(防坑笔记)hadoop3.0 (五) Hive的入门与数据类型
2018-01-03 16:32
351 查看
简单提提:
Hive是一个仓储结构的工具,能对hadoop中的文件以类 sql的方式查询出来,也可以让熟悉mapper/reduce的开发者进行自定义操作,单总归而言,它只是一个解析引擎,将HiveQL语句解析成job任务让hadoop执行操作;HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据
特别注意:包含 * 的查询,比如 select * from tbl 不会生成 MapRedcue 任务
数据类型
l 基本数据类型tinyint/smallint/int/bigint
float/double
boolean
string
ll 复杂数据类型
Array/Map/Struct
注意:没有date/datetime类型
metastore:(hive元数据的集中存放地)(一般不用默认的,而采用mysql,故这里不多提)
Hive metastore:①metastore默认使用内嵌的derby数据库作为存储引擎
②Derby引擎的缺点:一次只能打开一个会话
Mysql metastore:
使用Mysql作为外置存储引擎,多用户同时访问。
外置引擎安装准备:
前提: 在有hdfs部署的机上实践Mysql的安装可以参考: https://www.cnblogs.com/bookwed/p/5896619.html
将mysql加入开机启动
# chkconfig mysqld on
允许远程登录mysql
首先登录mysql数据,然后执行下面两行语句:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'itcast' WITH GRANT OPTION;
flush privileges;
metastore 的安装准备:
在usr 目录下创建了 hive ,进入,执行wget http://mirrors.shuosc.org/apache/hive/hive-2.3.2/apache-hive-2.3.2-bin.tar.gz[/code]tar -zxvf apache-hive-2.3.2-bin.tar.gz然后修改名字 成为hive
修改/etc/profile文件,将hive加入环境变量vim /etc/profileexport HIVE_HOME=/usr/hive/hive export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
Source 一下,让配置生效source /etc/profile
http://blog.csdn.net/zxz306418932/article/details/78726118 //hive2.3.2的具体配置方法
上传数据库驱动mysql-connector-java-5.1.45.jar到/usr/hive/hive/lib
修改$HIVE_HOME/conf/hive-site.xml
将一下配置加入到hive-site.xml 文件中开头(标签<value>中的内容自己定义,就是linux用户名)
1、<property> <name>system:java.io.tmpdir</name> <value>/home/apache-hive/tmpdir</value> </property> <property> <name>system:user.name</name> <value>root</value> </property>
2、
再次进入到hive目录中的conf文件中,配置hive-site.xml文件,利用vi编辑器中的搜索功能(Esc模式下输入 / ),分别找到
javax.jdo.option.ConnectionURL,
javax.jdo.option.ConnectionDriverName,
javax.jdo.option.ConnectionUserName,
javax.jdo.option.ConnectionPassword 这四项配置,其中这四项的<value>分别填:
<value>jdbc:mysql://192.168.88.129:3306/hive?characterEncoding=utf8&useSSL=false</value>,
<value>com.mysql.jdbc.Driver</value>,
<value>root</value>,
<value>root</value>。(注:这里的192.168.88.129是服务器的地址)
3、
进入hive目录的bin文件中使用 ./schematool -dbType mysql -initSchema 进行元数据库初始化
初始化完成后,使用./hive命令启动hive,出现hive>的时候,就可以使用了。
配置途中可能遇到的异常:
问题一:connection refuse 重启hadoop,包括格式化
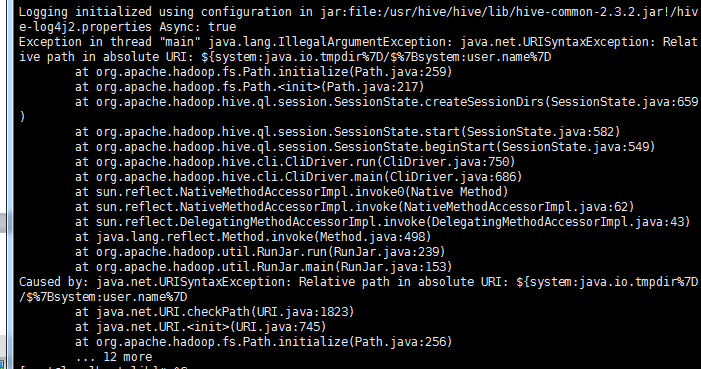
问题二:启动没问题,当进去的时候无论执行什么HiveQL语句都报如下错误
启动debug方式hive -hiveconf hive.root.logger=DEBUG,console测试配置
启动hive
# hive
创建数据库
hive> create database test_db;
显示所有数据库
show databases;
使用数据库test_db
hive> use test_db;
创建学生表
hive> create table student(id int,name string);
查看是否在HDFS中存有下面文件夹
http://192.168.88.129:50070/explorer.html#/user/hive/warehouse/test_db.db/student

相关文章推荐
- JAVA入门基础笔记-基本数据类型
- Python:入门笔记之list slices计算方法、匿名表达式、CGI、数据类型及应用领域
- python 入门学习笔记之基本语法与基本数据类型
- 【零基础入门学习Python笔记005】闲聊之Python的数据类型
- Hadoop记录——hive中的decimal字段,shell的数据类型以及sqoop导出空string报错
- hadoop组件---数据仓库(二)---hive的数据模型和数据类型
- 零基础入门-javaScript学习笔记之从基本数据类型学起
- (7)hadoop学习——hive的复杂数据类型
- Python入门学习笔记1(变量、运算符、数据类型I)
- 大数据学习笔记1--hadoop简介和入门
- Hadoop入门学习笔记_day01(大数据的相关概念 )
- ES学习笔记-elasticsearch-hadoop导入hive数据到es的实现探究
- Hadoop入门(八)自定义类型实例-统计手机流量数据Demo
- 大数据生态系统入门必看:pig、hive、hadoop、storm、mapreduce等白话诠释
- c#入门笔记(1)数据类型
- c++入门笔记(5)数据类型
- 大数据与Hadoop简单入门[学习笔记]
- 大数据笔记16:Hadoop入门
- Java入门基础之数据类型的转换、包箱、拆箱(附习题) 个人笔记
- Hadoop入门(七)之java对应的Hadoop数据类型及自定义类型序列化