Mysql的select in会自动过滤重复的数据
2018-01-03 00:36
405 查看
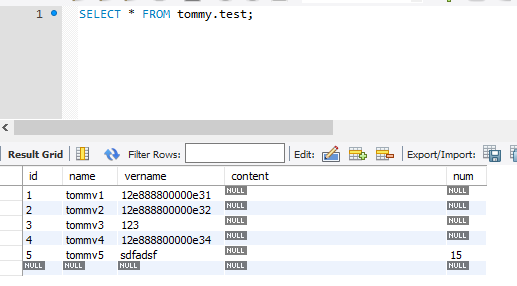
默认使用 SELECT 语句;
当加上in范围后,结果如下图:
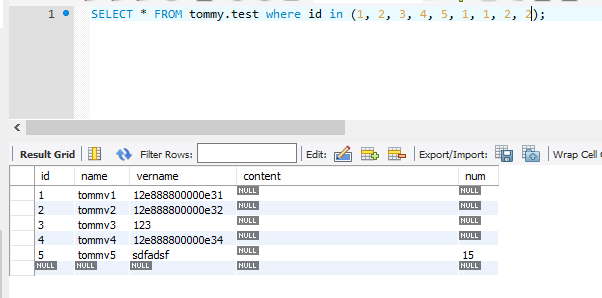
in范围内的数据,如果有重复的,只会选择第一个数据。
所以如果不是直接使用SQL语句来查询,而是在代码中来查询时,记得使用 distinct 关键字
如:
其实是相当于:
因为table2中的id可能会存在重复的情况。
当加上in范围后,结果如下图:
in范围内的数据,如果有重复的,只会选择第一个数据。
所以如果不是直接使用SQL语句来查询,而是在代码中来查询时,记得使用 distinct 关键字
如:
select id, name from table1 where ref_id in ( select id from table2 )
其实是相当于:
select id, name from table1 where ref_id in ( select distinct id from table2 )
因为table2中的id可能会存在重复的情况。

相关文章推荐
- Mybatis+Oracle批量插入(自动过滤重复数据)与删除
- MySQL 查询过滤重复数据
- mysql 重复数据,求和过滤的处理
- MYSQL远程服务器自动备份数据到本机
- MySQL Help 答朋友问:5000W记录的Innodb表如何快速的去重复数据
- MySQL语句删除数据库重复记录数据行
- MySQL对于有大量重复数据表的处理方法
- MYSql 清楚重复数据
- ligerui下拉框自动完成,解决源码无法使用本地数据过滤
- MySQL: ON DUPLICATE KEY UPDATE 用法 避免重复插入数据
- centos7下mysqldump+crontab自动备份数据库
- mysql 数据表中查找重复记录
- mysql恢复删除的数据库和自动备份数据
- mysql 删除单表内多个字段重复的数据
- mysql 删除重复数据只保留一条
- C# DataTable 过滤重复数据
- mysql避免插入重复数据
- mysql 删除重复数据
- mysql的小插件.让mysql的数据自动更新到redis去--转
- Mysql 如何删除数据表中的重复数据!