Python 3.6 字符串操作 实例
2018-01-06 15:50
477 查看
Python 3.6 字符串操作
常见的字符串操作
字符串的格式化
C语言使用函数printf()、sprintf()格式化输出结果,Python也提供了类似的功能。Python将若干值插入带有“%”标记的字符串中,从而可以动态地输出字符串。字符串的格式化语法如下所示。"%s" % str1 "%s %s" % (str1, str2)
【代码说明】第1行代码使用一个值格式化字符串。第2行代码使用多个值格式化字符串,用于替换的值组成一个元组。
下面这段代码演示了字符串的格式化操作:
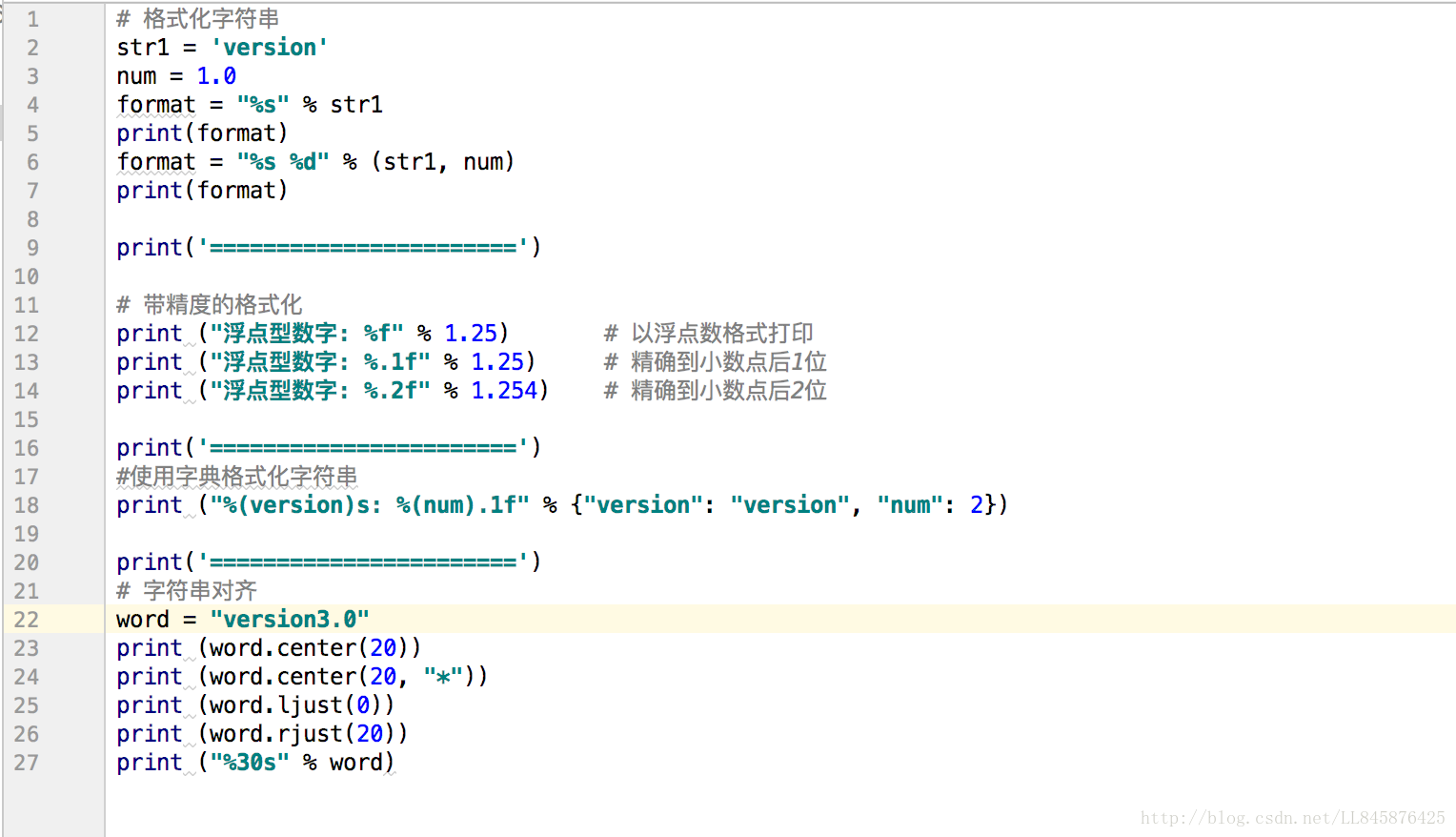
str1 = 'version' num = 1.0 format = "%s" % str1 print(format) format = "%s %d" % (str1, num) print(format)
【代码说明】
第4行代码用变量str1的值替换字符串中的%s。
第5行代码输出结果是“version”。
第6行代码分别用变量str1、num的值替换%s和%d的值。%d表示替换的值为整型。
第7行代码输出结果为“version 1”。
注意 如果要格式化多个值,元组中元素的顺序必须和格式化字符串中替代符的顺序一致,否则,可能出现类型不匹配的问题。如果将上例中的%s和%d调换位置,将抛出如下异常:
TypeError: int argument required
使用%f可以格式化浮点数的精度,根据指定的精度做“四舍五入”。示例如下:
# 带精度的格式化
print ("浮点型数字: %f" % 1.25) # 以浮点数格式打印
print ("浮点型数字: %.1f" % 1.25) # 精确到小数点后1位
print ("浮点型数字: %.2f" % 1.254) # 精确到小数点后2位【代码说明】
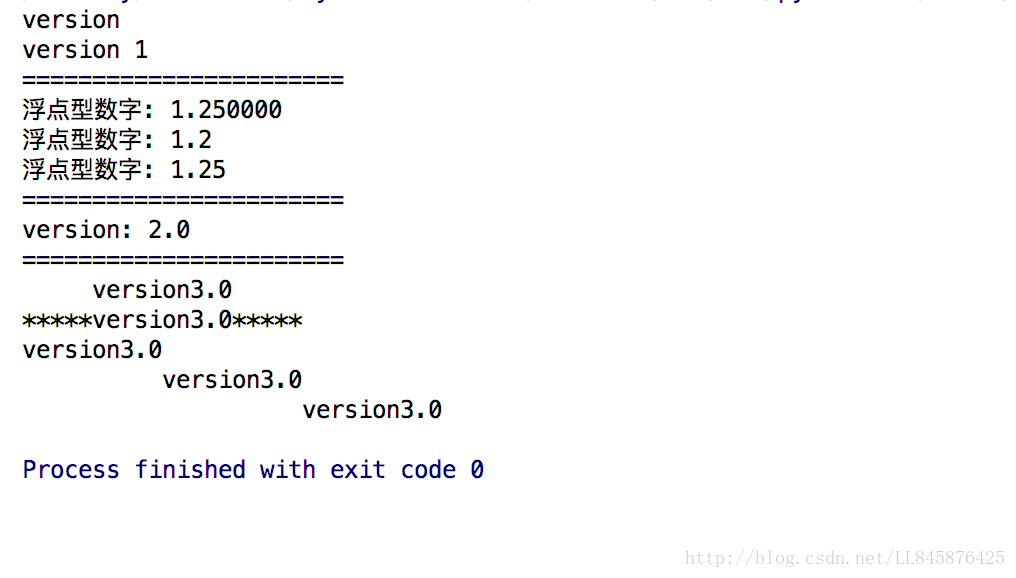
第2行代码格式化浮点数1.25。默认情况下,将输出小数点后6位数字。输出结果:浮点型数字: 1.250000
第3行代码格式化小数点后1位数字,“四舍五入”后的结果为1.3。输出结果:浮点型数字: 1.3
第4行代码格式化小数点后2位数字。输出结果:浮点型数字: 1.25
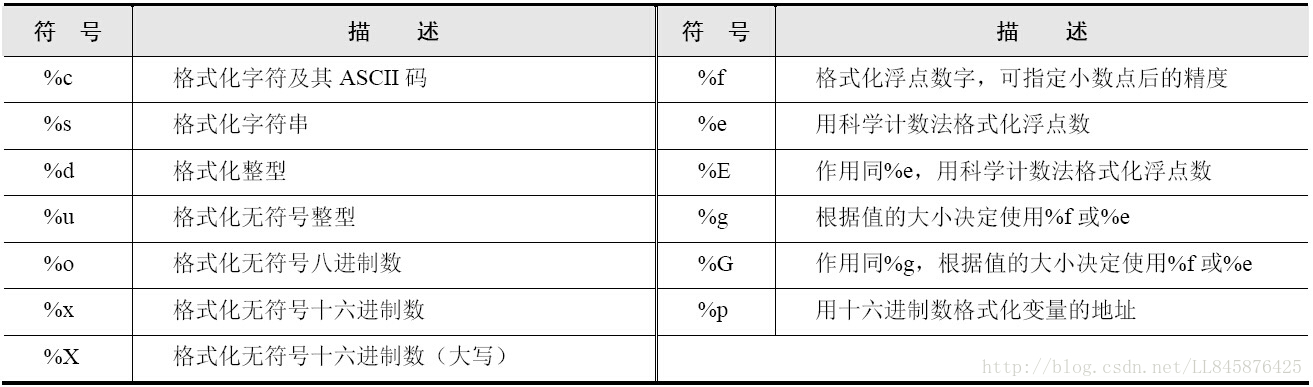
此外,Python还提供了对八进制、十六进制等数字进行格式化的替代符。下表列出了Python中格式化字符串的替代符及其含义。
前面使用了元素格式化多个值,也可以用字典格式化多个值,并指定格式化字符串的名称。下面这段代码说明了字典格式化字符串的用法。
#使用字典格式化字符串
print ("%(version)s: %(num).1f" % {"version": "version", "num": 2})【代码说明】第2行代码定义了一个匿名字典,该字典中的两个value值分别对应字符串中的%(version)s和%(num).1f。输出结果:version:2.0
Python可以实现字符串的对齐操作,类似C语言中的“%[[+/-]n]s”。此外,还提供了字符串对齐的函数。
# 字符串对齐
word = "version3.0"
print (word.center(20))
print (word.center(20, "*"))
print (word.ljust(0))
print (word.rjust(20))
print ("%30s" % word)【代码说明】
第3行代码调用center()输出变量word的值。变量word两侧各输出5个空格。
第4行代码调用center()输出变量word的值,并指定第2个参数的值为“”。变量word两侧各输出5个“”。
