Flume(一)简介
2018-01-10 17:40
393 查看
前言:
Flume是一个数据采集框架,因此要牢牢把握住数据的走向。即:1、数据可以从哪些地方采集? source
2、数据中间可以缓存在哪些地方? channel
3、数据可以存储在哪些地方? sink
4、数据采集后缓存前可以对数据进行怎样的加工? flume interceptor
5、数据采集后缓存在哪个channel? channel selector
6、数据缓存后如何被sink消费? sink processor
一、Flume简介
1、Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务。Flume只能在unix环境下运行2、Flume基于流式架构,容错性强,也很灵活简单。
二、Flume角色
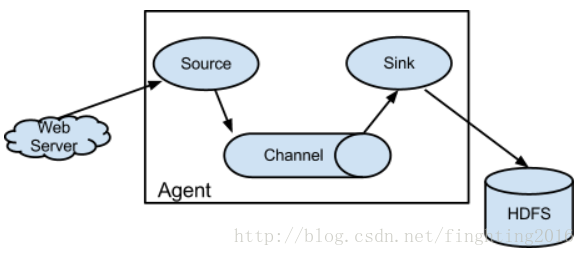
1、event
1、flume的核心是把数据从数据源(source)收集过来,然后将收集到的数据送到指定的目的地(sink)。2、在整个数据的传输过程中,流动的是event,即事务保证是在event级别进行的。
3、为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达sink后,flume在删除自己缓存的数据。
4、那么什么是event呢?
event—–将传输的数据进行封装,是flume传输数据的基本单位。如果是文本文件,通常是一行记录,event也是事务的基本单位。
5、一个完整的event包括header和body。header封装头信息,为map结构;body封装具体的数据,结构为字节数组。
6、header的key非常重要,当sink为hbase时,key决定event流向哪个rowkey;sink为hive时,key决定event流向哪个表;sinke为kafka时,key决定event流向哪个topic/partition;
2、flow
数据流,Event从源点到达目的点的迁移的抽象;3、agent
一个独立的Flume进程,包含组件Source、Channel、Sink;4、source
1、Source用于采集数据,即Source是产生数据流的地方,同时Source会将产生的数据流传输到Channel。2、注意:flume没有hdfs、hive、hbase等相关source,因为flume是数据采集系统,目的就是将数据采集到这些地方。
(注意比较flume和kafka的区别)
3、常用的source有:

5、channel
1、用于桥接Sources和Sinks,类似于一个队列。2、常用的channel有:

6、sink
1、从Channel收集数据,将数据写到目标源(可以是下一个Source,也可以是HDFS或者HBase)。2、常用sink有:

三、Flume拓扑结构


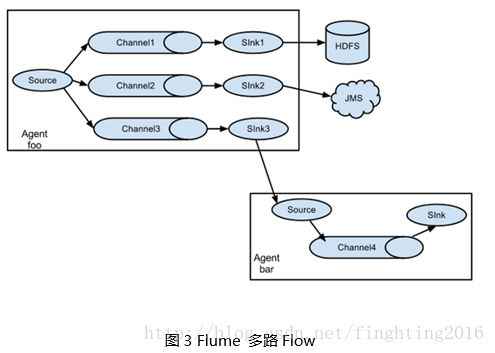
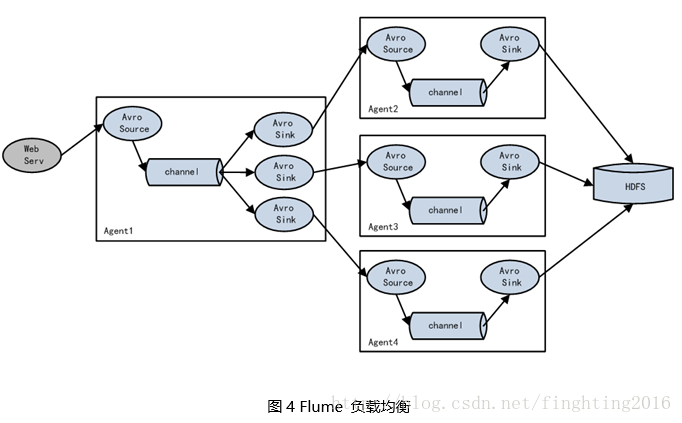
四、Flume传输过程
1、source监控某个文件或数据流,数据源产生新的数据,拿到该数据后,将数据封装在一个Event中,并put到channel后commit提交;2、channel队列先进先出;
3、sink去channel队列中拉取数据,然后写入到HDFS中。
五、Flume部署和配置
1、flume的部署非常简单,只需配置一个文件即可flume-env.sh涉及修改项:
export JAVA_HOME=/home/admin/modules/jdk1.8.0_121
六、案例
目标:使用flume监听整个目录的文件步骤:
1)创建配置文件flume-dir.conf
a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = spooldir a3.sources.r3.spoolDir = /home/admin/modules/apache-flume-1.7.0-bin/upload a3.sources.r3.fileSuffix = .COMPLETED a3.sources.r3.fileHeader = true #忽略所有以.tmp结尾的文件,不上传 a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop102:9000/flume/upload/%Y%m%d/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件 a3.sinks.k3.hdfs.rollInterval = 600 a3.sinks.k3.hdfs.rollSize = 134217700 #设置每个文件的滚动大小大概是128M #文件的滚动与Event数量无关 a3.sinks.k3.hdfs.rollCount = 0 #最小冗余数 a3.sinks.k3.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
2)在flume安装目录下执行命令
$ bin/flume-ng agent --conf conf/ --conf-file job/flume-dir.conf --name a3
七、注意
1、关于参数配置:配置source、channel、sink的属性值时,看官方文档。
有些值没有默认值,必须要配置;
有些属性有默认值,需要更改的话再配置
2、命令解析
$ bin/flume-ng agent --conf conf/ --conf-file job/flume-dir.conf --name a3
flume-ng 脚本
agent run a Flume agent
--conf use configs in <conf> directory
--config-file specify a config file (required if -zmissing)
--name the
name of this agent (required)
3、在创建配置文件时,注释要单独写一行,某则会报错 !!!

相关文章推荐
- Cloudera Flume简介
- Flume简介和配置实战
- Flume(一):简介架构
- Flume简介与使用(二)——Thrift Source采集数据
- Flume快速入门(一):背景简介
- Flume NG之Interceptor简介
- flume简介与监听文件目录并sink至hdfs实战
- 1.Apache Flume 简介
- 0125 Flume NG 简介及配置实战
- Flume简介及配置
- Apache Flume 1.7.0 各个模块简介
- Flume NG 简介及配置实战
- flume简介和安装
- Flume 简介(后补)
- Flume快速入门(一):背景简介
- Flume NG 简介及配置实战
- Flume快速入门(一):背景简介
- Apache Flume 简介
- Flume笔记一之简介部署
- 大数据下的日志-flume(一)简介及例子