Python3 爬虫(五) -- 单线程爬取某人CSDN全部博文
2018-01-03 15:23
495 查看
序
本文我实现的是一个CSDN博文爬虫,将某人csdn博客http://blog.csdn.net/fly_yr/article/list/1 中的全部博文基本信息抓取下来,每一页保存到一个文件中。先来看一下他的博客页面(与选择的主题有关系哦,不同主题网页样式与源码是不同的~):
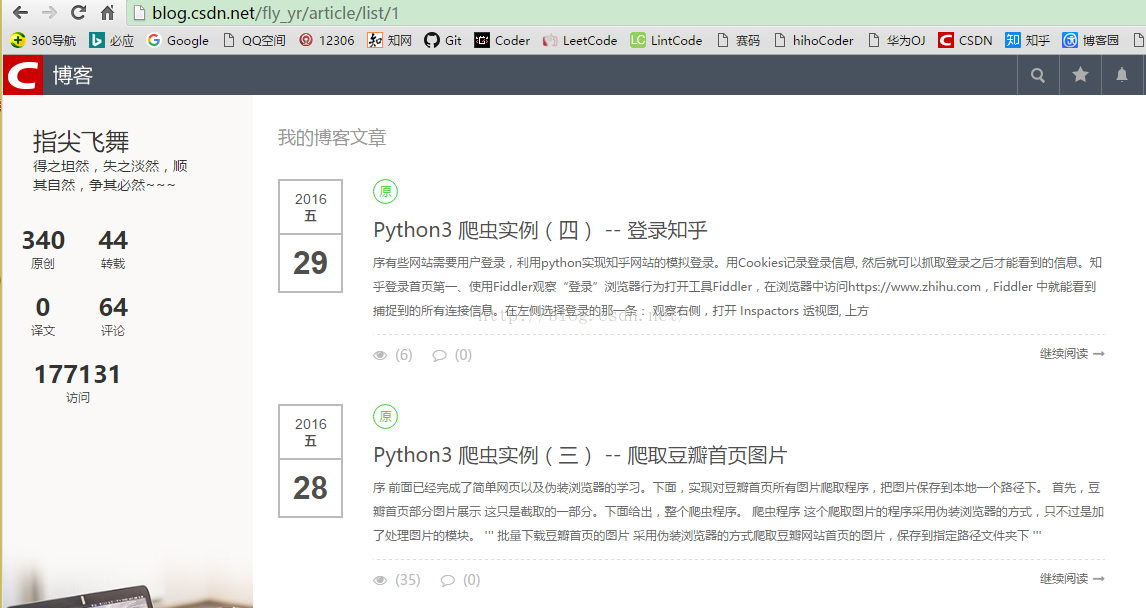
确定要提取的信息:
发表日期
是否原创标记
博文标题
博文链接
浏览量
评论量
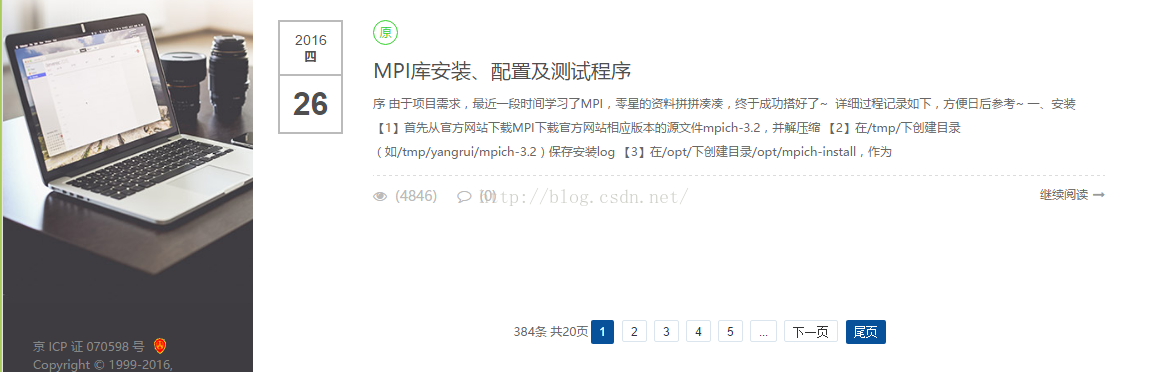
从上第二个图中可以看出,我的博文目前有20页共384条数据,我们要把所有的博文都爬取下来,就要先获取总页数。
1. 确认URL
首先,我们确认好要爬取页面的url="http://blog.csdn.net/fly_yr/article/list/1";然后,利用Fiddler工具查看访问csdn网站所需的报头:
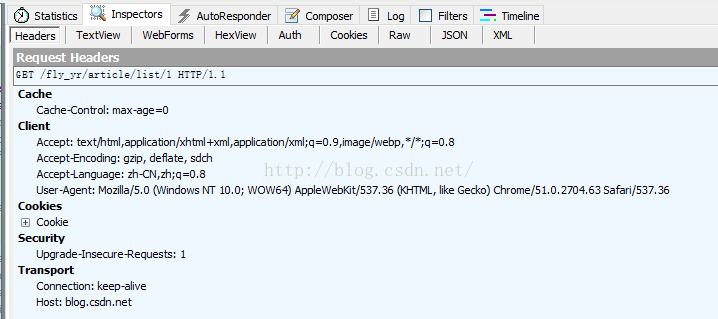
即:
[python] view
plain copy
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8",
"Host": "blog.csdn.net"
}
最后,我们需要构造正则表达式,提取所需要的信息,下节详述。
2.分析网页源码
确认好了要抓取的信息,下面查看该网页源码(在当前网页点击右键查看源代码),构造正则表达式:
2.1 提取页数:

在当前网页源码中找到上图所示的部分,构造正则表达式:
pages = r'<div.*?pagelist">.*?<span>.*?共(.*?)页</span>'
此处,对正则表达式做简要说明:
1).*? 是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配。
2)(.*?)代表一个分组,在这个正则表达式中我们匹配了1个分组,在后面的遍历item中,item[0]就代表第一个(.*?)所指代的内容,item[1]就代表第二个(.*?)所指代的内容,以此类推。
3)re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
2.2 提取博文信息
同理找到,关于每个博文的网页源码:
我们发现,每个博文都是有上图代码段来定义的,以<dl class="list_c clearfix">开始,到</dl>结束,我们为
发表日期
是否原创标记
博文标题
博文链接
浏览量
评论量
设计正则表达式:
[python] view
plain copy