第5行代码调用ljust()输出变量word的值,ljust()输出结果左对齐。
第6行代码调用rjust()输出变量word的值,rjust()输出结果右对齐。参数20表示一共输出20个字符,“version3.0”占10个字符,左边填充10个空格。
第7行代码,“%30s”表示先输出30个空格,再输出变量word的值,类似于word.rjust(30)的作用。
全部代码为:
运行结果为:
字符串的转义符
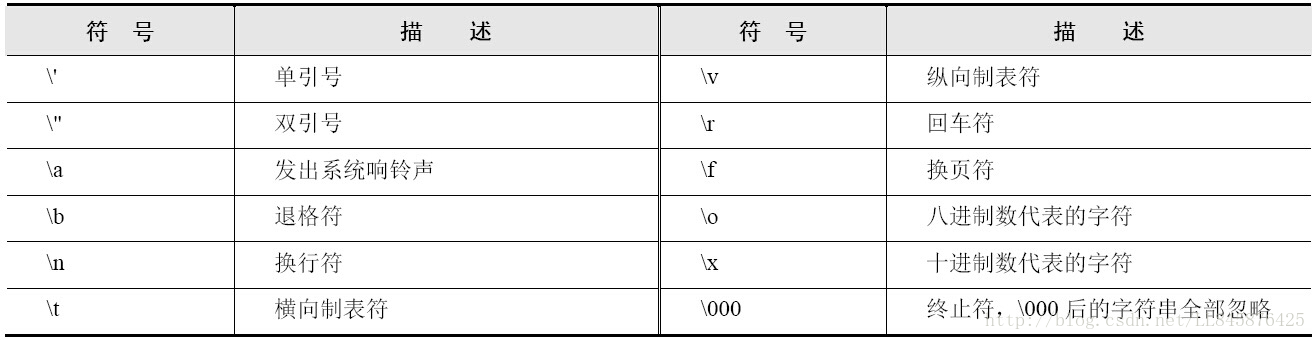
计算机中存在可见字符与不可见字符。可见字符是指键盘上的字母、数字和符号。不可见字符是指换行、回车等字符,对于不可见字符可以使用转义字符来表示。Python中转义字符的用法和Java相同,都是使用“\”作为转义字符。下面这段代码演示了转义字符的使用:
path = 'hello\tworld\n' print(path) print(len(path)) path = r'hello\tworld\n' print(path) print(len(path))
【代码说明】
第2行代码,在“hello”和“world”之间输出制表符,在字符串末尾输出换行符。
第4行代码输出字符串的长度,其中的“\t”、“\n”各占一个字符。输出结果为12。
第5行代码,忽略转义字符的作用,直接输出字符串原始的内容。
第6行代码输出结果:hello\tworld\n
第7行代码输出字符串的长度。输出结果为“14”。
【运行结果】

注意 Python的制表符只占1个字符,而不是2个或4个字符
注意 如果要在字符串中输出“\”,需要使用“\”。
Python还提供了函数strip()、lstrip()、rstrip()去掉字符串中的转义符。
print('===================')
# strip()去掉转义字符
word = '\thello world\n'
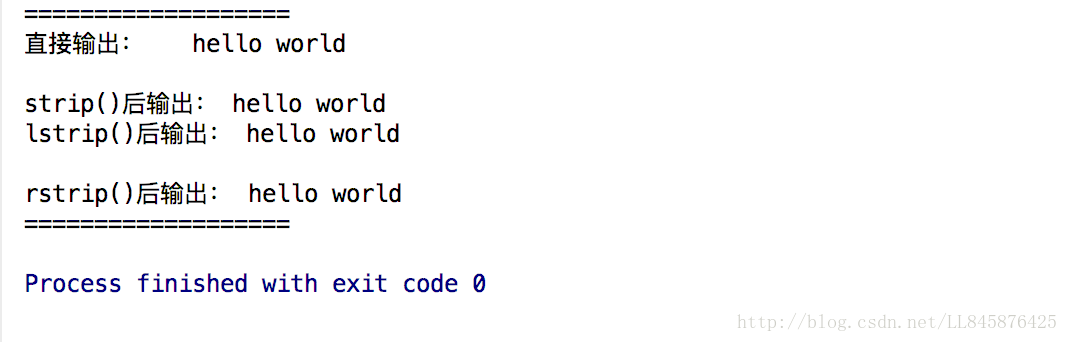
print('直接输出:', word)
print('strip()后输出:', word.strip())
print('lstrip()后输出:', word.lstrip())
print('rstrip()后输出:', word.rstrip())
print('===================')【代码说明】
第4行代码直接输出字符串。
第5行代码调用strip()去除转义字符。
第6行代码调用lstrip()去除字符串前面的转义字符“\t”,字符串末尾的“\n”依然存在。
第7行代码调用rstrip()去除字符串末尾的转义字符“\n”,字符串前面的“\t”依然存在。
字符串的合并
与Java语言一样,Python使用“+”连接不同的字符串。Python会根据“+”两侧变量的类型,决定执行连接操作或加法运算。如果“+”两侧都是字符串类型,则进行连接操作;如果“+”两侧都是数字类型,则进行加法运算;如果“+”两侧是不同的类型,将抛出异常。TypeError: cannot concatenate 'str' and 'int' objects
下面的代码演示了字符串的连接方法:
# 使用 + 链接字符串
print('========# 使用 + 链接字符串==============')
str1 = 'hello'
str2 = 'world'
str3 = 'hello'
str4 = 'china'
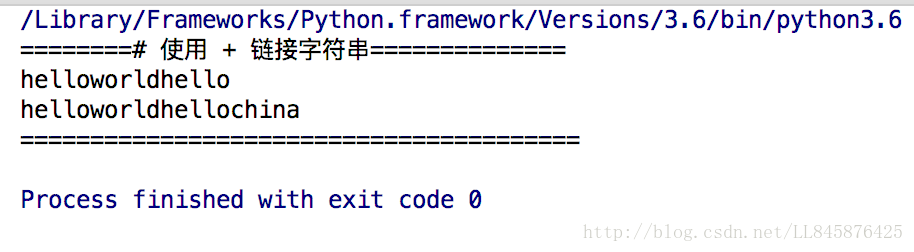
result = str1 + str2 + str3
print(result)
result += str4
print(result)
print('========================================')【代码说明】
