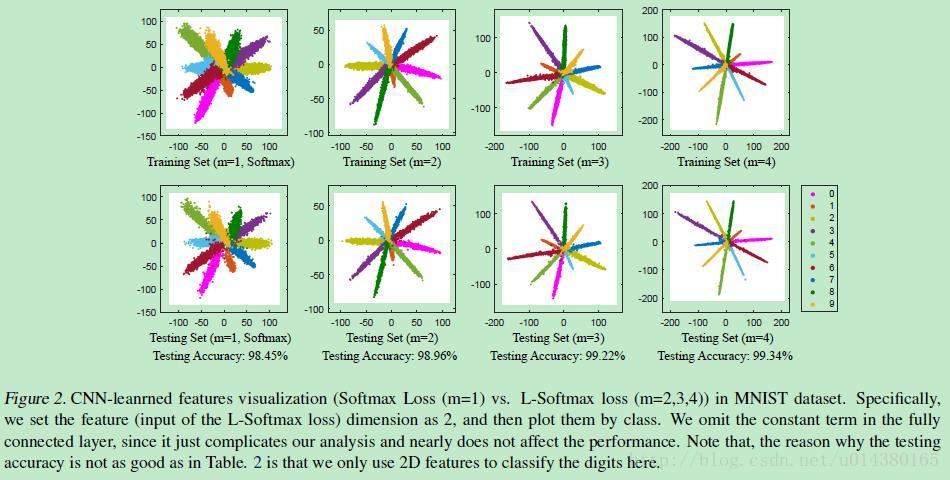
详细了解可以参看:损失函数改进之Large-Margin Softmax Loss
2、Center Loss
ECCV2016提出的center loss是通过将特征和特征中心的距离和softmax loss一同作为损失函数,使得类内距离更小,有点L1,L2正则化的意思。核心内容如下图所示:
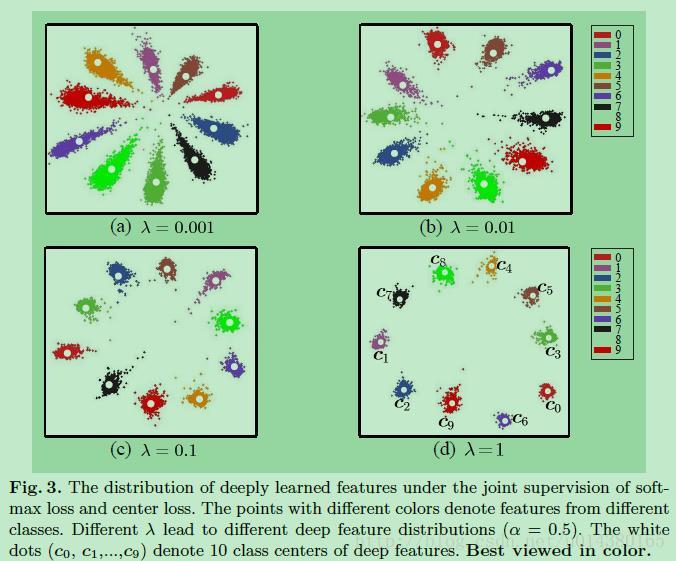
详细了解可以参看:损失函数改进之Center Loss
3、A-softmax Loss
CVPR2017提出的A-softmax loss(angular softmax loss)用来改进原来的softmax loss。A-softmax loss简单讲就是在large margin softmax loss的基础上添加了两个限制条件||W||=1和b=0,使得预测仅取决于W和x之间的角度。核心思想可以参看下面这个图。
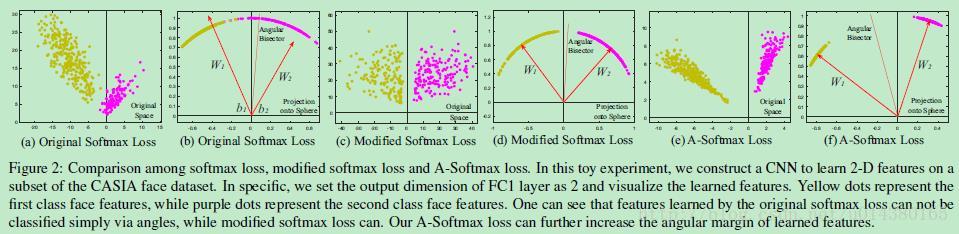
详细了解可以参看:损失函数改进方法之A-softmax loss
4、Focal Loss
这是Facebook的RBG和Kaiming大神前天放在arxiv的新作,立马就引来了业界的围观,在COCO数据集上的AP和速度都有明显提升。核心思想在于概括了object detection算法中proposal-free一类算法准确率不高的原因在于:类别不均衡。于是在传统的交叉熵损失上进行修改得到Focal Loss。详细了解可以参看:Focal
Loss
这篇博客主要列个引导表,简单介绍在深度学习算法中损失函数可以改进的方向,并给出详细介绍的博客链接,会不断补充。
1、Large Marge Softmax Loss
ICML2016提出的Large Marge Softmax Loss(L-softmax)通过在传统的softmax loss公式中添加参数m,加大了学习的难度,逼迫模型不断学习更具区分性的特征,从而使得类间距离更大,类内距离更小。核心内容可以看下图:
详细了解可以参看:损失函数改进之Large-Margin Softmax Loss
2、Center Loss
ECCV2016提出的center loss是通过将特征和特征中心的距离和softmax loss一同作为损失函数,使得类内距离更小,有点L1,L2正则化的意思。核心内容如下图所示:
详细了解可以参看:损失函数改进之Center Loss
3、A-softmax Loss
CVPR2017提出的A-softmax loss(angular softmax loss)用来改进原来的softmax loss。A-softmax loss简单讲就是在large margin softmax loss的基础上添加了两个限制条件||W||=1和b=0,使得预测仅取决于W和x之间的角度。核心思想可以参看下面这个图。
详细了解可以参看:损失函数改进方法之A-softmax loss
4、Focal Loss
这是Facebook的RBG和Kaiming大神前天放在arxiv的新作,立马就引来了业界的围观,在COCO数据集上的AP和速度都有明显提升。核心思想在于概括了object detection算法中proposal-free一类算法准确率不高的原因在于:类别不均衡。于是在传统的交叉熵损失上进行修改得到Focal Loss。详细了解可以参看:Focal
Loss

相关文章推荐
- 机器学习(4)-理解SVM的损失函数和梯度表达式的实现+编程总结
- 软件界面交互和易用性改进总结
- bug统计分析---严重级别( 统计分析的目的: 总结和分析每个季度在测试团队中所处的级别,用于改进之后的工作)
- DB2开发性能改进总结
- 人月神话:软件界面交互和易用性改进总结
- 软件界面交互和易用性改进总结[zz]
- 软件界面交互和易用性改进总结
- 软件界面交互和易用性改进总结
- Java并发编程总结4——ConcurrentHashMap在jdk1.8中的改进
- Java并发编程总结4——ConcurrentHashMap在jdk1.8中的改进
- 【图像处理】关于车辆检测算法的总结与改进探讨
- 李航统计学习方法-改进的迭代尺度算法(IIS)总结
- (6)MyBatis小总结:一个简单的例子--接口编程改进
- 项目总结(二)——改进的延时函数Delay
- 深度学习中的损失函数总结
- 软件界面交互和易用性改进总结
- 周赛 Hd2270+总结改进
- 人月神话:软件界面交互和易用性改进总结
- 【过程改进】总结大中小型项目的git流程
- 对于SVM和softmax的损失函数总结(基于cs231n)