str = r'<dl.*?list_c clearfix">.*?date_t"><span>(.*?)</span><em>(.*?)</em>.*?date_b">(.*?)</div>.*?'+\
r'<a.*?set_old">(.*?)</a>.*?<h3.*?list_c_t"><a href="(.*?)">(.*?)</a></h3>.*?'+\
r'<div.*?fa fa-eye"></i><span>(.∗?)</span>.*?fa-comment-o"></i><span>(.∗?)</span></div>'
3 爬虫完整源代码
此处,我们使用面向对象模式,引入类与方法,封装一个CSDN博客爬虫类,对代码进行优化,完整代码如下:[python] view
plain copy
'''''
program: csdn博客爬虫
function: 实现对我的csdn主页所有博文的日期、主题、访问量、评论个数信息爬取
version: python 3.5.1
time: 2016/05/29
author: yr
'''
import urllib.request,re,time,random,gzip
#定义保存文件函数
def saveFile(data,i):
path = "E:\\projects\\Spider\\05_csdn\\papers\\paper_"+str(i+1)+".txt"
file = open(path,'wb')
page = '当前页:'+str(i+1)+'\n'
file.write(page.encode('gbk'))
#将博文信息写入文件(以utf-8保存的文件声明为gbk)
for d in data:
d = str(d)+'\n'
file.write(d.encode('gbk'))
file.close()
#解压缩数据
def ungzip(data):
try:
#print("正在解压缩...")
data = gzip.decompress(data)
#print("解压完毕...")
except:
print("未经压缩,无需解压...")
return data
#CSDN爬虫类
class CSDNSpider:
def __init__(self,pageIdx=1,url="http://blog.csdn.net/fly_yr/article/list/1"):
#默认当前页
self.pageIdx = pageIdx
self.url = url[0:url.rfind('/') + 1] + str(pageIdx)
self.headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/51.0.2704.63 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8",
"Host": "blog.csdn.net"
}
#求总页数