第7行代码,把变量str1、str2、str3的值连接起来,并把结果存放在变量result中。
第9行代码,使用运算符“+=”连接变量result和str4。
【运行结果】
可见,使用“+”对多个字符串进行连接稍显烦琐。Python提供了函数join()连接字符串,join()配合列表实现多个字符串的连接十分方便。
代码实例如下:
# 使用join()连接字符串
print('==========# 使用join()连接字符串==========')
strs = ['hello', 'world', 'hello', 'china']
result = ''.join(strs)
print(result)【代码说明】
第2行代码用列表取代变量,把多个字符串存放在列表中。
第3行代码调用join(),每次连接列表中的一个元素。
【运行结果】

reduce()的作用就是对某个变量进行累计。这里可以对字符串进行累计连接,从而实现多个字符串进行连接的功能。
代码实现如下:
# 使用reduce()连接字符串
print('=========# 使用reduce()连接字符串=========')
from functools import reduce
import operator
strs = ['hello', 'world', 'hello', 'china']
result = reduce(operator.add, strs, '')
print(result)
print('========================================')【代码说明】
第3行代码导入模块operator,利用方法add()实现累计连接。
第5行代码调用reduce()实现对空字符串“”的累计连接,每次连接列表strs中的一个元素。
【运行结果】

# 使用 + 链接字符串
print('========# 使用 + 链接字符串==============')
str1 = 'hello'
str2 = 'world'
str3 = 'hello'
str4 = 'china'
result = str1 + str2 + str3
print(result)
result += str4
print(result)
print('========================================')
# 使用join()连接字符串
print('==========# 使用join()连接字符串==========')
strs = ['hello', 'world', 'hello', 'china']
result = ''.join(strs)
print(result)
print('========================================')
# 使用reduce()连接字符串
print('=========# 使用reduce()连接字符串=========')
from functools import reduce
import operator
strs = ['hello', 'world', 'hello', 'china']
result = reduce(operator.add, strs, '')
print(result)
print('========================================')字符串的截取
字符串的截取是实际应用中经常使用的技术,被截取的部分称为“子串”。Java中使用函数substr()获取子串,C#使用函数substring()获取子串。而Python由于内置了序列,可以通过前面介绍的索引、切片获取子串,也可以使用函数split()来获取。字符串也属于序列。下面这段代码使用序列的索引获取子串:
# 使用索引截取子串
print('----------# 使用索引截取子串---------')
word = 'world'
print(word[4])【代码说明】第4行代码,访问字符串第5个字符的值。输出结果为“d”。
【运行结果】

通过切片可以实现对字符串有规律的截取。切片的语法格式如下所示。
string[start : end : step]
【代码说明】其中string表示需要取子串的源字符串变量。[start:end:step]表示从string的第start个索引位置开始到第end个索引之间截取子串,截取的步长是step。即每次截取字符string[start+step],直到第end个索引。索引从0开始计数。
下面这段代码演示了使用切片截取子串的功能:
# 特殊切片截取子串
print('---------# 特殊切片截取子串----------')
str1 = 'hello world'
print(str1[0:3])
print(str1[::2])
print(str1[1::2])
str2 = 'ABCDEFG'
print(str2[:3])
print(str2[3:])
print(str2[::2])
print('-----------------------------------')【代码说明】
第3行代码,截取字符串中第1个字符到第3个字符之间的部分。
第4行代码,[::2]切片省略了开始和结束字符。从字符串的第1个字符开始,以2为步长逐个截取字符。
第5行代码,切片中的数字1表示从字符串的第2个字符开始取字符,数字2表示以2为步长逐个截取字符。
【运行结果】

如果要同时截取多个子串,可以使用函数split()实现。函数split()的声明如下所示。
split([char] [,num])
【代码说明】
参数char表示用于分割的字符,默认的分割字符是空格。
参数num表示分割的次数。如果num等于2,将把源字符串分割为3个子串。默认情况下,将根据字符char在字符串中出现的个数来分割子串。
函数的返回值是由子串组成的列表。
代码如下:
# 使用split()获取子串
print('-----------# 使用split()获取子串-----')
sentence = "Tom said: a,b,c,d."
print('使用空格获取子串:', sentence.split())
print('使用逗号获取子串:', sentence.split(','))
print('使用逗号获取3个子串:', sentence.split(',', 2))
sentence1 = 'Uzi tell us : he is king and said : A, B, C, D.'
print('使用空格获取子串:', sentence1.split())
print('使用逗号获取子串:', sentence1.split(','))
print('使用空格获取4个子串:', sentence1.split(' ',3))
print('-----------------------------------')【代码说明】
第3行代码根据空格来获取子串。字符串sentence中有5个空格,将返回由6个子串组成的列表。
第4行代码根据逗号来获取子串。字符串sentence中有3个空格,将返回由4个子串组成的列表。
第5行代码根据逗号来分割字符串,并把字符串sentence分割为3个子串。
【运行结果】

字符串连接后,Python将分配新的空间给连接后的字符串,源字符串保持不变。
# 字符串连接后,Python将分配新的空间给连接后的字符串,源字符串保持不变。
print('字符串连接后,Python将分配新的空间给连接后的字符串,源字符串保持不变。')
str3 = "a"
print(id(str3))
print(id(str3 + "b"))
print('-------------------------------------')【代码说明】