def getPages(self):
req = urllib.request.Request(url=self.url, headers=self.headers)
res = urllib.request.urlopen(req)
# 从我的csdn博客主页抓取的内容是压缩后的内容,先解压缩
data = res.read()
data = ungzip(data)
data = data.decode('utf-8')
pages = r'<div.*?pagelist">.*?<span>.*?共(.*?)页</span>'
#link = r'<div.*?pagelist">.*?<a.*?href="(.*?)".*?</a>'
# 计算我的博文总页数
pattern = re.compile(pages, re.DOTALL)
pagesNum = re.findall(pattern, data)[0]
return pagesNum
#设置要抓取的博文页面
def setPage(self,idx):
self.url = self.url[0:self.url.rfind('/')+1]+str(idx)
#读取博文信息
def readData(self):
ret=[]
str = r'<dl.*?list_c clearfix">.*?date_t"><span>(.*?)</span><em>(.*?)</em>.*?date_b">(.*?)</div>.*?'+\
r'<a.*?set_old">(.*?)</a>.*?<h3.*?list_c_t"><a href="(.*?)">(.*?)</a></h3>.*?'+\
r'<div.*?fa fa-eye"></i><span>(.∗?)</span>.*?fa-comment-o"></i><span>(.∗?)</span></div>'
req = urllib.request.Request(url=self.url, headers=self.headers)
res = urllib.request.urlopen(req)
# 从我的csdn博客主页抓取的内容是压缩后的内容,先解压缩
data = res.read()
data = ungzip(data)
data = data.decode('utf-8')
pattern = re.compile(str,re.DOTALL)
items = re.findall(pattern,data)
for item in items:
ret.append(item[0]+'年'+item[1]+'月'+item[2]+'日'+'\t'+item[3]+'\n标题:'+item[5]
+'\n链接:http://blog.csdn.net'+item[4]
+'\n'+'阅读:'+item[6]+'\t评论:'+item[7]+'\n')