第2行代码输出str1的内部标识。输出结果为“4337916312”。
第3行代码,进行字符串连接,新的字符串将获得新的标识。输出结果为“4337800168”。
【运行结果】

字符串的比较
Java使用equals()比较两个字符串的内容,Python直接使用“==”“!=”操作符比较两个字符串的内容。如果比较的两个变量的类型不相同,比较的内容也不相同。下面这段代码演示了Python中字符串的比较:
# 字符串的比较
print('----------# 字符串的比较-------------')
str1 = 1
str2 = '1'
if str1 == str2:
print("相同")
else:
print("不相同")
if str(str1) == str2:
print("相同")
else:
print("不相同")
print('-------------------------------------')【代码说明】
第2行代码定义了1个数字类型的变量str1。
第3行代码定义了1个字符串类型的变量str2。
第4行代码比较str1和str2的值。由于str1和str2的类型不同,所以两者的内容也不相同。输出结果为“不相同”。
第8行代码,把数字型的变量str1转换为字符串类型,数字1被转换为字符串“1”。然后再与str2进行比较。输出结果为“相同”。
【运行结果】

如果要比较字符串中的一部分内容,可以先截取子串,再使用“==”操作符进行比较。如果要比较字符串的开头或结尾部分,更方便的方法是使用startswith()或endswith()函数。
startswith()的声明如下所示。
startswith(substring, [,start [,end]])
【代码说明】
参数substring是与源字符串开头部分比较的子串。
参数start表示开始比较的位置。
参数end表示比较结束的位置,即在start:end范围内搜索子串substring。
如果字符串以substring开头,则返回True;否则,返回False。
endswith()的参数和返回值类似startswith(),不同的是endswith()从源字符串的尾部开始搜索。
下面这段代码演示了startswith()和endswith()的使用。
# 比较字符串的开始和结束处
print('------# 比较字符串的开始和结束处---------')
word = 'hello world'
print('hello' == word[0:5])
print(word.startswith('hello'))
print(word.endswith('ld', 6))
print(word.endswith('ld', 6, 10))
print(word.endswith('ld', 6, len(word)))
print('-------------------------------------')【代码说明】
第3行代码先获取子串[0:5],再与“hello”进行比较。输出结果为“True”。
第4行代码调用startswith()。比较字符串变量word的开头部分“hello”。输出结果为“True”。
第5行代码,从字符串变量word的结尾到word[6]之间搜索子串“ld”。输出结果为“True”。
第6行代码,从“分片”word[6:10]中搜索子串“ld”。由于搜索的字符不包括位置10所在的字符,所以在word[6:10]中搜索不到子串“ld”。输出结果为“False”。
第7行代码,从“分片”word[6:len(word)]中搜索子串“ld”,len(word)的值为11。输出结果为“True”。
注意 startswith()、endswith()相当于分片[0:n],n是源字符串中最后一个索引。startswith()、endswith()不能用于比较源字符串中任意一部分的子串。
【运行结果】

字符串的反转
字符串反转是指把字符串中最后一个字符移到字符串第一个位置,按照倒序的方式依次前移。Java中使用StringBuffer类处理字符串,并通过循环对字符串进行反转。Python没有提供对字符串进行反转的函数,也没有类似charAt()这样的函数。但是可以使用列表和字符串索引来实现字符串的反转,并通过range()进行循环。
代码如下:
# 循环输出反转的字符串 def reverse(str): out = '' li = list(str) for i in range(len(li), 0, -1): out += ''.join(li[i-1]) return out
【代码说明】
第2行代码定义了一个函数reverse(),参数str表示需要反转的字符串。
第3行代码定义了一个返回变量out,用于存放字符串反转后的结果。
第4行代码创建了一个列表li,字符串str中的字符成为列表li的元素。
第5~6行代码从列表中的最后一个元素开始处理,依次连接到变量out中。
第7行代码返回变量out的值。
不难发现,Python的实现代码更简短,而且更容易理解。用户还可以通过列表的reverse()函数实现字符串的反转,实现的代码将进一步简化。
# 使用list 的 reverse() def reverse2(s): li = list(s) li.reverse() s = ''.join(li) return s
【代码说明】
第4行代码调用列表的reverse()实现了for…in…循环的功能。
第5行代码调用join()把反转后列表li的元素依次连接到变量s中。
Python的列表是对字符串进行处理的常用方式,灵活使用列表等内置数据结构处理字符串,能够简化编程的复杂度。利用序列的“切片”实现字符串的反转最为简洁,reverse()函数的主体只需要一行代码即可。
def reverse(s):
return s[::-1]
【代码说明】-1表示从字符串最后一个索引开始倒序排列。
ALL:
# 循环输出反转的字符串 def reverse(str): out = '' li = list(str) for i in range(len(li), 0, -1): out += ''.join(li[i-1]) return out
# 使用list 的 reverse() def reverse2(s): li = list(s) li.reverse() s = ''.join(li) return s
if __name__ == '__main__':
print('手动实现:输出反转字符串:%s' % reverse('abcdef'))
print('列表方法:输出反转字符串:%s' % reverse('ABCDEF'))
字符串的查找和替换
Java中字符串的查找使用函数indexOf(),返回源字符串中第1次出现目标子串的索引。如果需要从右往左查找可以使用函数lastIndexOf()。Python也提供了类似功能的函数,函数find()与indexOf()的作用相同,rfind()与lastIndexOf()的作用相同。find()的声明如下所示。find(substring [, start [ ,end]])
【代码说明】
参数substring表示待查找的子串。
参数start表示开始搜索的索引位置。
参数end表示结束搜索的索引位置,即在分片[start:end]中查找。
如果找到字符串substring,则返回substring在源字符串中第1次出现的索引。否则,返回-1。
rfind()的参数与find()相同,不同的是rfind()从字符串的尾部开始查找子串。
下面这段代码演示了find()、rfind()的使用:
# 查找字符串
sentence = "This is a apple."