return ret
#定义爬虫对象
cs = CSDNSpider()
#求取
pagesNum = int(cs.getPages())
print("博文总页数: ",pagesNum)
for idx in range(pagesNum):
cs.setPage(idx)
print("当前页:",idx+1)
#读取当前页的所有博文,结果为list类型
papers = cs.readData()
saveFile(papers,idx)
需要注意的问题:
我们从CSDN上直接读取的数据是经过压缩后的,所以对数据先解压缩,然后采用“utf-8”格式解码;
通过正则表达式提取后的数据是list类型,对其处理把每条记录转换为str类型;
写入文件时必须再采用“gbk”格式进行编码,否则,写入文件会出错;
运行结果:
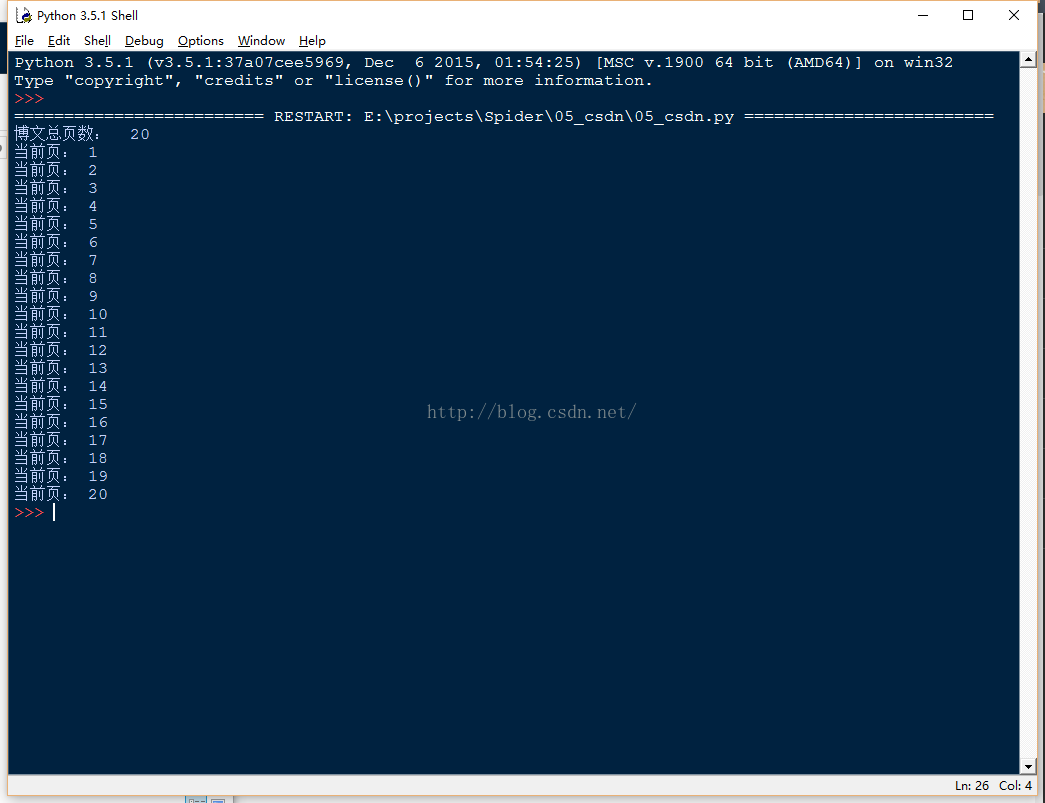
文件列表:
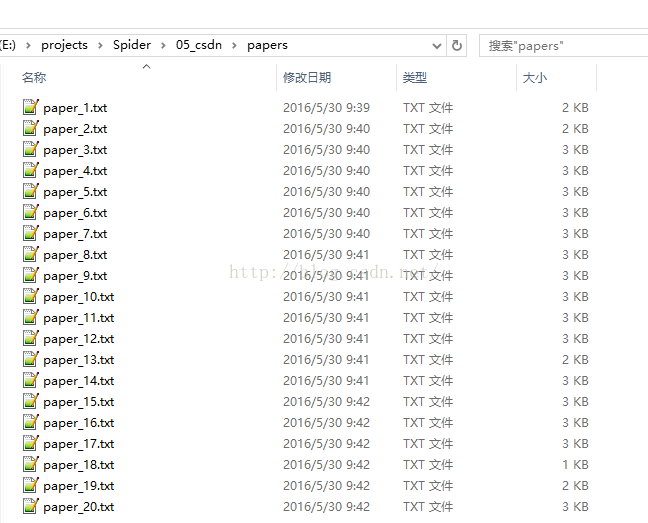
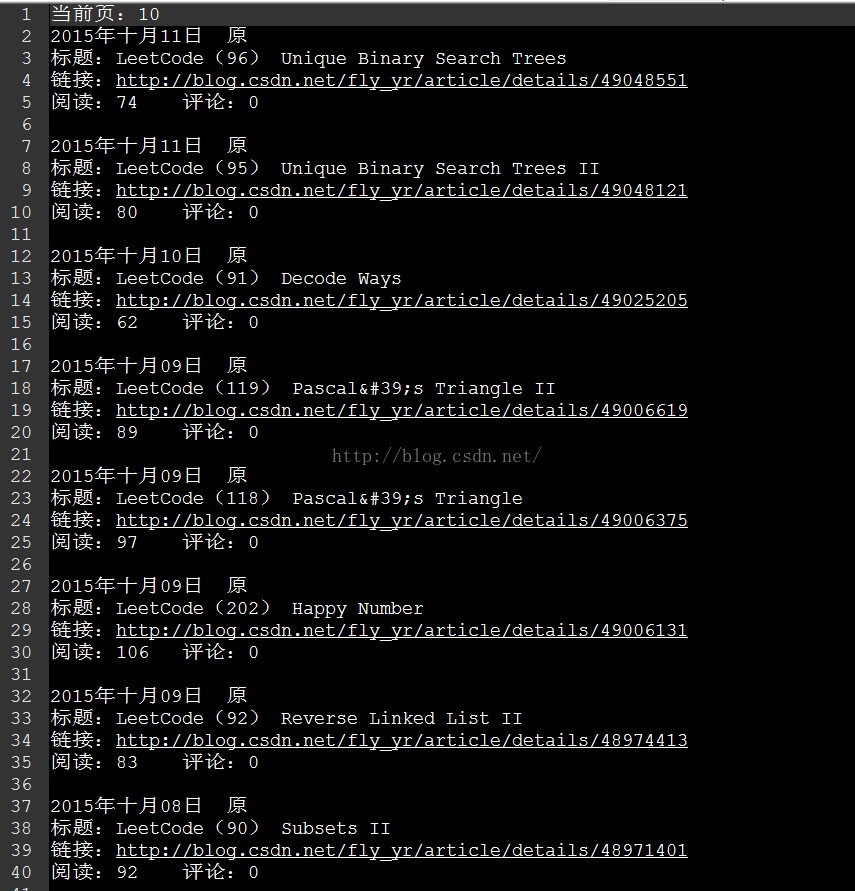
选取其中一个文件paper_10,查看内容:
GitHub源码链接

相关文章推荐
- Python2 爬虫(三) -- 爬CSDN全部博文(自动获取页数)
- Python2 爬虫(九) -- Scrapy & BeautifulSoup之再爬CSDN博文
- python 爬虫 CSDN博客下载-改进版
- python爬虫爬取csdn
- python爬虫之csdn刷博客访问量
- python抓取CSDN博客首页的所有博文,对标题分词存入mongodb中
- Hello Python!用python写一个抓取CSDN博客文章的简单爬虫
- Python爬虫(4)——获取CSDN链接
- python爬虫爬取csdn博客专家所有博客内容
- Python爬虫之抓取豆瓣信息 全部网页显示
- 模拟登陆CSDN -- Python爬虫练习之正则表达式和cookie
- python爬虫之python2.7.8抓取csdn博客文章
- python+beautifulsoup/xpath爬取新浪微博某用户的全部原创博文,分词后用Tagxedo制作成美丽的标签云
- Web Scraping with Python:使用 Python 导出 CSDN 博客全部文章(保留样式)和附带图片
- Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
- 结构之法算法之道CSDN博客-第一、二期全部博文集锦[CHM 文件下载]
- Python爬虫_用Python爬取csdn页面信息目录
- 实现一个go语言的简单爬虫来爬取CSDN博文(一)
- Python爬虫练习:爬取csdn极客的更新文章
- Python爬虫——模拟登陆爬取csdn页面