print("find()方法实例:")
print(sentence.find("is", 3, 7))
print(sentence.find('a'))
print("rfind()方法实例:")
print(sentence.rfind('is', 3, 7))
print(sentence.rfind("a"))【代码说明】
第5行代码使用函数find(),从sentence的头部开始查找字符串“a”。输出结果为“8”。
第8行代码使用函数rfind(),从sentence的尾部开始查找字符串“a”。输出结果为“10”。
Java使用replaceFirst()、replaceAll()实现字符串的替换。replaceFirst()用于替换源字符串中第1次出现的子串,replaceAll()用于替换源字符串中所有出现的子串。这两个函数通过正则表达式来查找子串。而Python使用函数replace()实现字符串的替换,该函数可以指定替换的次数,相当于Java函数replaceFirst()和replaceAll()的合并。但是replace()不支持正则表达式的语法。
replace()的声明如下所示:
replace(old, new [, max])
【代码说明】
参数old表示将被替换的字符串。
参数new表示替换old的字符串。
参数max表示使用new替换old的次数。
函数返回一个新的字符串。如果子串old不在源字符串中,则函数返回源字符串的值。
下面这段代码演示了replace()的使用:
# 字符串的替换
print('replace()方法实例:')
string = 'hello world, hello china. I love china.'
print(string.replace('he', 'HE'))
print(string.replace('he', 'HE', 3))
print(string.replace('he', 'HE', 1))
print(string.replace('ABC', 'abc'))【代码说明】
第3行代码把sentence中的“hello”替换为“hi”。由于没有给出参数max的值,所以sentence中的“hello”都将被“hi”替换。
第4行代码,参数max的值为1,所以sentence中第1次出现的“hello”被“hi”替换,后面的出现的子串“hello”保持不变。
第5行代码,由于sentence中没有子串“abc”,所以替换失败。replace()返回sentence的值。
注意 replace()先创建变量sentence的拷贝,然后在拷贝中替换字符串,并不会改变变量sentence的内容。
字符串与日期的转换
在开发中,经常把日期类型转换为字符串类型使用。字符串与日期的转换是工作中频繁遇到的问题。Java提供了SimpleDateFormat类实现日期到字符串的转换。Python提供了time模块处理日期和时间。函数strftime()可以实现从时间到字符串的转换。strftime()的声明如下所示:
strftime(format[, tuple]) -> string
【代码说明】
参数format表示格式化日期的特殊字符。例如,“%Y-%m-%d”相当于Java中的“yyyy-MM-dd”。
参数tuple表示需要转换的时间,用元组存储。元组中的元素分别表示年、月、日、时、分、秒。
函数返回一个表示时间的字符串。
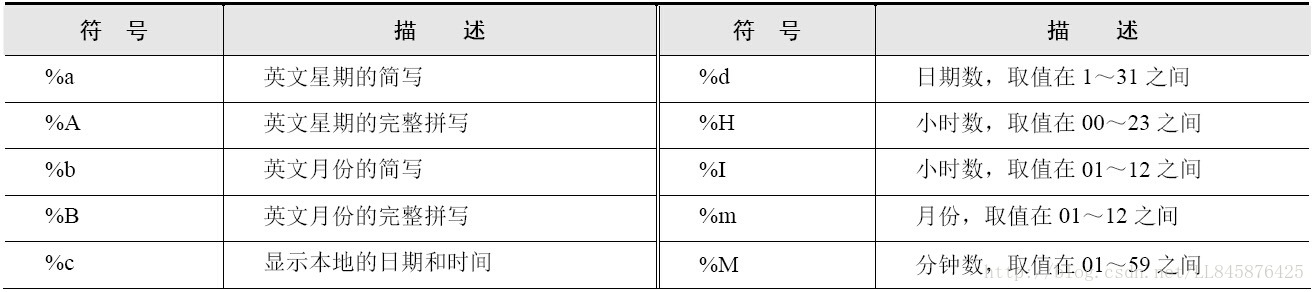
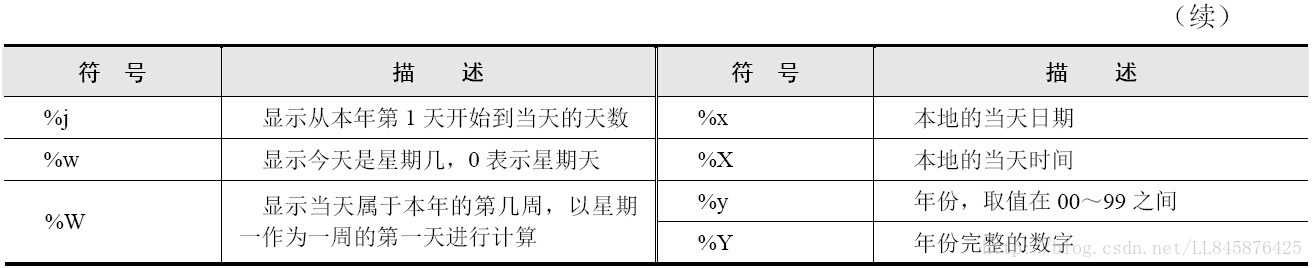
参数format格式化日期的常用标记如下所示:
字符串到时间的转换需要进行两次转换,需要使用time模块和datetime类,转换过程分为如下3个步骤。
1)调用函数strptime()把字符串转换为一个的元组,进行第1次转换。strptime()的声明如下所示。
strptime(string, format) -> struct_time
【代码说明】
参数string表示需要转换的字符串。
参数format表示日期时间的输出格式。
函数返回一个存放时间的元组。
2)把表示时间的元组赋值给表示年、月、日的3个变量。
3)把表示年、月、日的3个变量传递给函数datetime(),进行第2次转换。
datetime类的datetime()函数如下所示。
datetime(year, month, day[, hour[, minute[, second[, microsecond[,tzinfo]]]]])
【代码说明】
参数year、month、day分别表示年、月、日,这3个参数必不可少。
函数返回1个datetime类型的变量。
下面这段代码演示了时间到字符串、字符串到时间的转换过程:
import time
import datetime
# 时间到字符串的转换
print("----------时间到字符串的转换-----------")
print(time.strftime("%Y-%m-%d %X", time.localtime()))
# 字符串到时间的转换
print("----------字符串到时间的转换-----------")
t = time.strptime("2017-12-25", "%Y-%m-%d")
y,m,d = t[0:3]
print(datetime.datetime(y, m, d))【代码说明】
第4行代码中,函数localtime()返回当前的时间,strftime把当前的时间格式转化为字符串类型。
第6行代码,把字符串“2017-12-25”转换为一个元组返回。
第7行代码,把元组中前3个表示年、月、日的元素赋值给3个变量。
第8行代码,调用datetime()返回时间类型。
注意 格式化日期的特殊标记是区分大小写的,%Y与%y不相同。

相关文章推荐
- Python的字符串模板(Template)使用操作实例讲解
- Python3.6简单的操作Mysql数据库的三个实例
- python 3.6 +pyMysql 操作mysql数据库(实例讲解)
- python字符串内建函数操作实例源码讲解
- python字符串内建函数操作实例(cmp、str、enumerate、zip等)
- python中字符串定义、索引、切片、加号、星号操作实例
- Python字符串和字典相关操作的实例详解
- Python(字符串操作实例1)一个字符串用空格隔开
- Python 3.6 读取并操作文件内容的实例
- Python原始字符串操作符和Unicode操作符操作实例讲解源码
- Python 字符串(三)-字符串操作实例(string替换、删除、截取、复制、连接、比较、查找、包含、大小写转换、分割等)
- c#实例化继承类,必须对被继承类的程序集做引用 .net core Redis分布式缓存客户端实现逻辑分析及示例demo 数据库笔记之索引和事务 centos 7下安装python 3.6笔记 你大波哥~ C#开源框架(转载) JSON C# Class Generator ---由json字符串生成C#实体类的工具
- 慕课 python 操作数据库2 银行转账实例
- Python字符串操作
- 【Python语法笔记】字符串的操作
- python字符串操作
- mysql常用字符串操作函数大全,以及实例
- 使用python语言,比较两个字符串是否相同的实例
- python基础知识-字符串的通用操作 分类: python 2012-11-29 19:57 252人阅读 评论(0) 收藏
- [python]-字符串操作